









在看david silver的强化学习课程,顺便做做笔记,作为回顾复习,有些内容加上了自己的理解,不正确的话还望指出。
下面用到的图片均来自课程中的ppt,就不一一说明了,课程链接:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Home.html,优酷上有中文翻译的:http://v.youku.com/v_show/id_XMjcwNDA5NzIwOA==.html
RL解决的问题和特点
强化学习(简称RL)要解决的问题是序列决策问题,也就是为了达到目标要做一系列的决策,怎样做决策才能最好地达到目标。
比如说下围棋每一步如何落子才能最终获胜、玩游戏要如何玩才能赢、资金应该怎样投资才能获得最大的收利等等,理论上,任何关于序列决策的问题都可以尝试用RL去解决。
将监督学习(简称SL)与RL对比着来讲或许能更好地理解RL,就拿玩游戏来举例,如果用进行序列决策最直接的做法就是根据当前游戏的场景(e.g.一张图片)做出应该采取的动作,但使用SL时需要正确的标签,也就是对于当前游戏的格局采取的能使最终获胜的动作,你可以想象有一个游戏玩的超级6的玩家,玩每一盘游戏都赢,然后你让他玩几盘游戏,把他玩游戏期间遇到的游戏场景和采取的动作都记录下来,这样子就有很多很多的(游戏场景,应采取的动作)样本了,然后就可以开开心心地用SL的方法去训练model,这样的方法叫模仿学习。
那么RL有什么不同,RL里面有一个核心的概念叫做回报,回报是指在某个场景做出某种动作时获得的环境对这样子做的好不好的一个评价值,比如在游戏中,在某个场景做出了某个动作,可能就获得了一些奖励分或惩罚分。RL中做出了一个假设:任何目标都能通过最大化累计回报来达到。累计回报是指采取了某个动作后接下来一直到最后能得到的总的回报是多少,直观上讲,虽然我不知道当前游戏场景应该采取的正确的动作是什么,但是我可以尝试着去采取一个动作,如果这个动作的累计回报大,那么说明采取的这个动作是正确的,否则是错误的。也就是说RL是通过累计回报的大小来确定采取的动作好与坏,这种想法催生了RL里面的两大类方法,一种是算出在当前场景下采取哪种动作的累计回报值,然后选择最大的那个累计回报值对应的动作作为当前场景下应采取的动作,这种方法叫做value-base的方法;另一种是像SL那样去直接拟合P(动作|场景),而把当前场景下采取动作的累计回报值Q(场景,动作)作为衡量P(动作|场景)有多正确的得分,通过最大化∑Q(动作,场景)logP(动作|场景)来获取合适的P,这样的方法叫做policy-base的方法。
