







论文标题:Med3DVLM: An Efficient Vision-Language Model for 3D Medical Image Analysis
论文地址:https://arxiv.org/abs/2503.20047
导读:论文旨在解决3D医学图像分析中视觉语言模型的应用难题,提出 Med3DVLM 模型,通过创新的组件和训练策略,在多任务中取得优异成果,为临床应用提供了有效工具。
研究动机
医学图像分析对疾病诊疗至关重要,但现有模型存在任务特定、缺乏适应性和无法实时交互的问题。视觉语言模型(VLMs)在2D医学图像分析中表现出色,如CLIP和LLaVA,但扩展到3D成像面临挑战,包括计算复杂度高、难以捕捉全局上下文和缺乏公开数据。现有 3D VLMs,如 PMCCLIP、RadFM 和 M3D-LaMed,各有局限性,因此需要新的模型来克服这些问题。
创新点
高效3D特征编码:采用 DCFormer,将3D卷积分解为三个平行的1D 卷积,降低计算复杂度,有效捕捉3D图像的细粒度空间特征,可处理更大尺寸的3D数据(如 128x256×256),保留细节以改善图文对齐。
改进的视觉语言对齐:引入SigLIP对比学习策略,使用成对的 sigmoid 损失,直接独立优化每个图像-文本对,无需跨批次的全局相似性归一化,训练更稳定,对批次大小不敏感,更适用于小批量医学数据集。
