1.“# E:\AI_System\agent\cognitive_architecture.py
import os
import sys
import logging
import json
import time
import abc
from pathlib import Path
from agent.base_module import CognitiveModule
class CognitiveSystem(CognitiveModule):
"""核心认知系统实现"""
VERSION = "1.2.0"
# 默认配置参数
DEFAULT_CONFIG = {
"reasoning_depth": 3,
"memory_limit": 1000,
"auto_reflection": True,
"learning_threshold": 0.8,
"error_recovery": True,
"max_concurrent_tasks": 5
}
def __init__(self, name: str, model_manager, config: dict = None):
"""
初始化认知系统
:param name: 认知系统名称
:param model_manager: 模型管理器实例
:param config: 可选配置字典,覆盖默认配置
"""
super().__init__(name)
self.model_manager = model_manager
# 合并默认配置和用户配置
self.config = self.DEFAULT_CONFIG.copy()
if config is not None:
self.config.update(config)
# 验证配置有效性
self._validate_config()
# 初始化系统组件
self._initialize_components()
self.mode = "TASK_EXECUTION" # 默认任务执行模式
self.command_handlers = {
"help": self.handle_help,
"hi": self.handle_greeting,
"hello": self.handle_greeting,
"你好": self.handle_greeting,
"在吗": self.handle_greeting,
"status": self.handle_status,
"mode": self.handle_mode,
"models": self.handle_models,
}
# 初始化记忆系统
self.memory = {
"short_term": [],
"long_term": {},
"last_accessed": time.time()
}
# 初始化日志
self.logger = logging.getLogger(f"CognitiveSystem.{name}")
self.logger.info(f"✅ 认知系统初始化完成 (版本 {self.VERSION})")
self.logger.info(f"当前模式: {self.mode}")
self.logger.debug(f"系统配置: {self.config}")
def process_command(self, command: str) -> str:
"""处理用户命令的核心方法"""
try:
self.logger.info(f"🧠 处理命令: {command}")
# 分割命令和参数
parts = command.split(maxsplit=1)
cmd = parts[0].lower()
arg = parts[1] if len(parts) > 1 else ""
# 查找命令处理器
handler = self.command_handlers.get(cmd, self.handle_default)
return handler(arg)
except Exception as e:
self.logger.error(f"命令处理失败: {str(e)}", exc_info=True)
return f"❌ 处理命令时出错: {str(e)}"
# 命令处理函数
def handle_greeting(self, arg: str) -> str:
"""处理问候命令"""
return f"你好,我是{self.name}!有什么可以帮您?"
def handle_help(self, arg: str) -> str:
"""处理帮助命令"""
return """
=== 高级命令系统 ===
基础命令:
help - 显示此帮助信息
exit/quit - 退出系统
status - 查看系统状态
mode [mode]- 切换工作模式 (reflect, task, learn)
系统控制:
models - 显示已加载模型
config [key] [value] - 修改配置
多行输入:
输入多行命令时,在最后一行以 ;; 结束
"""
def handle_status(self, arg: str) -> str:
"""处理状态查询命令"""
return (
f"系统状态:\n"
f"- 认知系统: {self.name} v{self.VERSION}\n"
f"- 当前模式: {self.mode}\n"
f"- 最后访问: {self.memory['last_accessed']}\n"
f"- 短期记忆: {len(self.memory['short_term'])}/{self.config['memory_limit']} 条"
)
def handle_mode(self, arg: str) -> str:
"""处理模式切换命令"""
if not arg:
return "请指定模式: reflect, task, learn"
mode_map = {
"reflect": "SELF_REFLECTION",
"task": "TASK_EXECUTION",
"learn": "LEARNING"
}
new_mode = mode_map.get(arg.lower(), "")
if new_mode:
self.set_mode(new_mode)
return f"已切换到 {new_mode} 模式"
return f"❌ 无效模式: {arg} (可用选项: reflect, task, learn)"
def handle_models(self, arg: str) -> str:
"""处理模型查询命令"""
try:
# 获取模型注册表和已加载模型
model_registry = self.model_manager.model_registry
loaded_models = self.model_manager.loaded_models
# 构建模型信息列表
models_info = []
for name, path in model_registry.items():
status = "✅ 已加载" if name in loaded_models else "❌ 未加载"
models_info.append(f"- {name}: {path} ({status})")
return "已配置模型:\n" + "\n".join(models_info)
except Exception as e:
return f"❌ 获取模型信息失败: {str(e)}"
def handle_default(self, command: str) -> str:
"""默认命令处理器"""
return f"正在处理您的请求: {command}..."
