






想要在Jupyter Notebook打开指定的路径文件:
- 在cmd中输入jupyter notebook,直接在当前的路径打开了
1.Numpy矩阵与通用函数使用方法
import numpy as np#导入
x=np.array([1,2,3])#创建变量
y=np.array([4,5,6])
print('数组相加结果为:',x +y)#数组相加
print ('数组相减结果为:',x - y)#数组相减
print('数组相乘结果为:',x* y)#数组相乘
print('数组相除结果为:',x/y)#数组相除
print ('数组幂运算结果为: ',x**y)#数组幂运算
数组相加结果为: [5 7 9]
数组相减结果为: [-3 -3 -3]
数组相乘结果为: [ 4 10 18]
数组相除结果为: [0.25 0.4 0.5 ]
数组幂运算结果为: [ 1 32 729]
可以看出来用来数组计算还是很方便的
x=np.array([1,3,5])
y=np.array([2,3,4])
print('数组比较结果为:',x <y)
print ('数组比较结果为:',x > y)
print('数组比较结果为:',x== y)
print('数组比较结果为:',x>=y)
print ('数组比较结果为: ',x<=y)
print ('数组比较结果为: ',x!=y)
数组比较结果为: [ True False False]
数组比较结果为: [False False True]
数组比较结果为: [False True False]
数组比较结果为: [False True True]
数组比较结果为: [ True True False]
数组比较结果为: [ True False True]
print('数组逻辑运算结果为:',np.all(x==y))#np.all表示逻辑与
print('数组逻辑运算结果为:',np.any(x==y))#np.any表示逻辑或
数组逻辑运算结果为: False
数组逻辑运算结果为: True
2. 利用Numpy进行统计分析
import numpy as np
arr=np.arange(100).reshape(10,10)#创建一个数组
np.save('D:\pythonFX\jupyter/save_arr',arr)#保存数组到文件下面,名称是save_arr
print('保存数组为:\n',arr)
保存数组为:
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
保存多个数组的方法
arr1=np.array([[1,2,3],[4,5,6]])#创建一个数组
arr2=np.arange(0,1.0,0.1)
np.savez('D:\pythonFX\jupyter/save_arr',arr1,arr2)#保存两个数组到一个文件
print('保存数组1为:\n',arr1)
print('保存数组2为:\n',arr2)
保存数组1为:
[[1 2 3]
[4 5 6]]
保存数组2为:
[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
读
- 读取含有单个数组的文件
loaded_data=np.load(‘文件路径.npy’) - 读取含有多个数组的文件
print(‘读取的数组1为:\n’,loaded_data1[‘arr_0’])
print(‘读取的数组2为:\n’,loaded_data1[‘arr_1’]) - txt文件也是可以读取的
loaded_d=np.genfromtxt(‘D:\pythonFX\jupyter/arr.txt’,delimiter=‘,’) - 设置随机种子,生成随机数组,一共10个
np.random.seed(42)
arr=np.random.randint(1,10, size=10)
arr.sort(axis=1)#沿着横轴排序,每一行由小到大 - 去重