多尺度多模态投影器:基于MLP - Mixer设计双流式投影器,融合低层次空间细节和高层次抽象语义特征,通过两个平行的 MLP - Mixer 模块分别处理不同层的图像特征,然后与文本嵌入融合,比简单线性投影更能捕捉丰富的跨模态交互,提高LLM解码准确性。
方法
数据集:使用公开的M3D数据集,包含M3D-Cap(120K图像-文本对)和M3D-VQA(662K 指令-响应对)两个子集,支持图像-文本检索、报告生成和VQA任务。图像体积重采样为128x256×256,数据集分为训练集(115k 样本)、验证集(3k 样本)和测试集(2k 样本)。
Med3DVLM模型:由视觉编码器(DCFormer)、多模态投影器(基于MLP-Mixer的设计)和大语言模型(LLM,如Qwen2.5-7B-Instruct)组成。训练过程分三个阶段:对比预训练,采用 SigLIP 优化视觉和文本编码器对齐;多模态投影器预训练,冻结其他权重,仅训练投影器;VLM 微调,采用低秩适应(LoRA)技术微调投影器和 LLM,减少可训练参数。
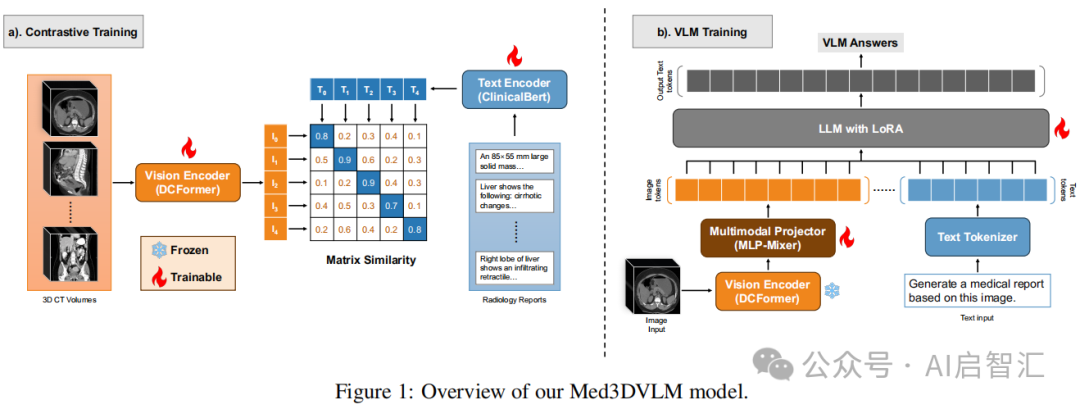
模型组成
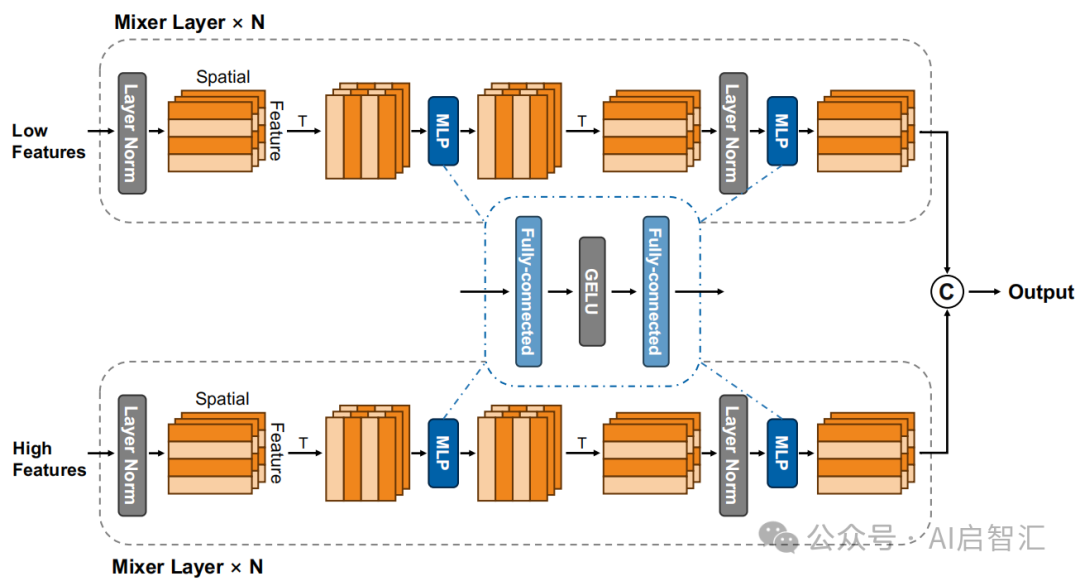
多模态投影器(基于MLP-Mixer的设计)