def _validate_config(self):
"""验证配置参数有效性"""
if not 1 <= self.config.get("reasoning_depth", 3) <= 5:
raise ValueError("推理深度必须在1-5范围内")
if self.config.get("memory_limit", 1000) < 100:
raise ValueError("内存限制不能小于100")
def _initialize_components(self):
"""初始化认知系统的各个子组件"""
self.logger.debug("初始化推理引擎...")
self.logger.debug("初始化记忆系统...")
self.logger.debug("初始化学习系统...")
self.logger.debug("初始化任务调度器...")
def process_stimulus(self, stimulus: dict):
"""处理输入刺激"""
try:
self.logger.debug(f"处理刺激: {stimulus}")
self.memory["last_accessed"] = time.time()
if self.mode == "SELF_REFLECTION":
return self._process_self_reflection(stimulus)
elif self.mode == "LEARNING":
return self._process_learning(stimulus)
else: # TASK_EXECUTION
return self._process_task(stimulus)
except Exception as e:
self.logger.error(f"处理刺激失败: {str(e)}", exc_info=True)
return {"error": f"处理失败: {str(e)}"}
def generate_response(self):
"""生成响应(保留方法)"""
return {"status": "ready", "mode": self.mode}
def get_current_mode(self):
"""获取当前模式"""
return self.mode
def set_mode(self, new_mode: str):
"""切换模式"""
valid_modes = ["SELF_REFLECTION", "TASK_EXECUTION", "LEARNING"]
if new_mode in valid_modes:
self.mode = new_mode
self.logger.info(f"切换到 {new_mode} 模式")
return {"status": "success", "new_mode": new_mode}
else:
self.logger.warning(f"无效模式: {new_mode}")
return {"status": "error", "message": f"无效模式: {new_mode}"}
def _process_task(self, stimulus: dict):
"""处理任务执行"""
task_type = stimulus.get("type", "general")
content = stimulus.get("content", {})
self.logger.info(f"处理任务: {task_type}")
if task_type == "question":
return {"response": f"收到问题: {content.get('text', '')}"}
elif task_type == "command":
return {"response": f"执行命令: {content.get('text', '')}"}
else:
return {"response": f"处理通用任务: {json.dumps(content)}"}
def _process_self_reflection(self, stimulus: dict):
"""处理自我反思"""
self.logger.info("执行深度反思...")
return {"reflection": "反思完成", "insights": []}
def _process_learning(self, stimulus: dict):
"""处理学习任务"""
self.logger.info("执行学习任务...")
return {"learning": "学习完成", "knowledge": "新知识"}
def save_state(self, path: str):
"""保存系统状态"""
state = {
"version": self.VERSION,
"mode": self.mode,
"last_accessed": self.memory["last_accessed"]
}
try:
with open(path, 'w') as f:
json.dump(state, f)
self.logger.info(f"✅ 状态已保存到 {path}")
return True
except Exception as e:
self.logger.error(f"保存状态失败: {str(e)}", exc_info=True)
return False
def load_state(self, path: str):
"""加载系统状态"""
try:
with open(path, 'r') as f:
state = json.load(f)
self.mode = state.get("mode", "TASK_EXECUTION")
self.logger.info(f"✅ 状态已从 {path} 加载")
return True
except Exception as e:
self.logger.error(f"加载状态失败: {str(e)}", exc_info=True)
