






原文:Multi-scale Sparse Representation-Based Shodow Inpainting for Retinal OCT Images
Tang Yaoqi, Li Yufan, Liu Hongshan, Li Jiaxuan, Jin Peiyao, Gan Yu, Ling Yuye, Su Yikai. Multi-scale Sparse Representation-Based Shadow Inpainting for Retinal OCT Images. Medical Imaging(2022).文章目录
一、研究背景
眼科诊断对于眼科疾病的预防和治疗具有十分重要的作用,光学相干断层扫描(Optical Coherence Tomography, OCT)作为一种非侵入式、高分辨率的成像方式,已被应用于眼科临床诊断中,可以用于生成眼底视网膜图像。
然而,视网膜OCT图像会存在由于表层血管强散射造成的伪影,这些伪影会破坏视网膜的连续结构,影响OCT扫描系统后处理的效果,降低相关疾病的诊断准确率。

上图为视网膜OCT图像。ILM:内界膜,OPL:外从状层,IS/OS:椭圆体区,RPE:色素上皮,BM:Bruch膜,S:浅层视网膜,D:深层视网膜,R:视网膜(浅层+深层视网膜),O:外层视网膜,Oa:椭圆体区之上的外层视网膜。
目的:探索一种可以修复视网膜OCT图像伪影的自动化处理方法。
贡献:提出了一种结合传统方法和深度学习方法的算法框架。缓解了传统方法的修复效果随着修复面积的增大而降低,而深度学习算法需要庞大眼科影像数据和计算时间的问题。在合成伪影和真实伪影上都取得了较好的效果,能够在小样本和短训练时间的情况下,大幅提高后续分割算法的性能,具有很好的实时性。
方法概述:多尺度稀疏表征阴影填补框架,从而在不同尺度上重建阴影区域。通过稀疏表征提取结构信息,然后借助基于CNN的超分辨率模块进行融合。此外,还设计了正则化模块来约束重构的输出,同时合并其他尺度的信息。
二、方法
(一)框架