names =np.array([‘小明’,‘小黄’,‘小花’,‘小明’,‘小花’,‘小兰’,‘小白’])
print(‘创建的数组为:\n’,names)
print(‘去重后的数组为:\n’,np.unique(names)) - 各种计算
arr = np.arange (20).reshape(4,5)
print(‘创建的数组为:\n’, arr)
print('数组的和为: ', np. sum(arr))#计算数组的和
print('数组横轴的和为: ',arr.sum(axis=0))#沿若横轴讣算求彩
print('数组纵轴的和为: ',arr.sum(axis=1))#沿着纵铀计算求和
print('数组的均值为: ',np.mean(arr))#计算数组均值
print(‘数组横轴的均值为:’, arr.mean(axis=0))# 浴蓍横铀计算数组均值
print('数组纵轴的均值为: ',arr.mean(axis=1))# 浴着纵铀计算数组均值
print('数组的标准差为: ', np.std(arr))#计算数组标准差
print('数组的方差为: ',np.var(arr))#计算数组方差
print('数组的最小值为: ', np.min(arr))#计算数组最小值
print(‘数组的最大值为:’,np.max(arr))#计算数组最大值
print('数组的最小元素为: ', np.argmin(arr))#返回数组最小元紊的索引
print('数组的最大元素为: ', np.argmax(arr))#返回数组最大元紊的索引
3.读取数据库
(1)SQLAIchemy 连接 MySQL数据库
from sqlalchemy import create_engine#导入后才可以连接
#创建一个MySQL连接,用户名为root,密码为123456
#ip地址为127.0.0.1,数据库名称为test豆瓣,编码格式为utf-8
engine=create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/123456?charset=utf8')
print(engine)
(2)读
- 使用read_sql_query、read_sql_table、read_sql函数读取数据库中的数据
#使用read_sql_query函数查看testdb中的数据表清单
musicadatalist = pd.read_sql_query(‘show tables’, con=engine)
print(‘testdb数据库数据表清单为:\n’,musicadatalist) - 使用read_sql_table函数读取音乐行业收入信息表
musicdata=pd.read_sql_table(‘musicdata’,con=engine)
print(‘使用read_sql_table函数读取音乐行业收入信息表,表的长度为:\n’,len(musicdata)) - 使用read_sql函数读取音乐行业收人信息表
musicdata= pd.read_sql(‘musicdata’,con=engine)
print(‘使用read_sql函数读取音乐行业收入信息表,表的长度为:\n’,len(musicdata))
(3)写
- 使用to_sql()方法写入数据
musicdata.to_sql(‘test1’,con=engine,index=False,if_exists=‘replace’)
#使用read_sql_query 函数读取 testdb数据库
formlistl = pd.read_sql_query(‘show tables’,con=engine)
print(‘新增一个表格后,testdb 数据库数据表清单为:\n’,formlistl) - 查看音乐行业收入信息表的4个基本属性
from sqlalchemy import create_engine
import pandas as pd
#创建数据库连接