return False”
2."# E:\AI_System\core\config.py
import os
import json
import re
import logging
from pathlib import Path
from dotenv import load_dotenv
from typing import Any, Dict, Union, Optional
# 配置日志系统
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger('CoreConfig')
class CoreConfig:
"""重构的配置系统 - 修复了单例模式和加载问题"""
_instance = None
_initialized = False
def __new__(cls):
"""单例模式实现"""
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self):
"""初始化配置系统(确保只执行一次)"""
if self._initialized:
return
self._initialized = True
# 基础设置
self.base_dir = Path(__file__).resolve().parent.parent
self.config: Dict[str, Any] = {}
self.sensitive_fields = ["DB_PASSWORD", "SECRET_KEY", "API_KEY"]
self.path_keys = ["LOG_DIR", "MODEL_CACHE_DIR", "MODEL_BASE_PATH"]
try:
# 配置加载流程
self._load_defaults() # 步骤1: 设置默认值
self._load_environment() # 步骤2: 加载环境变量
self._load_config_files() # 步骤3: 加载配置文件
self._resolve_variables() # 步骤4: 解析变量引用
self._validate_paths() # 步骤5: 验证路径
logger.info("✅ 配置系统初始化完成")
except Exception as e:
logger.critical(f"🔥 配置加载失败: {str(e)}", exc_info=True)
raise RuntimeError(f"配置系统初始化失败: {str(e)}") from e
def _load_defaults(self):
"""设置默认配置值"""
self.config = {
"LOG_DIR": str(self.base_dir / "logs"),
"CONFIG_DIR": str(self.base_dir / "config"),
"MODEL_CACHE_DIR": str(self.base_dir / "model_cache"),
"AGENT_NAME": "小蓝",
"MODEL_BASE_PATH": "E:/AI_Models",
"MODEL_PATHS": {
"TEXT_BASE": "E:/AI_Models/Qwen2-7B",
"TEXT_CHAT": "E:/AI_Models/deepseek-7b-chat",
},
"NETWORK": {
"HOST": "0.0.0.0",
"FLASK_PORT": 8000,
},
"DIRECTORIES": {
"PROJECT_ROOT": str(self.base_dir)
},
"USE_GPU": True,
"LOG_LEVEL": "INFO"
}
logger.debug("设置默认配置值")
def _load_environment(self):
"""加载环境变量"""
# 1. 加载 .env 文件
env_file = self.base_dir / '.env'
if env_file.exists():
load_dotenv(env_file)
logger.info(f"🌐 从 {env_file} 加载环境变量")
# 2. 加载系统环境变量
for key, value in os.environ.items():
# 忽略非配置变量
if not key.startswith("AI_SYSTEM_"):
continue
# 转换键名格式:AI_SYSTEM_DB__HOST -> db.host
config_key = key[11:].lower().replace('__', '.')
# 类型转换
converted_value = self._convert_env_value(value)
# 设置配置值
self._set_nested_config(config_key, converted_value)
logger.debug(f"设置环境变量: {config_key} = [MASKED]"
if any(s in config_key for s in self.sensitive_fields)
else f"设置环境变量: {config_key} = {converted_value}")
def _convert_env_value(self, value: str) -> Any:
"""转换环境变量的值为适当类型"""
if value.lower() in ['true', 'false']:
return value.lower() == 'true'
elif value.isdigit():
return int(value)
elif value.replace('.', '', 1).isdigit():
try:
return float(value)
except ValueError:
return value
else:
return value
def _set_nested_config(self, key_path: str, value: Any):
"""设置嵌套配置值"""
keys = key_path.split('.')
