







深度学习之图像处理与分析(二)
目录
- 反向传播
- 卷积神经网络
- 过度拟合
- 总结与讨论
连锁规则
- 神经网络中的每一层都接受上一层功能的输出,并将其用作其功能的输入
- 链规则用于计算“函数的梯度”
- 神经网络由许多张量运算链接在一起组成,例如 h(x)= g(f(x))

反向传播
- 反向传播是一种朝着方向(梯度)更新权重的方法,可以在给定标记观察值的情况下最小化预定义的损失函数
- 应用链规则计算神经网络的梯度值
- 从最终损失函数开始,然后从顶层(输出层)向底层(输入层)反向运行
- 通过迭代应用链式规则来重用先前从后续层计算的梯度,以更新权重,从而计算任意层的梯度
反向传播步骤
- 网络权重初始化
- 正向传播
- 计算总损失
- 向后传播
正向传播
- 目标是将输入X转发到网络的每一层,直到计算输出层h2中的分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DbNBJFR9-1608799542929)(278963464F05480BB7FF551C9046151C)]](https://img-blog.csdnimg.cn/20201224164630247.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hlamlhaGFvXw==,size_16,color_FFFFFF,t_70)
反向传播示例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RGhxSfWR-1608799542931)(0B0F65889F3845F58417575674458385)]](https://img-blog.csdnimg.cn/20201224164655532.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hlamlhaGFvXw==,size_16,color_FFFFFF,t_70)
卷积神经网络
- CNN进行卷积运算,从本地输入中提取特征,从而实现表示模块性和数据效率
- CNN将卷积层和池层链接在一起,以帮助对输入样本进行降采样,并且直到最后一层才使用FC层以获得最终的输出分类。