评估指标:图像-文本检索使用 Recall@K(R@K)指标;放射学报告生成和开放式VQA使用 BLEU、ROUGE、METEOR 和BERTScore评估;封闭式VQA使用准确率评估。
实现细节:基于PyTorch和Hugging Face Transformers实现,使用DeepSpeed ZeRO2 和BF16精度,在8个NVIDIA A100 80GB GPU上训练。各阶段训练设置不同的超参数,如对比预训练时的批次大小、学习率等。
实验
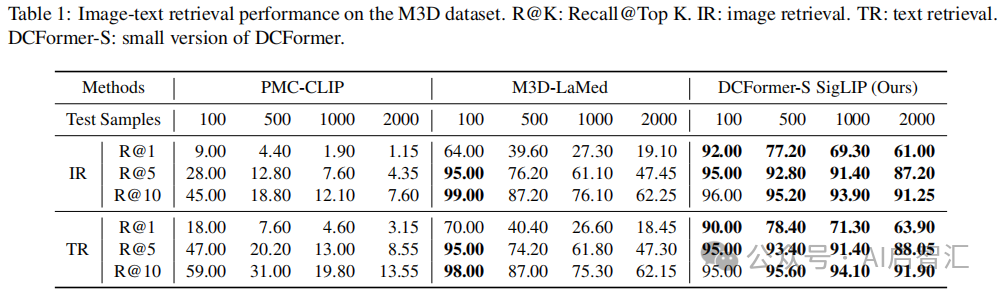
图像-文本检索:Med3DVLM在图像到文本和文本到图像检索任务上均显著优于 M3D - LaMed,在不同测试集大小下 R@1 指标最高,且随着测试集增大,性能优势更明显,表明其泛化能力强。
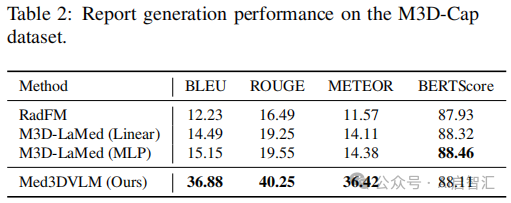
放射学报告生成:在定量评估中,Med3DVLM 在 BLEU、ROUGE 和 METEOR 指标上优于所有基线模型见下表2,虽 BERTScore 与其他方法相近,但生成文本在词汇选择、语法和结构上更优;定性分析中,其能识别关键异常,但存在过度泛化和幻觉现象见下图3。
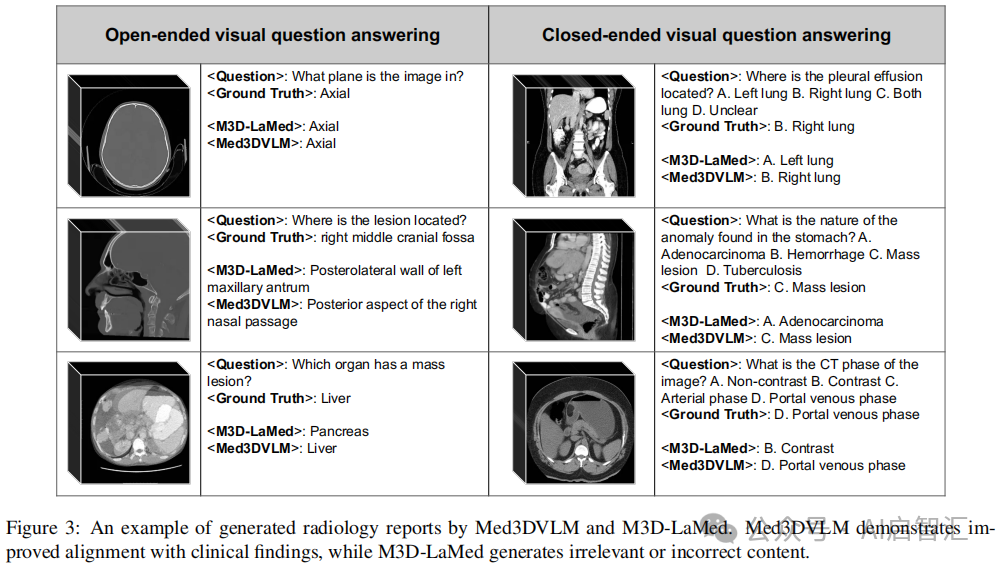
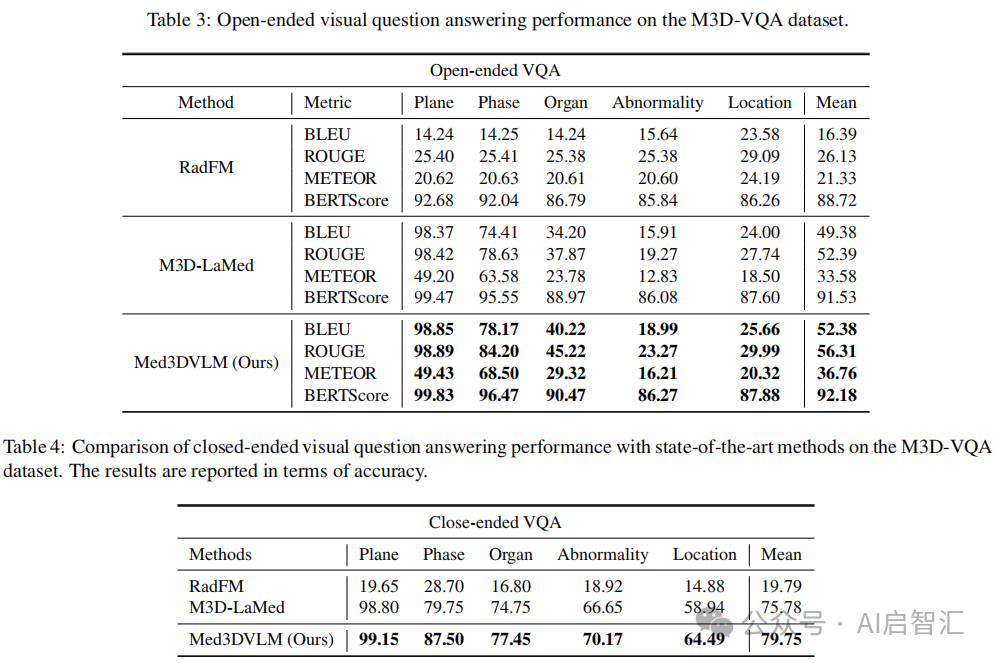