current = self.config
for i, key in enumerate(keys):
if i == len(keys) - 1:
current[key] = value
else:
if key not in current or not isinstance(current[key], dict):
current[key] = {}
current = current[key]
def _load_config_files(self):
"""加载JSON/YAML配置文件"""
config_dir = Path(self.get("CONFIG_DIR", self.base_dir / "config"))
config_files = [
config_dir / "config.json",
config_dir / "settings.yaml"
]
for file in config_files:
if not file.exists():
continue
try:
if file.suffix == ".json":
with open(file, "r") as f:
new_config = json.load(f)
self._merge_config(new_config)
logger.info(f"📄 加载配置文件: {file}")
elif file.suffix in (".yaml", ".yml"):
try:
import yaml
with open(file, "r") as f:
new_config = yaml.safe_load(f)
self._merge_config(new_config)
logger.info(f"📄 加载配置文件: {file}")
except ImportError:
logger.warning("PyYAML未安装,跳过YAML配置")
except Exception as e:
logger.error(f"❌ 加载配置文件失败: {file} - {str(e)}")
def _merge_config(self, new_config: dict):
"""深度合并配置字典"""
def recursive_merge(base, update):
for key, value in update.items():
if isinstance(value, dict) and key in base and isinstance(base[key], dict):
recursive_merge(base[key], value)
else:
base[key] = value
recursive_merge(self.config, new_config)
def _resolve_variables(self):
"""解析配置中的变量引用(格式:${...})"""
pattern = re.compile(r'\$\{([^}]+)\}')
def resolve_value(value):
if isinstance(value, str):
return pattern.sub(self._replace_var, value)
return value
def traverse(data):
if isinstance(data, dict):
return {k: traverse(v) for k, v in data.items()}
elif isinstance(data, list):
return [traverse(item) for item in data]
else:
return resolve_value(data)
self.config = traverse(self.config)
def _replace_var(self, match) -> str:
"""替换单个变量引用"""
var_expr = match.group(1).strip()
# 处理默认值语法:${VAR|default}
if '|' in var_expr:
var_name, default_val = var_expr.split('|', 1)
var_name = var_name.strip()
default_val = default_val.strip()
else:
var_name = var_expr
default_val = None
# 获取配置值
value = self.get(var_name, default_val)
return str(value) if value is not None else ''
def _validate_paths(self):
"""验证并创建缺失的关键路径"""
# 检查目录路径
for key in self.path_keys:
path_str = self.get(key)
if path_str:
try:
path = Path(path_str)
if not path.exists():
path.mkdir(parents=True, exist_ok=True)
logger.info(f"📁 创建目录: {path}")
except Exception as e:
logger.error(f"❌ 创建目录失败: {key}={path_str} - {str(e)}")
def get(self, key_path: str, default: Any = None) -> Any:
"""通过点分路径获取配置值"""
keys = key_path.split('.')
value = self.config
for key in keys:
if isinstance(value, dict) and key in value:
value = value[key]
else:
return default
return value
def __getattr__(self, name: str) -> Any:
"""允许通过属性访问顶级配置项"""
if name in self.config:
return self.config[name]
raise AttributeError(f"配置项 '{name}' 不存在")
# 创建全局配置实例
config = CoreConfig()
"
3."# E:\AI_System\core\command_listener.py
import threading
import logging
import time
import sys
from queue import Queue
from typing import Callable, Union, Any
logger = logging.getLogger("CommandListener")
class CommandListener:
"""改进的命令监听器 - 增强多行处理和错误恢复"""
def __init__(self, command_handler: Callable[[str], Union[str, dict]], shutdown_handler: Callable[[], None]):
"""
初始化命令监听器
:param command_handler: 处理命令的函数,接受命令字符串,返回字符串或字典响应
:param shutdown_handler: 系统关闭时调用的函数
"""
self.command_handler = command_handler
self.shutdown_handler = shutdown_handler
self.command_queue = Queue()
self.running = False
self.input_thread = None
self.processing_thread = None
self.is_processing = False
self.multiline_buffer = [] # 多行输入缓冲区
def start(self):
"""启动命令监听器"""
if self.running:
logger.warning("命令监听器已在运行中")
return
logger.info("🔊 启动命令监听器")
self.running = True
# 启动输入线程
self.input_thread = threading.Thread(
target=self._read_console_input,
daemon=True,
name="CommandListener-Input"
)
self.input_thread.start()
# 启动命令处理线程
self.processing_thread = threading.Thread(
target=self._process_commands,
daemon=True,
name="CommandListener-Processor"
)
self.processing_thread.start()
logger.info("✅ 命令监听器已就绪,输入 'help' 查看可用命令")
print("> ", end='', flush=True) # 初始提示符
def stop(self):
"""优雅停止命令监听器"""
if not self.running:
return
logger.info("🛑 正在停止命令监听器...")