engine= create_engine(‘mysql+pymysql://root:123456@127.0.0.1:3306/123456?charset=utf8’)
musicdata = pd.read_sql_table(‘musicdata’,con=engine)
print(‘音乐行业收人信息表的索引为:’,musicdata.index)
print(‘音乐行业收人信息表的所有值为:\n’,musicdata.values)
print(‘音乐行业收人信息表的列名为:\n’,musicdata.columns)
print(‘音乐行业收人信息表的数据类型为:\n’,musicdata.dtypes) - size、ndim和shape 属性的使用
#查看DataFrame 的元素个数、维度、形状
print(‘音乐行业收人信息表的元素个数为:’,musicdata.size)
print(‘音乐行业收人信息表的维度为:’,musicdata.ndim)
print(‘音乐行业收人信息表的形状为:’,musicdata.shape)#musicdata.T.shape使用T属性进行转置
4.文件的读取与查看,利用pandas预处理
(1)合并年龄、平均血糖和中风患者信息数据
import pandas as pd
stroke_info = pd.read_excel('./healthcare-dataset-stroke.xlsx ' , encoding= 'utf-8' )
age_abs = pd.read_excel('./healthcare-dataset-age_abs.xlsx', encoding=' utf-8')
link_outer = pd.merge(stroke_info,age_abs,how='outer',left_on='编号',right_on='编号')
print(stroke_info.shape)
print(age_abs.shape)
print(link_outer.head())
print('======================')
print('合并后表格属性为:\n',link_outer.shape)
(1767, 9)
(1767, 3)
编号 性别 高血压 是否结婚 工作类型 居住类型 体重指数 吸烟史 中风 年龄 平均血糖
0 9046 男 否 是 私人 城市 36.6 以前吸烟 是 67.0 228.69
1 51676 女 否 是 私营企业 农村 NaN 从不吸烟 是 61.0 202.21
2 31112 男 否 是 私人 农村 32.5 从不吸烟 是 80.0 105.92
3 60182 女 否 是 私人 城市 34.4 抽烟 是 49.0 171.23
4 1665 女 是 是 私营企业 农村 24.0 从不吸烟 是 79.0 174.12
======================
合并后表格属性为:
(1767, 11)
删除年龄异常的数据
import numpy as np
w=link_outer['年龄']
m=[]
for i in w:
if i > 0.0:
m.append(i)
print(m)
m1=[x for x in m if x==int(x)]
print("删除年龄异常的数据:\n",m1)
(2)来聘人员信息
#读取信息
import pandas as pd
job = pd.read_csv('D:\pythonFX\jupyter\pandas\使用pandas进行预处理\来聘人员信息\hr_job.csv',index_col=0,encoding='gbk',engine='python')
# print (xinxi)
#1.查看缺失值的数量
print('job每个特征缺失的数目为:\n',job.isnull().sum())
#填补缺失值
job['性别']=job['性别'].fillna('未知')
job['教育水平']=job['教育水平'].fillna('未知')
#取平均后再添加未知
mean_num=int(job['工作次数'].mean())