视觉问答:在开放式和封闭式 VQA 任务中均取得最优性能见表3、4。开放式 VQA 中,生成的回答更连贯流畅;封闭式 VQA 中,能准确识别多种信息。定性分析显示,Med3DVLM 在复杂问题上比 M3D - LaMed 表现更好,但仍有改进空间见图4。

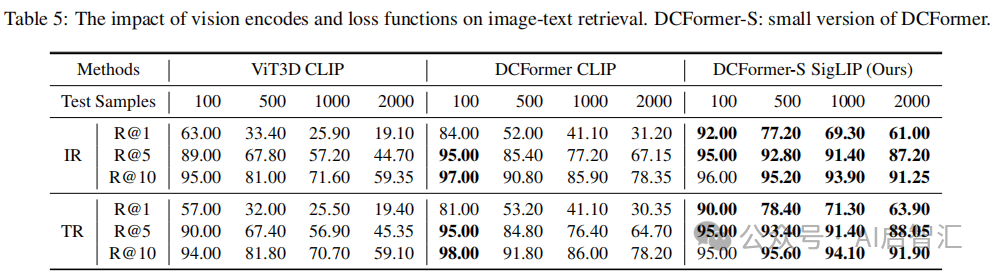
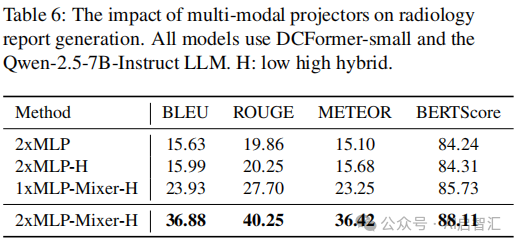
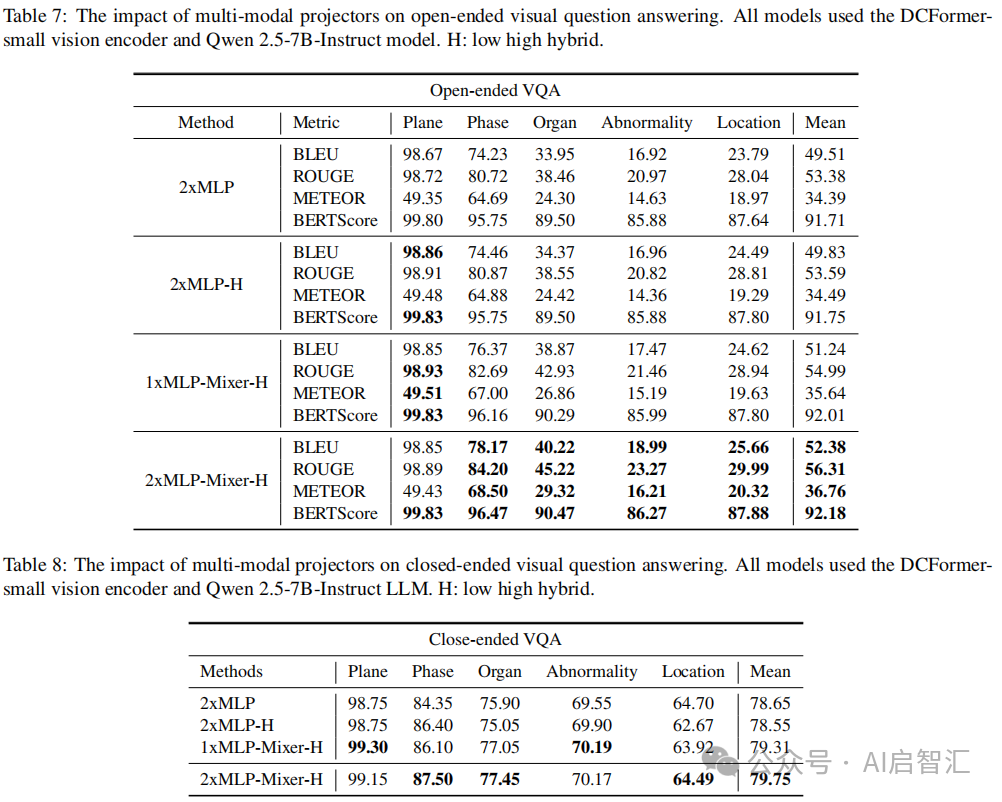
消融研究:对比不同视觉编码器(ViT3D vs. DCFormer)和对比损失函数(CLIP vs. SigLIP),发现DCFormer和SigLIP组合性能最佳,见表5;不同多模态投影器实验表明,2×MLP - Mixer架构在报告生成和VQA任务中表现更优见表6、7、8。
总结
Med3DVLM通过高效3D特征编码、优化的图文对齐策略和多层次特征融合,显著提升了3D医学图像分析的性能,为自动化、多任务医学AI系统奠定了基础。
以上仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】获取更多AI干货分享。


















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









