







requests模块自行搜索办法下载。他是爬虫神器。
要爬取先要知道它的网址url
url='https://www.baidu.com'
然后发送请求,但是请求有很多种,我们得知道我们爬取的网页它吃哪一种。这个时候就用得上我上一篇博客里记载的浏览器工具了。
因为我们是向百度发送请求,所以在百度页面按F12
Network->All->Headers

可以看到百度吃的请求是GET类型的
import requests
# 爬百度的信息
url='https://www.baidu.com'
#发送请求
resp=requests.get(url)
print(resp)
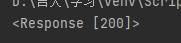
发送请求,得到一个回响resp,但是resp不是源代码,而是一个响应对象,这是因为响应对象包括了其它东西加上源代码,为了得到纯粹的源代码,还得进行下一步操作。即resp.text,print会发现有乱码
一旦发现有乱码,就去找print(resp.text)里的第一行charset,比如这个百度它的就是utf-8,因此,我们在拿源代码之前还得设置字符集。
import requests
# 爬百度的信息
url='https://www.baidu.com'
#发送请求
resp=requests.get(url)
#设置字符集
resp.encoding='utf-8'
print(resp.text)

接下来,我们把页面源代码写入文件
import requests
# 爬百度的信息
url='https://www.baidu.com'
#发送请求
resp=requests.get(url)
#设置字符集
resp.encoding='utf-8'
print(resp.text)
with open("mybaidu.html","w",encoding='utf-8') as f:#代码是html代码,所以存的时候也是html
f.write(resp.text)
打开mybaidu.html运行一下,点击鼠标移动到代码就出现的图标,搜狗或其它浏览器都行。
运行成功

和原来的百度不一样,因为还只发送了一次请求.
















 6028
6028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