job['工作次数']=job['工作次数'].fillna(mean_num)
#查看修改后缺失值的数量
print('修改后缺失值的数量为:\n',job.isnull().sum())
#2.异常值替换均值,性别异常值替换为”未知“
job['性别'][job['性别']=='Other']='未知'
job['工作次数'][job['工作次数']<0]=mean_num
#哑变量处理
job2=job.loc[:,['性别','相关经验','教育水平']]
print('哑变量处理前的数据为:\n',job2.sh)
job3=pd.get_dummies(job2)
print('哑变量处理后的数据为:\n',job3)
Output exceeds the size limit. Open the full output data in a text editor
job每个特征缺失的数目为:
性别 300
相关经验 0
教育水平 34
工作次数 2
dtype: int64
修改后缺失值的数量为:
性别 0
相关经验 0
教育水平 0
工作次数 0
dtype: int64
哑变量处理前的数据为:
性别 相关经验 教育水平
应聘人员ID
11561 未知 无 大学
33241 未知 无 大学
21651 未知 有 大学
28806 男 有 高中
402 男 有 大学
27107 男 有 大学
29452 未知 无 高中
23853 男 有 大学
5826 男 无 未知
8722 未知 无 高中
...
11347 0 0
10611 0 0
[1292 rows x 11 columns]
(3)我国人口数据
import pandas as pd
#读取“某地区房屋销售数据.csv”文件
data= pd.read_csv('中国城市人口数据.csv',encoding='gbk',engine='python')
#查看数据
print(data.head(5))
#查看数据维度、大小以及特征名称
print('数据维度为:',data.ndim)
print('数据大小为:',data.size)
print('数据特征形状为:',data.shape)
#描述性统计
print(data['2020年人口(万人)'].describe())
# 统计城市人口增长
print('人口增长数(w):',data['2020年人口(万人)'].sum()-data['2019年人口(万人)'].sum())
省份 2020年人口(万人) 2019年人口(万人)
0 河北省 7461 7447
1 山西省 3492 3497
2 辽宁省 4259 4277
3 吉林省 2407 2448
4 江苏省 8475 8469
数据维度为: 2
数据大小为: 66
数据特征形状为: (22, 3)
count 22.000000
mean 5482.772727
std 3067.216187
min 592.000000
25% 3583.000000
50% 4620.000000
75% 7256.750000
max 12601.000000
Name: 2020年人口(万人), dtype: float64
人口增长数(w): 94
5.基础绘图语句
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline表示在行中显示图片,在命令行运行报错
data = np. arange(0,1.1,0.01)
print(data)
plt.title('lines')#添加标题
plt.xlabel('x')#添加x轴的名称
plt.ylabel('y')#添加y轴的名称
plt.xlim((0,1))#确定x轴范围
plt.ylim((0,1))#确定y轴范围
plt.xticks([0,0.2,0.4,0.6,0.8,1])#规定x轴刻度
plt.yticks([0,0.2,0.4,0.6,0.8,1])#确定y轴刻度
plt.plot (data,data** 2)#添加y=x2曲线