此外,注意到几个问题:(1)并不是每一步采取的动作都会有回报的,也就是说回报具有延迟性,但这并不意味着此时采取任意的动作都是对的,因为(2)当前采取的动作会影响后来的要采取的动作,这也是为什么我们不是只根据当前获得的回报来决定采取哪个动作是对的,而是要看采取了动作之后的一直到最后累计能获得的回报来决定哪个动作是对的。
代理与环境——RL应用场景的符号化表示
上面只是在用文字来描述RL的特点,我们还需要用一些符号正式地描述RL应用场景中的一些元素:
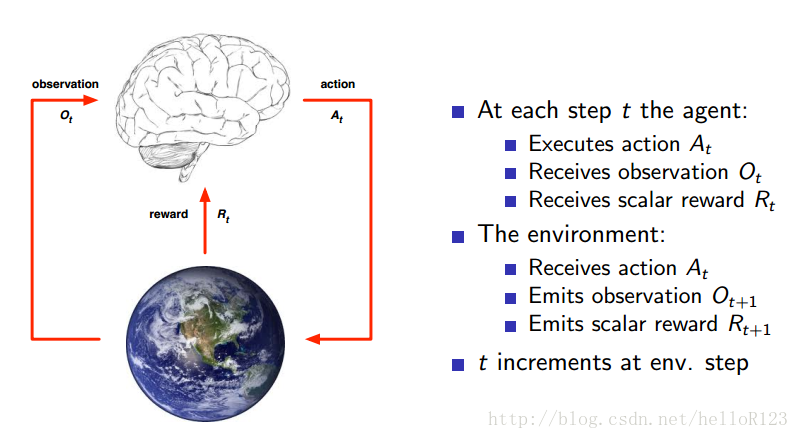
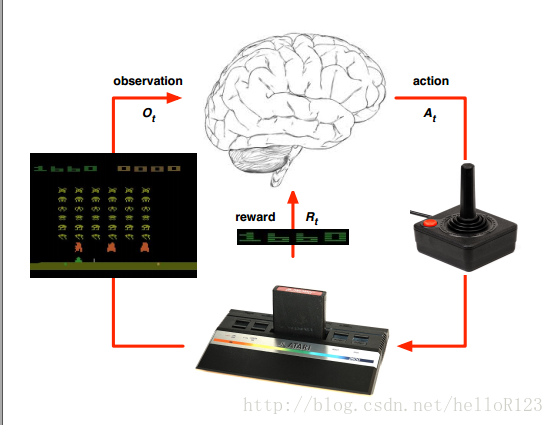
如上图,我们把做出决策叫做代理,与代理交互的叫做环境,代理在环境中做出一个动作,环境会返回给代理一个观测和回报。比如在游戏中:代理就是玩游戏的那个程序(也就是RL算法),环境就是游戏模拟器,每一次代理决定一个动作让游戏中的角色执行,然后可能获得一个回报(e.g.0:什么都没发生,1:获得了奖励,-1:收到了惩罚),然后游戏中角色现在处于的场景(e.g.一张图片)就是环境给代理的观测,如下图所示:
状态——RL决策的依据
前面说了RL运行时的一个形式化描述,但当真正去设计算法时,也就是如何去做出动作的时候,我们还需要的是能够用来支撑我们做出动作的信息,还有环境需要用来产生观测和回报的信息,这些信息就叫做状态。
历史
历史是指运行到现在的所有观测、动作和回报信息,也就是说:
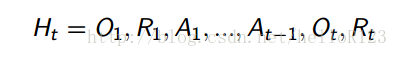
环境状态
环境状态是当环境接收到代理做出的动作时,用来产生观测和回报的信息;比如游戏中,可以把环境状态就理解成模拟器运行的程序。环境状态往往是不可观测的。
代理状态
代理状态是指代理中用来决定做出什么动作的信息,它被描述成是历史的函数,如下图:
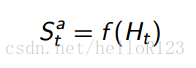
代理状态是代理做出动作的依据,如何确定好f直接影响到RL算法的性能好坏。
此外,虽然代理不知道环境状态是怎样的,这意味着如果没有环境,当它做出一个动作时,它不知道回报和反馈是怎样的,但代理有时可以假设代理状态具有环境状态的作用,也就是说根据当前代理状态和代理的动作,能够预测出接下来的观测和回报,类似于拟合一个概率模型P(o,r|s,a)用来作为代理对环境的近似,这个我们叫做模型或者叫做dynamic。
马尔科夫状态
马尔科夫状态是指有如下图所示性质的状态:

MDP与POMDP——RL应用场景的分类
MDP
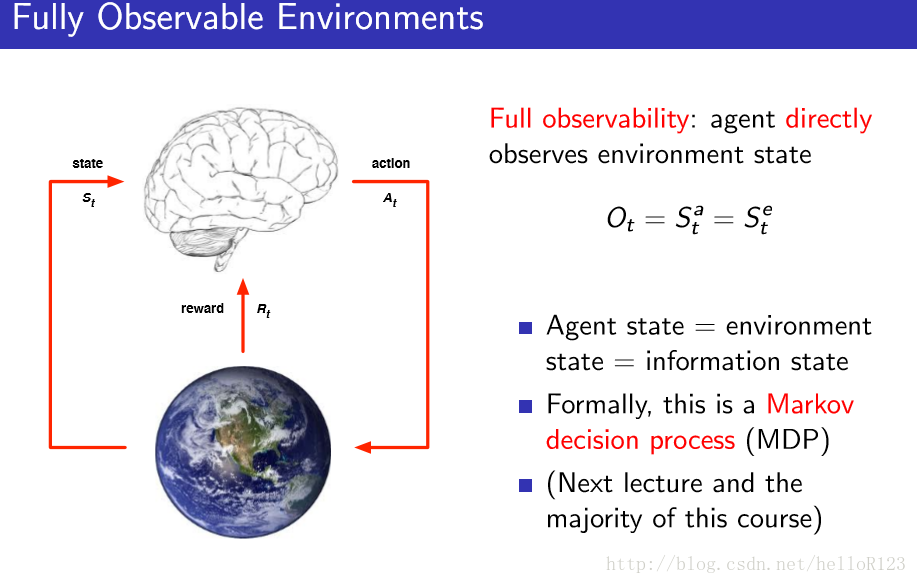
MDP是指环境状态和代理状态以及当前观测都是等价的,如下图所示:
POMDP