self.running = False
# 清空多行缓冲区
if self.multiline_buffer:
logger.debug("清理多行缓冲区")
self.multiline_buffer.clear()
# 等待处理完成
while self.is_processing:
time.sleep(0.1)
# 放入退出指令
self.command_queue.put("exit")
# 等待线程结束
self.input_thread.join(timeout=1.0)
self.processing_thread.join(timeout=1.0)
logger.info("命令监听器已停止")
def _read_console_input(self):
"""从控制台读取输入并处理多行逻辑"""
while self.running:
try:
# 读取一行输入
try:
line = input().strip()
except EOFError: # Ctrl+D
logger.info("收到EOF信号")
self.command_queue.put("exit")
return
except KeyboardInterrupt: # Ctrl+C
print() # 换行
self.command_queue.put("exit")
return
# 空行处理
if not line:
print("> ", end='', flush=True)
continue
# 多行结束标记检查
if line.endswith(";;"):
# 移除结束标记并添加到缓冲区
self.multiline_buffer.append(line[:-2].strip())
full_command = "\n".join(self.multiline_buffer)
self.command_queue.put(full_command)
self.multiline_buffer.clear()
print("> ", end='', flush=True) # 重置提示符
elif self.multiline_buffer:
# 多行输入中间行
self.multiline_buffer.append(line)
print("... ", end='', flush=True) # 多行提示符
else:
# 单行命令
self.command_queue.put(line)
print("> ", end='', flush=True)
except Exception as e:
logger.error(f"输入读取错误: {str(e)}")
time.sleep(0.5)
print("> ", end='', flush=True) # 恢复提示符
def _process_commands(self):
"""处理队列中的命令"""
while self.running:
try:
if not self.command_queue.empty():
self.is_processing = True
command = self.command_queue.get()
# 跳过空命令
if not command.strip():
self.is_processing = False
continue
# 安全日志记录(屏蔽敏感命令)
safe_command = self._sanitize_command(command)
logger.info(f"📩 收到命令: {safe_command}")
# 处理系统命令
if command.lower() in ["exit", "quit"]:
logger.info("🛑 收到退出命令")
self.shutdown_handler()
return
# 处理内置命令
if command.lower() == "help":
response = self._get_help_text()
print(f"\n{response}")
self.is_processing = False
continue
# 处理其他命令
try:
response = self.command_handler(command)
self._handle_response(response)
except Exception as e:
logger.error(f"命令处理错误: {str(e)}", exc_info=True)
print(f"\n❌ 命令处理错误: {str(e)}")
self.is_processing = False
time.sleep(0.05)
except Exception as e:
logger.error(f"命令处理循环错误: {str(e)}", exc_info=True)
self.is_processing = False
time.sleep(1)
def _sanitize_command(self, command: str) -> str:
"""屏蔽敏感命令信息"""
sensitive_keywords = ["password", "secret", "key", "token"]
if any(kw in command.lower() for kw in sensitive_keywords):
return "[敏感命令已屏蔽]"
return command
def _handle_response(self, response: Any):
"""处理不同类型的响应"""
if isinstance(response, dict):
# 字典响应直接打印
print("\n" + self._format_dict_response(response))
elif isinstance(response, str):
# 字符串响应格式化输出
print(f"\n📤 {response}")
elif response is None:
print("\nℹ️ 无响应")
else:
print(f"\n📤 {str(response)}")
def _format_dict_response(self, response: dict) -> str:
"""格式化字典响应为可读字符串"""
formatted = "💬 系统响应:\n"
for key, value in response.items():
formatted += f" • {key}: {value}\n"
return formatted
def _get_help_text(self):
"""生成帮助文本"""
help_text = """
=== 高级命令系统 ===
基础命令:
help - 显示此帮助信息
exit/quit - 退出系统
status - 查看系统状态
mode [mode]- 切换工作模式 (reflect, task, learn)
多行输入:
输入多行命令时,在最后一行以 ;; 结束
例如:
update user
set name = John Doe;;
"""
return help_text
# 便捷启动函数
def start_command_listener(command_handler: Callable[[str], Union[str, dict]],
shutdown_handler: Callable[[], None]) -> CommandListener:
"""
创建并启动命令监听器
:param command_handler: 处理普通命令的函数
:param shutdown_handler: 系统关闭时调用的函数
:return: CommandListener实例
"""
listener = CommandListener(command_handler, shutdown_handler)
listener.start()
return listener
"
4.我有E:\AI_System\agent\decision_system文件夹 里面有“pycache
init_.py
!config.yaml
critical trust.py
decision system.py
demo.py
init trust system.py
trust system.py
trust utils.py”“# E:\AI_System\agent\decision_system\decision_system.py
class EnhancedDecisionSystem(DecisionSystem):
"""整合多维度思考的增强决策系统"""
def __init__(self, knowledge_base, emotion_model, memory_system):
super().__init__(knowledge_base, emotion_model)
self.memory = memory_system
self.thinking_weights = {
"conscious": 0.6,
"unconscious": 0.3,
"subconscious": 0.1
}
self.long_term_questions = {}
self.insights = []
# 启动后台思考线程
self._init_background_processing()