plt.plot (data,data**4)#添加y=x^4曲线
plt.legend(['y=x^2','y=x^4'])
plt.savefig('y=x^2.jpg')
plt.show()
如图:
(1)如果要设置中文标题错
#设置rc参数显示中文标题
#设置字体为Shei是示中文
plt.rcParams['font.sans-serif']= 'SimHei'
plt.rcParams ['axes.unicode_minus'] = False#设置正常显示符号
6.熟悉pyecharts绘图
*
#导入下面的包
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Scatter3D
#转最大携氧能方、体重和运动后心率的维敬点图
player_data = pd.read_excel('data/运动员的最大携氧能力、体重和运动后心率数据.xlsx')
player_data = [ player_data['体重(kg)'],
player_data['运动后心率(次/分钟)'],
player_data['最大携氧能力(ml/min)']]
player_data = np. array(player_data).T.tolist()
s = (Scatter3D()
.add('',
player_data,xaxis3d_opts=opts.Axis3DOpts(name='体重(kg)'),
yaxis3d_opts=opts.Axis3DOpts (name='运动后心率(次/分钟)'),
zaxis3d_opts=opts.Axis3DOpts (name='最大携氧能力(ml/min)')
)
.set_global_opts(title_opts=opts.TitleOpts(
title='最大携氧能力、体重和运动后心率3D散点图'),
visualmap_opts=opts.VisualMapOpts(range_color=[
'#1710c0', '#0b9df0', '#00fea8', '#00ff0d', '#f5f811', '#f09a09','#fe0300' ]
)
)
)
s.render_notebook()
图片:
#漏斗图
from pyecharts.charts import Funnel
data = pd.read_excel('data/某淘宝店铺的订单转化率统计数据.xlsx')
x_data = data['网购环节'].tolist()
y_data = data['人数'].tolist()
data = [[x_data[i], y_data[i]] for i in range(len(x_data))]
funnel = (Funnel()
.add('', data_pair=data,label_opts=opts. LabelOpts(
position='inside', formatter='{b}:{d}%'), gap=2,
tooltip_opts=opts.TooltipOpts(trigger='item'),
itemstyle_opts=opts.ItemStyleOpts(border_color='#fff', border_width=1))
.set_global_opts(title_opts=opts.TitleOpts(title='某淘宝店铺的订单转化率漏斗图'),
legend_opts=opts.LegendOpts(pos_left='40%')))
funnel.render_notebook()
图片:

#词云图
from pyecharts.charts import WordCloud
data_read = pd.read_csv('data/worldcloud.csv', encoding='gbk')
words = list(data_read['词语'].values)
print(words)
num = list(data_read['频数'].values)
