







今天博主是做一个大概的概述,缺少的章节会在后面慢慢补充,感兴趣的同学可以在下面评论留言。
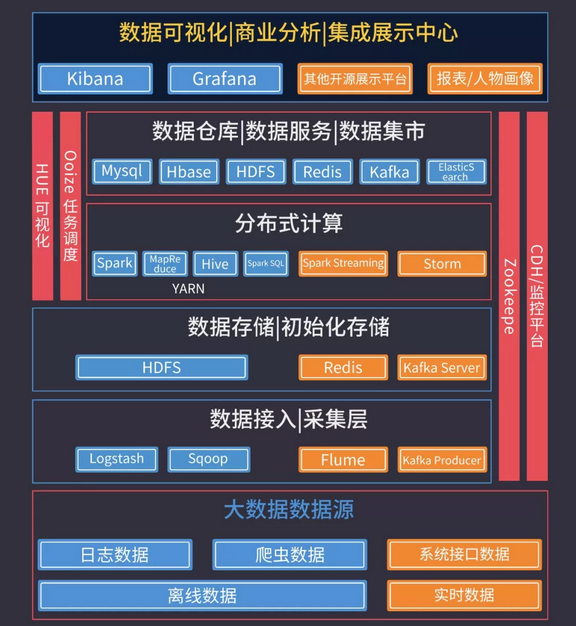
数据可视化展示中心:
KIbana官网:点击打开链接
用户指南:点击打开链接
Grafana官网:点击打开链接
Grafana帮助文档:点击打开链接
大数据特征:
1)大量化(Volume):存储量大,增量大 TB->PB
2)多样化(Variety):
来源多:搜索引擎,社交网络,通话记录,传感器
格式多:(非)结构化数据,文本、日志、视频、图片、地理位置等
3)快速化(Velocity):海量数据的处理需求不再局限在离线计算当中
4)价值密度低(Value):但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来
大数据带来的革命性变革:
1)成本降低
2)软件容错,硬件故障视为常态
3)简化分布式并行计算
数据分析师的必备技能:
数据采集:所谓数据采集并不是我们理解的数据爬虫,尤其是我们在工作中遇到的数据很多都是来自系统内的数据,来自数据库的数据来自日志的数据。但是这些数据维度是非常多并且复杂的,所以在分析前我们就需要把这些数据采集来。数据采集常用的手段有:SQL/Python,其中SQL是数据分析的必备技能,Python是加分项。
数据清洗:采集来的数据一般是不规整的,字段缺失或者有错误是常有的事情,如果我们不对这些数据进行清洗,分析出的结果就会出现各种异常。在数据清洗这一块就需要用到一些简单的统计学基础。
数据分析:数据分析最重要的是行业知识和逻辑思维能力。行业知识往往是通过在行业中的工作经历来获取的,当然作为学生也可以通过一些行业相关的数据报告和杂志来获得。而逻辑思维能力,需要后天的不断的锻炼,常见的锻炼方法是多看数据分析实战相关的书籍,学习作者的思维方式;经常和小伙伴一起做头脑风暴;对于一些工作生活中有趣的经验主义的事情尝试通过数据角度去解答。
数据可视化:让结论更加的容易理解。目前国内外的数据可视化的产品也非常多,常用的有:Echarts/Tableau/Excel/Python等
为了应对大数据的这几个特点,开源的大数据框架越来越多,先列举一些常见的:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron、
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









