







之前我在博客里介绍过牛顿-拉弗逊迭代法,对数据挖掘技术熟悉的同学应该还知道有梯度下降法(其实也是一种迭代算法)。今天刚好有朋友和我讨论泊松图像融合算法,我说我过去文章里给出的是最原始、最直观的实现算法。对于理解泊松融合的原理比较有帮助,但是效率可能并不理想。印象中,泊松融合是有一个以矩阵为基础的快速算法的。但是过去我浅尝辄止了,也没深究,今天刚好再提到,小看了一下,似乎涉及高斯-塞德尔迭代法。好吧,博主君暂且把知道的这部分内容做个介绍吧。特别说明:以下内容主要取材自《数值方法(MATLAB版)(第四版)》马修斯等著,电子工业出版社2010年出版发行。
一、雅各比迭代法
考虑如下方程组:
上述方程可表示成如下形式:
这样就提出了下列雅可比迭代过程:
如果从 P0=(x0,y0,z0)=(1,2,2) 开始,则上式中的迭代将收敛到解 (2,4,3) 。
将
x0=1,y0=2
和
z0=2
代入上式中每个方程的右边,即可得到如下新值:
新的点 P1=(1.75,3.375,3.00) 比 P1 更接近 (2,4,3) 。使用迭代过程(3)生成点的序列{ P0 }将收敛到解 (2,4,3) 。
这个过程称为雅可比迭代,可用来求解某些类型的线性方程组。从上表中可以看出,经过19步选代,选代过程收敛到一个精度为9 位有效数字的近似值(2.00000000, 4.00000000, 3.00000000)。但有时雅可比迭代法是无效的。通过下面的例子可以看出,重新排列初始线性方程组后,应用雅可比迭代法可能会产生一个发散的点的序列。
设重新排列的线性方程组如下:
这些方程可以表示为如下形式:
这可以用如下雅可比迭代过程求解:
如果从 P0=(x0,y0,z0)=(1,2,2) 开始,则上式中的迭代将对解 (2,4,3) 发散。将 x0=1 , y0=2 和 z0=2 带入上式中每个方程的右边,即可得到新值 x1 , y1 和 z1 :
新的点 P1=(−1.5,3.375,5.00) 比 P0 更远地偏离 (2,4,3) 。使用上述迭代过程生成点的序列是发散的。
二、高斯-塞德尔迭代法
有时候通过其他方面可以加快迭代的收敛速度。观察由雅可比迭代过程(3)产生的三个序列{ xk },{ yk }和{ zk },它们分别收敛到2,4和3。由于 xk+1 被认为是比 xk 更好的 x 之近似值,所以在计算 yk+1 时用 xk+1 来替换 xk 是合理的。同理,可用 xk+1 和 yk+1 计算 zk+1 。下面的例子演示了对上述例子中给出的方程组使用上述方法的情况。
设给定上述线性方程组并利用高斯-塞德尔(Gauss-Seidel)迭代过程求解:
如果从
P0=(x0,y0,z0)=(1,2,2)
开始,用上式中的迭代可收敛到解
(2,4,3)
。
将
y0=2
和
z0=2
代入上式第一个方程可得
将 x1=1.75 和 z0=2 代入第二个方程可得
将 x1=1.75 和 y1=3.75 代入第三个方程可得
新的点
P1=(1.75,3.75,2.95)
比
P0
更接近解
(2,4,3)
,而且比之前例子中的值更好。用迭
代(7)生成序列{
Pk
收敛到
(2,4,3)
。
正如前面讨论的,应用雅各比迭代法计算有时可能是发散的。所以有必要建立一些判定条件来判断雅可比迭代是否收敛。在给出这个条件之前,先来看看严格对角占优矩阵的定义。
设有
N
×
N
维矩阵
A
,如果
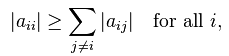
其中,
i
是行号,
j
是列号,则称该矩阵是严格对角占优矩阵。显然,严格对角占优的意思就是指对角线上元素的绝对值不小于所在行其他元素的绝对值和。
设第k点为 Pk=(x(k)1,x(k)2,...,x(k)j,...,x(k)N,) ,则下一点为 Pk+1=(x(k+1)1,x(k+1)2,...,x(k+1)j,...,x(k+1)N,) 。向量 Pk 的上标 (k) 可用来标识属于这一点的坐标。迭代公式根据前面的值 (x(k)1,x(k)2,...,x(k)j,...,x(k)N,) ,使用上述线性方程组中第 j 行求解 x(k+1)j 。
雅可比迭代:
其中
j=1,2,...,N
。
雅可比迭代使用所有旧坐标来生成所有新坐标,而高斯-塞德尔迭代尽可能使用新坐标得到更新的坐标。
高斯-塞德尔迭代:
其中 j=1,2,...,N 。
下面的定理给出了雅可比迭代收敛的充分条件。
(雅可比选代) 设矩阵
A
具有严格对角优势,则
AX=B
有惟一解
X=P
。利用前面给出的迭代式可产生一个向量序列{
Pk
},而且对于任意初始向量
P0
,向量序列都将收敛到
P
。
当矩阵 A 具有严格对角优势时,可证明高斯-塞德尔迭代法也会收敛。在大多数情况下,高斯-塞德尔迭代法比雅可比迭代法收敛得更快,因此通常会利用高斯-塞德尔迭代法。但在某些情况下,雅可比迭代会收敛,而高斯-塞德尔迭代不会收敛。
转载地址:http://blog.csdn.net/baimafujinji/article/details/50582462(如有侵权,联系我,我会及时撤掉)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