data = [k for k in zip(words,num)]
data = [(i, str(j)) for i,j in data]
wordcloud = (WordCloud()
.add('',data_pair=data, word_size_range=[10,100])
.set_global_opts(title_opts=opts.TitleOpts(
title='部分宋词词频词云图',
title_textstyle_opts=opts.TextStyleOpts(font_size=23)),
tooltip_opts=opts.TooltipOpts(is_show=True))
)
wordcloud.render_notebook()
图片:
7.给出一个表分析数据特征情况或绘图
(1)数据表学生考试成绩特征的分布和分散情况
提取学生3项单科成绩的数据,绘制学生各项考试成绩分散情况箱线图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] ='SimHei'#设置中文显示
plt.rcParams['axes.unicode_minus'] =False
data = np.load(r'student_grade.npz', encoding='ASCII',allow_pickle=True)
columns = data['arr_0']
values = data['arr_1']
#coiumns包含数据的列名,values是包含数据的二维数组
#定义咸绩变量
math_grade = values[:,-4]
reading_grade = values[:,-3]
writing_grade = values[:,-2]
all_grade = values[:,-1]
student_id = np.arange(len(values))
p= plt.figure(figsize=(15,15))#设置画布
#将每个学生的数学、阅读、写作、总成绩以及学生ID分别存储在相应的变量中。
#取学生考试总版绩区间人数
grade_0_150 = 0
grade_150_200 = 0
grade_200_250 =0
grade_250_300 =0
for i in range(len(values)):
if 0 < values[i,-1]<= 150 :
grade_0_150 += 1
elif 150 < values[i,-1]<= 200 :
grade_150_200 +=1
elif 200< values[i,-1]<= 250:
grade_200_250 +=1
elif 250 <values[i,-1] <= 300 :
grade_250_300 +=1
all_stu_grade = [grade_0_150,grade_150_200,grade_200_250,grade_250_300]
#筷用for循环遍历每个学生的总成绩,根据总成绩的范围,累加人数。最终将每个区间的人数存储在一个列表中
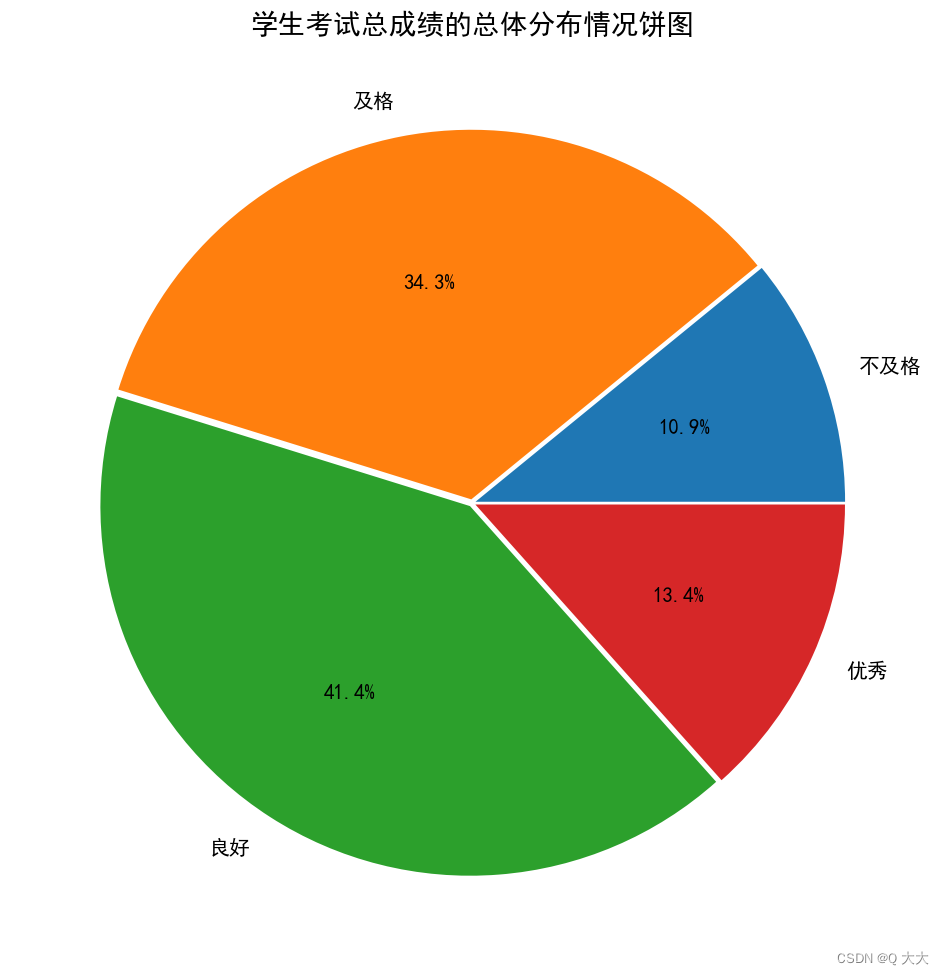
#绘制学生考试总版绩的总体分布情况饼图
p = plt.figure(figsize=(12,12))#设置画布
label= ['不及格','及格','良好','优秀']
explode = [0.01,0.01,0.01,0.01]#设定各项离心n个半径
plt.pie(all_stu_grade,explode=explode, labels=label,
autopct='%1.1f%%', textprops={'fontsize': 15})#绘制饼鸥
plt.title('学生考试总成绩的总体分布情况饼图',fontsize=20)
plt.savefig('学生考试总成绩的总体分布情况饼图.png')
plt.show()
#绘制学生考试总成绩的总体分布情况饼圈,设置标签、离心半径、标签字体大小和标题,最后保存图片并显示。