方法框架如上图所示,分为1)预处理,2)图像填补,3)后处理三部分。
- 在预处理过程中,将包含阴影的视网膜OCT图像进行展平,然后用基于A-line的阴影检测算法检测阴影部分。
- 在图像修复过程中,根据阴影的宽度将视网膜OCT图像分为无阴影区域、较窄的阴影区域和较宽的阴影区域这三种区域。对于无阴影区域,不进行任何操作。对于较窄的阴影区域,通过基于字典的修复 (DI) 模块进行处理。对于较宽的阴影区域,首先进行下采样减少阴影的宽度,然后通过DI模块进行处理,并基于稀疏表征进行修复。修复后的图像首先通过超分辨率网络上采样恢复到原始的分辨率,然后通过基于字典的正则化(Dictionary-based regularizing, DR) 模块去集成更高分辨率的互补特征信息。
- 在后处理过程中,将三个区域进行拼接,将拼接后的图像重新进行折叠,以恢复到展平前的OCT图像。
OCT知识:当OCT系统对样品组织进行探测事,将样品组织等效为一系列的反射面,即可探测某深度上组织的反射率。将光束对组织样品进行横向移动(B-scan),便可得到多条A-Lines,拼接出二维图像。
(由于本人对OCT没有什么了解,在网上查找一些资料后,感觉有点类似于超声,有错误之处欢迎指正)
(二)预处理
包括将视网膜OCT图像拉伸展平和阴影检测。
- 如何进行拉伸展平和阴影检测?
借助于Bruch膜,对Bruch膜进行识别拟合,以及拉伸。
由于Bruch膜 (BM) 是视网膜OCT图像中最亮的组织,因此可以将每条A-Line(也就是纵向线段)中最亮的像素提取出来,便可以识别 Bruch 膜。然后使用局部估计散点图平滑(Locally estimated scatterplot smoothing, LOESS)方法拟合BM膜的位置。并且检测拟合曲线中的异常值,从而确定阴影的位置(例如对于阴影区域,A-Line上的最高的像素值相对于Bruch膜像素值的肯定是异常的)。此外,根据拟合曲线将Bruch膜移动到固定深度,去除异常值,重新对齐A-Line以获得展平后的图像。
(三)图像修复
图像修复过程,对OCT图像的不同区域采取对应的处理方式:无阴影区域、窄阴影区域、宽阴影区域。根据阈值区分窄阴影和宽阴影区域,这个阈值设置为字典学习阶段使用的patch大小。
对于无阴影区域,不做任何操作。下面介绍对于窄阴影和宽阴影区域的处理过程。
字典学习
待补
(1)窄阴影区域
对展平图像的窄阴影区域进行剪裁,然后输送到DI模块,在DI模块中,将窄阴影区域划分为重叠的patch进行修复,patch的大小为a×b,将它们矢量化为 y ∈ Rab×1 。作者选择了33张高质量无阴影的视网膜OCT图像,用于训练的字典 D ∈ Rab×M (ab < M, M表示字典的“词条”,称为原子(atom)),字典训练过程如下:
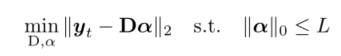
α ∈ RM×1 为稀疏系数,L为稀疏度,文章中取2,0阶范数表示该向量中不为0的数量,yt 表示训练中所用到的无阴影面片向量。
考虑到一个patch中有阴影像素的情况,首先从向量 y 中删除阴影像素得到 y’,然后从字典D中将对应的行进行删除(remove)得到D’。稀疏系数 α 帽计算如下:
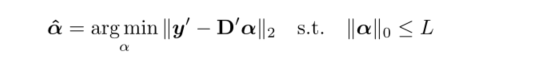
对 y 进行修复:
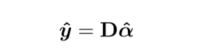
最后,将所以修复好的patch进行拼接,得到修复后结果。
(2)宽阴影区域
宽阴影区域的修复与窄阴影大同小异,不同之处在于首先将图像进行下采样,然后对修复后的输出进行上采样。
↓N 表示系数为N的下采样,在这篇文章中 N=4
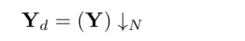
修复后的输出为 yd 帽,对 yd 帽 通过增强的深度残差网络(EDSR) 简称 u 进行上采样,以恢复高分辨率信息。
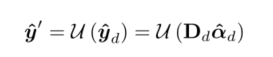
此外,为了约束生成的修复结果,设计了一个基于稀疏表示的正则化模块来细化patch聚合后的内容,对所有修复后的patch进行正则化:
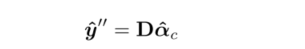
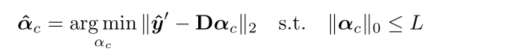
最后,这三种区域进行拼接,就可以获得完成的修复后的OCT图像。
三、实验设计
分别在真实伪影图像和生成伪影图像中进行验证。
(一)字典学习
数据:对两个分别包含128个原子的字典进行不同尺度的学习。训练数据是33个视网膜OCT图像,像素为1024×992。对于含阴影的区域,每张图像都被剪裁为10000个重叠的8×8的patch,也就是共有33万个patch。对于宽阴影区域的字典 Dd ,图像首先被下采样至4倍。
(二)实验比较
为了验证所提出的方法,与现有的传统方法以及最先进的基于深度学习的修复方法进行了比较。
传统方法:SI、TV
深度学习方法:CNN-based RFR and RN

上图显示了合成阴影和真实阴影的修复结果。第一行为生成阴影修复结果,第二行为真实阴影修复结果。第一列表示参考图像,第二列为阴影所在区域,第三列表示SI修复结果,出现了严重的不连续性。第四列为TV修复结果,总体来说比较平滑,但是阴影区域比较模糊且过度平滑了。第五列为基于CNN的RN修复结果,虽然它的修复看起来比较真实,但会出现比较明显的对比度阴影,导致PSNR和LPIPS较低。第六列为基于CNN的RFR方法,它在视觉效果上是最好的,但它的PSNR会略低。
定量指标:

为了进一步评估所提出的技术处理宽阴影的能力,在不同的阴影宽度(从7像素到24像素)重复修复实验。
该方法的优点:修复性能对阴影宽度的依赖性相对较低。
所提出的方法和RFR的PSNR、SSIM几乎保持不变,而其他传统方法的性能随着阴影宽度的增加而急剧下降

(三)分割结果
进一步比较了阴影修复在机器诊断中的有效性。将包含真实阴影的原始OCT图像和修复后的OCT图像输入UNet,用于视网膜层分割。
结果如下图所示,视网膜层共有九层,用不同的颜色标注。为了定量评估分割性能,计算了真实值和预测值之间的Dice分数。
结果分析:由于存在大血管,从原始图像获得的分割结果会出现明显的失真,如图4(b)所示。从图4©可以看出,SI的修复效果不佳,导致分割结果产生分散的标签,并出现层不连续性。与SI不同,TV和RN的分割连续性较好,但仍存在视网膜层弯曲。RFR是和所提出的基于字典的修复方法较好。但是,RFR获得了最好的性能和最高的Dice分数。

参考
[1] https://www.seiee.sjtu.edu.cn/seiee/info/34124.htm
[2] https://blog.csdn.net/u010136078/article/details/70654038
[3] https://www.cnblogs.com/endlesscoding/p/10090866.html















 5111
5111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