def _init_background_processing(self):
"""初始化后台思考线程"""
import threading
self.running = True
# 长期思考线程
self.long_term_thread = threading.Thread(target=self._process_long_term_questions)
self.long_term_thread.daemon = True
self.long_term_thread.start()
# 灵感处理线程
self.insight_thread = threading.Thread(target=self._process_insights)
self.insight_thread.daemon = True
self.insight_thread.start()
def make_decision(self, input_data, context, urgency=0.5):
"""
增强决策方法 - 整合多维度思考
:param urgency: 紧急程度 (0.0-1.0)
"""
# 1. 无意识快速反应(条件反射)
if urgency > 0.7:
reflex_decision = self._unconscious_reflex(input_data)
if reflex_decision:
self._record_decision("reflex", reflex_decision, input_data)
return reflex_decision
# 2. 情感分析(整合到各维度)
emotion_state = self.emotion.analyze(input_data)
# 3. 多维度决策整合
conscious = self._conscious_processing(input_data, context, emotion_state)
subconscious = self._subconscious_influence(input_data)
# 4. 整合决策(动态权重)
final_decision = self._integrate_decisions(
conscious,
subconscious,
emotion_state,
urgency
)
self._record_decision("integrated", final_decision, input_data)
return final_decision
def _unconscious_reflex(self, input_data):
"""无意识快速反应(保留原有紧急处理逻辑)"""
# 保留原有紧急处理逻辑
if "urgent" in input_data:
return self._handle_urgent(input_data, self.knowledge)
# 新增记忆驱动的反射
reflex_pattern = self.memory.retrieve_reflex_pattern(input_data)
if reflex_pattern:
return reflex_pattern["response"]
# 情感驱动的快速反应
if self.emotion.current_intensity > 0.8:
return self.emotion.get_high_intensity_response()
return None
def _conscious_processing(self, input_data, context, emotion_state):
"""有意识思考(整合原有规则系统)"""
# 保留原有规则处理核心
knowledge = self.knowledge.retrieve(input_data)
decision = self._apply_rules(input_data, emotion_state, knowledge)
# 增强风险评估
risk_assessment = self._assess_risk(decision, context)
return {
"decision": decision,
"risk": risk_assessment["risk"],
"confidence": risk_assessment["confidence"]
}
def _subconscious_influence(self, input_data):
"""潜意识影响(新增功能)"""
# 1. 检查相关灵感
relevant_insights = [i for i in self.insights if i["relevance"] > 0.7]
if relevant_insights:
return {"type": "insight", "content": relevant_insights[0]}
# 2. 检查长期思考关联
for question_id, task in self.long_term_questions.items():
if self._is_related(input_data, task["question"]):
return {"type": "long_term", "content": task["partial_conclusions"]}
# 3. 记忆关联
associations = self.memory.retrieve_associations(input_data)
return {"type": "association", "content": associations}
def pose_question(self, question, priority=0.5):
"""提出长期思考问题(新增功能)"""
task_id = f"q_{time.time()}"
self.long_term_questions[task_id] = {
"question": question,
"priority": priority,
"start_time": time.time(),
"progress": 0.0,
"partial_conclusions": []
}
return task_id
def _process_long_term_questions(self):
"""处理长期思考问题(后台线程)"""
while self.running:
for task_id, task in list(self.long_term_questions.items()):
# 更新思考进度
task["progress"] = min(1.0, task["progress"] + 0.01 * task["priority"])
# 定期产生部分结论
if random.random() < 0.1 and task["progress"] > 0.3:
conclusion = self._generate_partial_conclusion(task["question"])
task["partial_conclusions"].append(conclusion)
# 思考完成时产生灵感
if task["progress"] >= 1.0:
insight = self._generate_insight(task["question"])
self.insights.append(insight)
del self.long_term_questions[task_id]
time.sleep(10) # 每10秒处理一次
def _process_insights(self):
"""处理灵感队列(后台线程)"""
while self.running:
if self.insights:
insight = self.insights.pop(0)
# 将重要灵感存入长期记忆
self.memory.store(insight["content"], significance=0.8)
# 更新知识库
self.knowledge.update_from_insight(insight)
time.sleep(5)
# 原有系统方法的增强版本
def learn_from_history(self):
"""增强的历史学习(整合多维度反馈)"""
# 分析历史决策(保留原有逻辑)
super().learn_from_history()
# 新增多维度反馈分析
for entry in self.decision_history[-30:]:
# 分析决策中不同维度的贡献
conscious_impact = self._analyze_conscious_impact(entry)
subconscious_impact = self._analyze_subconscious_impact(entry)
# 动态调整权重
if conscious_impact > subconscious_impact:
self.thinking_weights["conscious"] = min(0.8, self.thinking_weights["conscious"] + 0.02)
else:
self.thinking_weights["subconscious"] = min(0.3, self.thinking_weights["subconscious"] + 0.02)