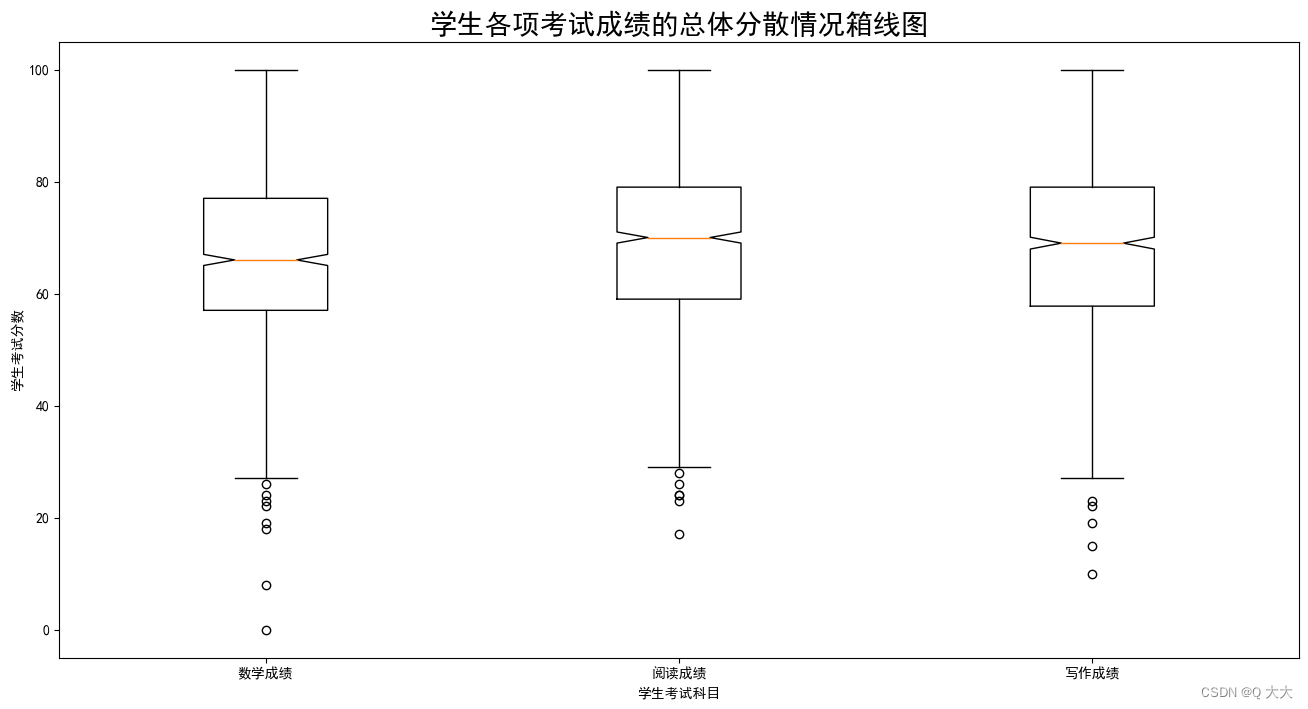
#绘制学生考试总成绩的总体分散情况箱线图
p= plt.figure(figsize=(16,8))
label=['数学成绩','阅读成绩','写作成绩']
gdp= (list(math_grade),list(reading_grade),list(writing_grade))
plt. boxplot(gdp, notch=True,labels=label, meanline=True)#绘制箱线图
plt.xlabel('学生考试科目')
plt.ylabel('学生考试分数')
plt.title('学生各项考试成绩的总体分散情况箱线图',fontsize=20)
plt.savefig('学生各项考试成绩的总体分散情况箱线图.png')
plt.show()
效果图:
(2)分析学生考试成绩与各个特征之间的关系
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = 'SimHei'#设置中文是示
plt.rcParams ['axes.unicode_minus'] =False
student_grade = pd. read_excel('student_grade.xlsx')
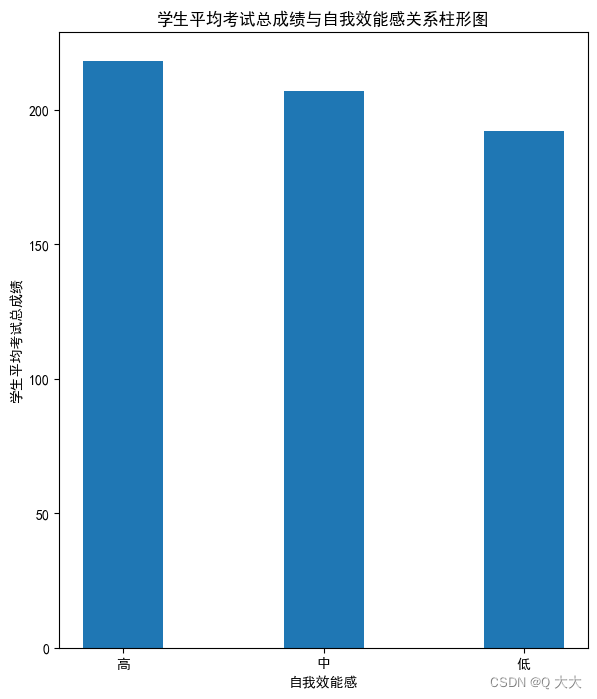
# 分别提取自我效能感对应的总成绩,并计算平均值,也就是切片
high = np.mean(student_grade.iloc[(student_grade['自我效能感']=='高').values,-1])
middle = np.mean(student_grade.iloc[(student_grade['自我效能感']=='中').values,-1])
low = np.mean(student_grade.iloc[(student_grade['自我效能感']=='低').values,-1])
mean_self_efficacy = [round(high) , round(middle) , round(low)]
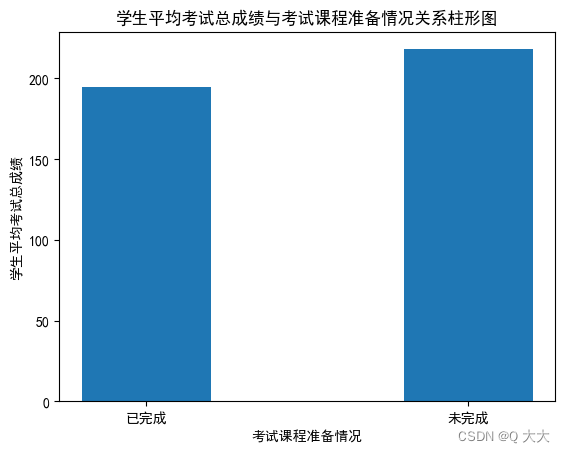
#分别提取考试课程准备情碗对应的.总成绩,并计算平均值
complete = np.mean(student_grade.iloc[(student_grade['考试课程准备情况']=='未完成').values,-1])
incomplete = np.mean(student_grade.iloc[(student_grade['考试课程准备情况']=='完成').values,-1])
mean_situation = [round(complete) , round(incomplete)]
p = plt.figure(figsize=(15,8))#设置画布
#子图1
ax2 = p.add_subplot(1,2,1)
label =['高','中','低']
plt.bar(range(3), mean_self_efficacy,width=0.4)#绘制柱形图
plt.xlabel('自我效能感')
plt.ylabel('学生平均考试总成绩')
plt. xticks (range(3), label)
plt.title('学生平均考试总成绩与自我效能感关系柱形图')
#子图2
ax2 = p.add_subplot(1,2,2)
label =['已完成','未完成']
plt.bar(range(2), mean_situation, width=0.4)#绘制柱形图
plt.xlabel('考试课程准备情况')
plt.ylabel('学生平均考试总成绩')
plt.xticks(range(2),label)
plt.title('学生平均考试总成绩与考试课程准备情况关系柱形图')
plt.savefig('学生考试总成绩与各个特征关系图.png')
plt.show()