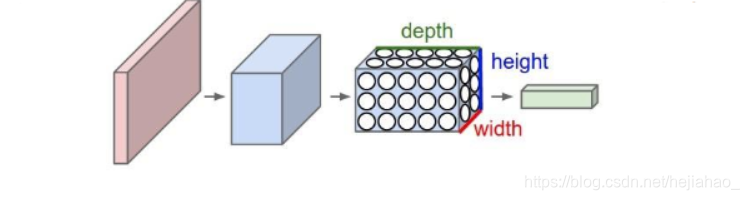
什么是卷积?
- 卷积是图像处理中的基本构建块
- 卷积是滤镜和滤镜覆盖输入图像区域之间的逐元素矩阵乘法
- 卷积层中的神经元仅连接到该层之前的一小部分区域,而不是以完全连接的方式连接所有神经元
为什么要卷积?
- 卷积后,源像素将替换为其自身与附近像素的加权和。
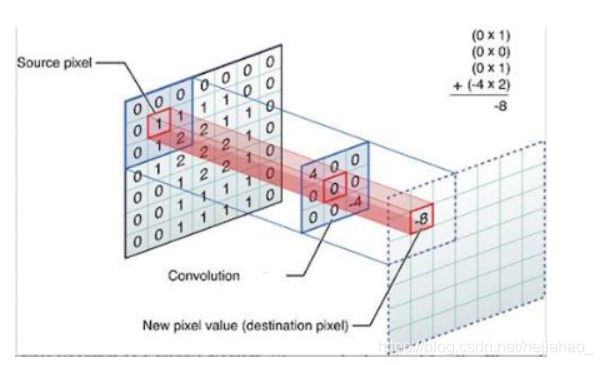
Filters(过滤器)
- 过滤器/内核用于应用流程功能来检测特征或模式
- 每个常规层都应用一组不同的过滤器。 在训练期间,CNN会自动学习这些过滤器的权重,这些权重是随机初始化的
- 滤镜是一个微小的矩阵,可从左到右和从上到下滑动到较大的图像上
- 大多数过滤器都是平方矩阵,请使用奇数内核大小(3,5,7)来确保图像中心处的有效整数坐标
过滤深度
- 对于CNN的图像输入,深度是通道数
- 对于在CNN中更深的体积,深度是在上一层应用的过滤数量
- 每个过滤器将产生一个单独的2D特征图,当输入中不同位置的特征存在时激活
滑动和步
- 一个小的矩阵在图像上从左到右和从上到下滑动,并在图像的每个坐标上应用卷积
- 两个连续的窗口之间的距离称为步幅
- 较小的步幅(1或2)将导致重叠的接收场和较大的输出量
- 相反,更大的步幅将导致较少的重叠接收场和较小的输出量
卷积演示
- 对于每个特征图,每个神经元仅连接到输入体积的一小部分,并共享相同的连接权重(过滤器/内核)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BMW6ynjr-1608799542935)(29FAD656D0D84DBEB3C502602502BAAD)]](https://img-blog.csdnimg.cn/20201224164732946.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hlamlhaGFvXw==,size_16,color_FFFFFF,t_70)
零填充
- 有时,我们想保留有关原始输入量的尽可能多的信息,以便提取那些低级特征。
- 可以通过在边框周围填充0的输入图像/功能图来抵消边框效果
- 有时,我们希望输出体积与输入体积保持相同的空间尺寸
步与填充