通过构造代理状态,一个POMDP问题也可以转化为一个MDP问题。
代理的主要组成部分——RL算法的组成成分
我们知道了代理的应用场景形式化表述,知道了代理的应用场景的分类,理解这些一是让我们对代理与环境交互的过程有一个直观的认识(之后还会更详细地介绍MDP),二是更好地理解代理内部也就是RL算法中组成部分。在讲具体的组成部分前,我们重述一下代理与环境交互的过程,以后讲的算法都是在MDP的情况下的(MDP后面会详细再说),所以重述这个交互过程也是处于MDP中。
首先,代理处于状态s0,根据s0以一定的概率采取动作a0(策略可以是随机的也可以是确定的),然后以一定的概率获得回报r1(回报可以是随机的也可以是确定的),然后以一定的概率跳到下一个状态s1,然后又更具s1采取a1……
策略
策略π(a|s)是指当处于状态s时应该采取什么动作或者说采取各个动作的概率是多大,RL的目的就是为了找出最优的策略π,使得能够得到最大的累计回报和。
价值函数
价值函数总是针对某个策略来说的,他们是衡量策略好坏的标准,有两种价值函数。
状态价值函数:
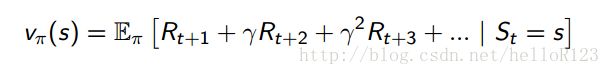
可以看出,状态价值函数就是说当处于状态s时,按照策略π执行下去到最后,能够获得的累计回报和的期望(计算期望是因为有许多随机性因素在)是多少。
动作价值函数:
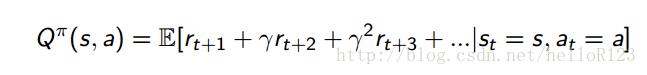
与状态价值函数不同的是,动作价值函数是当处于状态s,执行了动作a,然后再按照π执行下去到最后,能获得的累计回报与期望。
两种价值函数的定义都有作用,这里先不详细说,之后再讨论。
模型
模型是RL算法对环境的近似,之前有讨论,这里不赘述。注意的是,不是所有的RL算法都需要模型。
RL算法的类型
从学习策略的角度
- value-base:只用到了价值函数,而最优策略是通过价值函数导出的
- policy-base:对policy直接拟合,没有用到价值函数
- actor-critic:同时用到了价值函数和对policy的拟合
从模型使用角度
- model-free:没有用到模型
- model-base:用到了模型,而模型可以是事先给定的,也可以是学习出来的
RL中的一些概念列表
- learning和planning
- exploration和exploitation
- predictio和control
- on-line和off-line
- on-policy和off-policy














 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