效果图:
8.使用scikit-learn构建模型
(1).根据竞标行为训练集构建线性回归模型,并预测测试集结果。
(2).分别计算线性回归模型各自的平均绝对值、均方误差、R平方值
(3).根据得分,判定模型的性能优劣。
import pandas as pd#读取数据集
bidding = pd.read_csv('data\shill_bidding.csv',encoding='gbk', header=None)
#拆分数据和标签
bidding_data = bidding.iloc[1:,2:-1]
bidding_target = bidding.iloc[1:,-1]
#划分训练集和测试集
from sklearn. model_selection import train_test_split
bidding_data_train,bidding_data_test,bidding_target_train,bidding_target_test =train_test_split(bidding_data, bidding_target,test_size=0.2,random_state=123)
#PCA降维
from sklearn.decomposition import PCA
pca =PCA(n_components=0.999). fit(bidding_data_train)
bidding_trainPca = pca.transform(bidding_data_train)
bidding_testPca = pca.transform(bidding_data_test)
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
#线性回归模型
bidding_linear = LinearRegression().fit(bidding_trainPca,bidding_target_train)
y_pred = bidding_linear.predict(bidding_testPca)
#计算平均绝对误差、均方误差、R方值
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
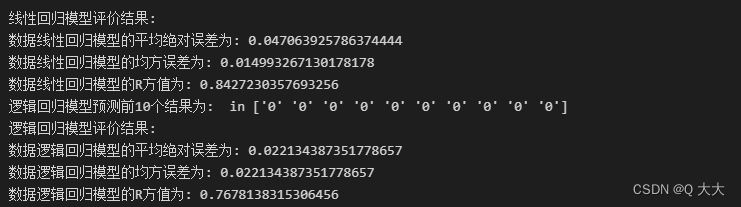
print('线性回归模型评价结果:')
print('数据线性回归模型的平均绝对误差为:',
mean_absolute_error (bidding_target_test,y_pred))
print('数据线性回归模型的均方误差为:',
mean_squared_error(bidding_target_test,y_pred))
print('数据线性回归模型的R方值为:',
r2_score(bidding_target_test,y_pred))
#逻辑回归模型
bidding_logistic = LogisticRegression(). fit(bidding_trainPca,
bidding_target_train)
y_pred2= bidding_logistic. predict(bidding_testPca)
print('逻辑回归模型预测前10个结果为: ','in', y_pred2[: 10])
print('逻辑回归模型评价结果:')
print('数据逻辑回归模型的平均绝对误差为:',
mean_absolute_error(bidding_target_test,y_pred2))
print('数据逻辑回归模型的均方误差为:',
mean_squared_error(bidding_target_test,y_pred2))
print('数据逻辑回归模型的R方值为:',
r2_score(bidding_target_test,y_pred2))















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