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5j8gBADE-1608799542936)(E7B3A686D7694384B3C83D325561836F)]](https://img-blog.csdnimg.cn/20201224164740799.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2hlamlhaGFvXw==,size_16,color_FFFFFF,t_70)
转换层输出
- 激活图(功能图),可以查看输入如何分解为不同的过滤器。 每个通道编码相对独立的特征
- 沿深度尺寸堆叠特征图并产生输出量
- CONV层可用于通过更改过滤器的步幅来减小输入体积的空间尺寸
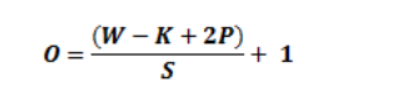
实例探究
- 为MNIST设计的LeNet-5体系结构(1998)
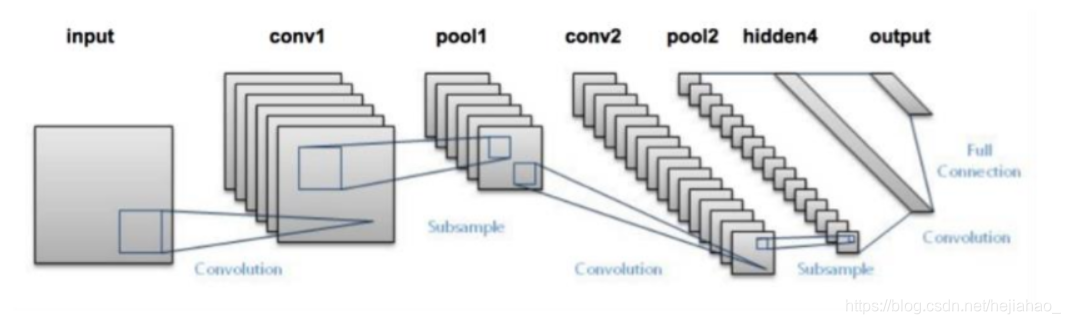
图层类型
- 全连接层-FC
- 卷积层-CONV
- 池层-POOL
- 降落层-DO
卷积层
- CONV图层参数由一组K个可学习的滤镜组成,其中每个滤镜具有一个宽度和一个高度,并且始终为正方形
- 这些过滤器很小,但会扩展到整个体积的整个深度
- 当网络在输入体积的给定空间位置看到特定类型的特征时,网络会学习激活的过滤器
为什么不在CNN中使用FC?
- FC层将当前层中的神经元与上一层中的所有神经元相连,从而产生过多的权重,因此无法在较大的空间维度上训练深层网络
- 相反,CNN选择将每个神经元仅连接到上一层的局部区域, 这称为神经元的接受域。 这种本地连接可在CNN中保存大量参数
池层
-
定期在CNN的连续Conv层之间插入池化层
-
通过用一个数字表示每个2x2块,它允许平移不变,可以检测到该特征并导致相同的输出
-
O =(W-k)/ s + 1
-
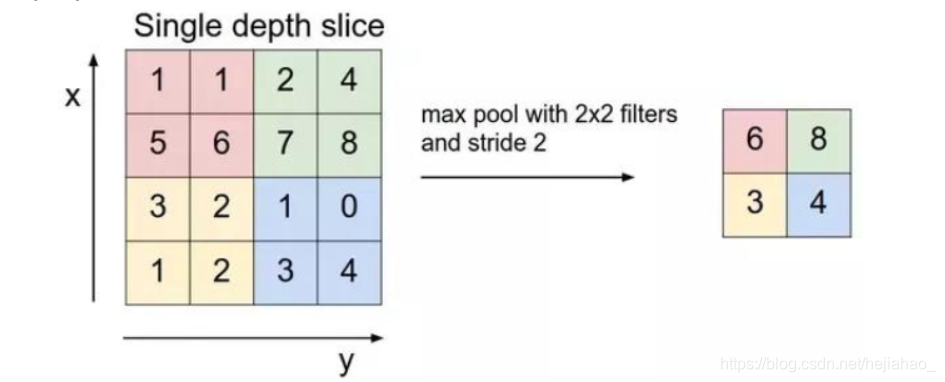
-
参数或权重的数量减少了75%,从而减少了计算成本,并控制了过度拟合
-
在网络中间进行了最大池化以减小空间大小,并缓慢剥离空间关系以创建平移不变性
-
平均池通常用作网络的最后一层,以避免完全使用FC层
ReLU函数
- 整流线性单位(2010):