# 其他辅助方法...
”我需要把我原有的decision_system.py删掉 还是把它放在E:\AI_System\agent里面 还是只需要新建你发给我的“# agent/diagnostic_system.py
import logging
import psutil
class DiagnosticSystem:
def __init__(self):
self.logger = logging.getLogger("DiagnosticSystem")
def check_modules(self):
"""检查核心模块状态"""
results = {
"cognitive_system": self._check_cognitive(),
"environment_interface": self._check_environment(),
"affective_system": self._check_affective(),
"system_resources": self._check_resources()
}
return results
def _check_cognitive(self):
try:
# 伪代码:实际应检查模块导入和初始化
from .cognitive_architecture import CognitiveSystem
return {"status": "✅ 正常运行", "version": CognitiveSystem.VERSION}
except Exception as e:
return {"status": "❌ 异常", "error": str(e)}
def _check_environment(self):
# 类似实现
return {"status": "✅ 正常运行"}
def _check_affective(self):
# 类似实现
return {"status": "✅ 正常运行"}
def _check_resources(self):
"""检查系统资源使用情况"""
return {
"cpu": f"{psutil.cpu_percent()}%",
"memory": f"{psutil.virtual_memory().percent}%",
"gpu": self._get_gpu_status()
}
def _get_gpu_status(self):
try:
import gpustat
stats = gpustat.new_query()
return [{
"id": gpu.index,
"utilization": gpu.utilization,
"memory": f"{gpu.memory_used}/{gpu.memory_total}MB"
} for gpu in stats.gpus]
except ImportError:
return "⚠️ gpustat 未安装"
except Exception as e:
return f"❌ GPU检测失败: {str(e)}"
”还是需要什么别的操作?
5.你可以把修好的文件直接发我吗?我需要能直接覆盖、替换的,请不要让我去修改 因为我不会,也不知道怎么改





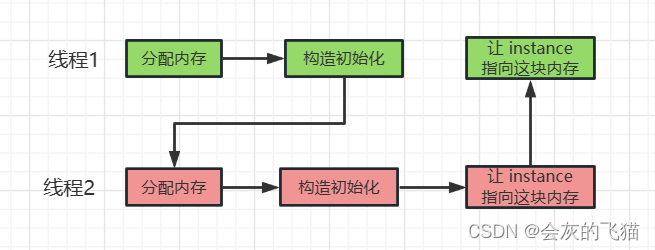
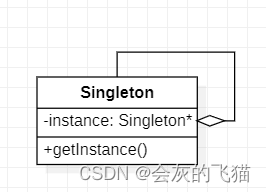
 本文详细介绍了C++中实现单例模式的几种方法,包括饿汉式、懒汉式(双重检查和基于静态局部变量初始化),讨论了它们的线程安全性和资源管理。此外,还强调了单例模式中拷贝构造函数和赋值操作的处理,以及如何在程序结束时回收单例对象占用的内存。
本文详细介绍了C++中实现单例模式的几种方法,包括饿汉式、懒汉式(双重检查和基于静态局部变量初始化),讨论了它们的线程安全性和资源管理。此外,还强调了单例模式中拷贝构造函数和赋值操作的处理,以及如何在程序结束时回收单例对象占用的内存。


















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