- 将负值清零。 广泛用于CNN
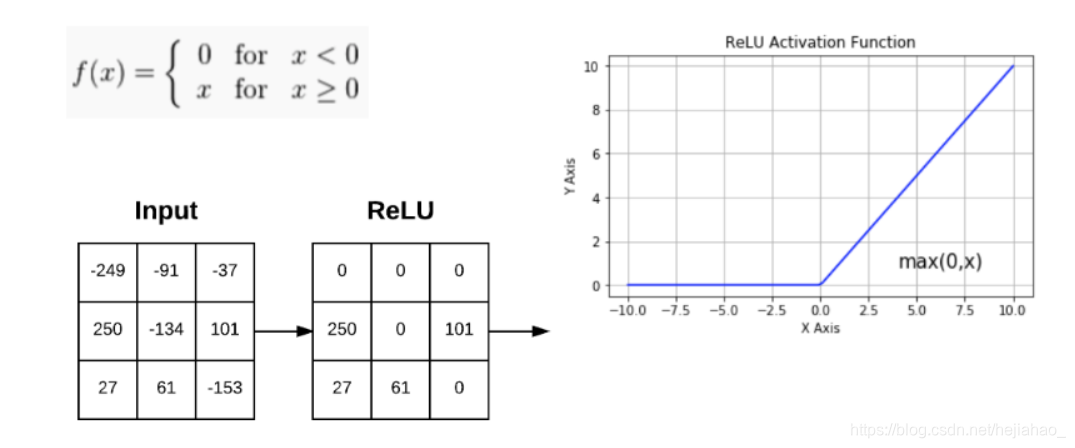
- 将负值清零。 广泛用于CNN
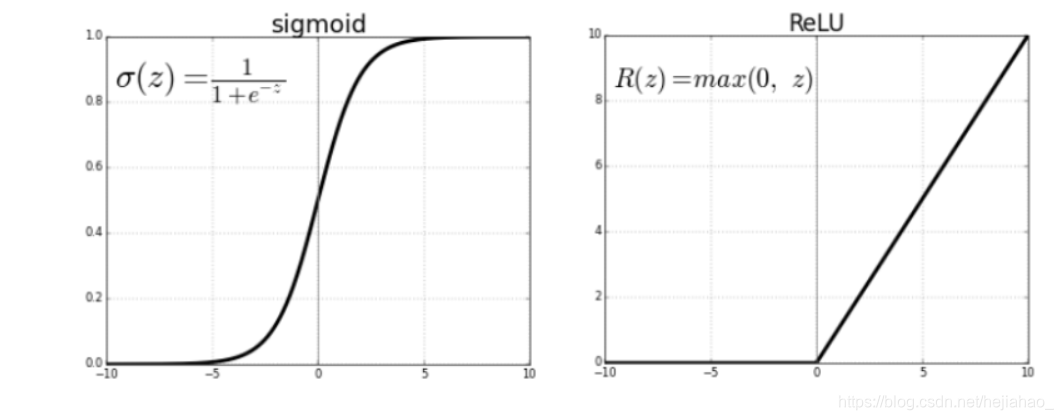
Sigmoid vs. ReLU
- Sigmoid 压扁介于0和1之间的所有值,神经元输出和梯度会完全消失
- 由于计算效率高,ReLU训练速度更快,并缓解了梯度消失的问题
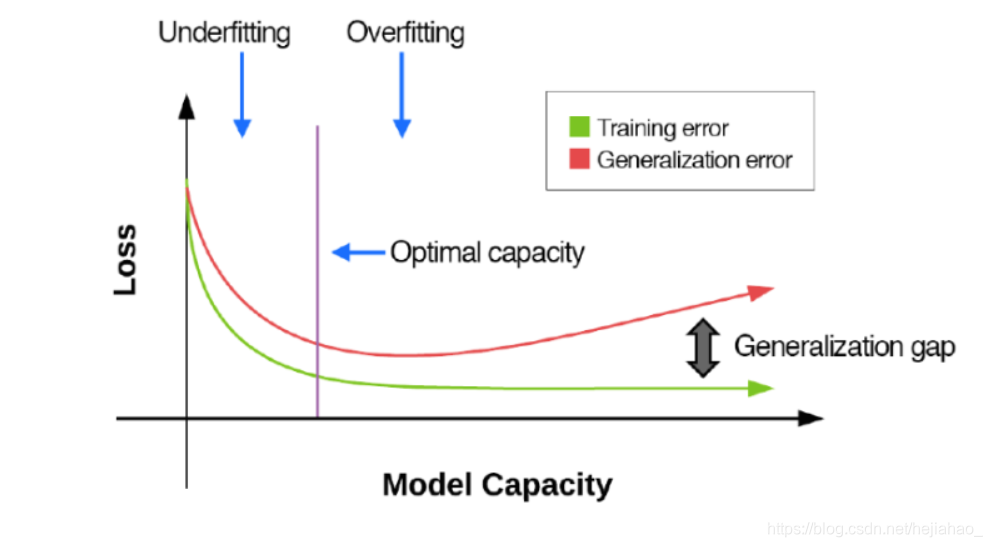
拟合不足与拟合过度
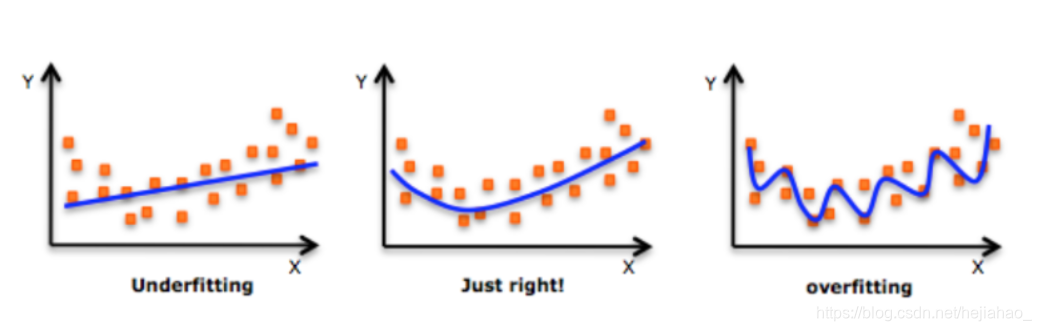
过度拟合
- 当训练与验证损失之间的差距过大时,就会发生过度拟合
- 表示网络对训练数据中的基础模式进行了过于强大的建模,而对于从未见过的验证数据而言,效果并不理想。
- 只要损失之间存在差距 培训和验证之间的差距不会显着增加,过拟合水平是可以接受的
过度拟合的解决方案
- 添加更多训练数据
- 减少模型的容量
- 下降层
损耗与模型容量
- 随着模型容量的增加,训练和验证损失/准确性开始彼此不同
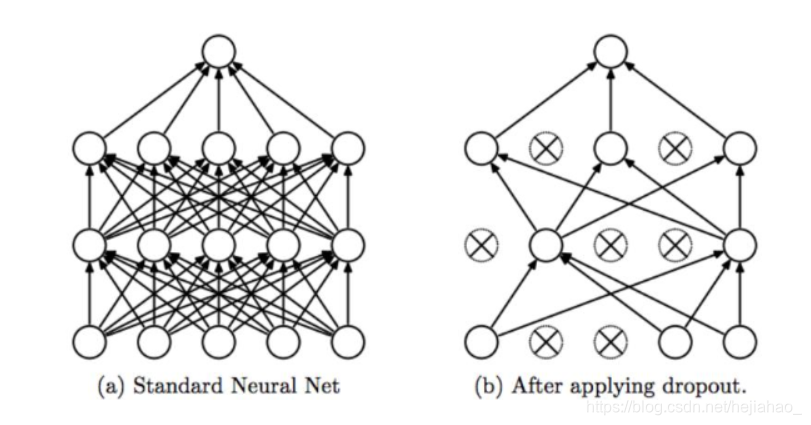
Dropout Layers(辍学层)
-
丢失层随机断开网络中前一层到下一层的输入
-
在为当前微型批次计算前进/后退通过之后,为下一个微型批次重新连接断开的连接
-
Dropout(2014)通过仅在训练时显式更改网络架构来减少过度拟合
-
随机丢弃可确保在以给定模式呈现时,网络中没有任何一个单元负责“激活”
-
相反,多个单元 当输入相似的输入时将激活,以训练模型进行概括
-
最常见的是在FC层之间放置p = 0.5的辍学层
合成函数
- CNN可以学习模式的空间层次结构。 这使ConvNets可以有效地学习日益复杂和抽象的视觉概念
- 每个过滤器将低级特征的本地补丁组合成高级表示-f(g(h(x))),以了解网络中更深层的更多丰富特征
翻译不变性
- 学习完图片右下角的特定模式后,aConvNet可以在任何地方识别它
- 它无法识别一个物体相对于另一个物体的位置,只能识别它们是否存在于特定物体中















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









