







论文标题:Test-Time Visual In-Context Tuning
论文地址:https://arxiv.org/abs/2503.21777
代码地址:https://github.com/Jiahao000/VICT
导读: 论文聚焦视觉上下文学习(VICL)在分布偏移下泛化性差的问题,提出测试时视觉上下文调优(VICT)方法,通过独特的循环一致性损失重构任务提示输出,在多任务实验中显著提升模型性能。核心思想是通过单样本自监督学习在线调整模型参数,利用测试样本自身特征提升模型对分布偏移的适应能力。
预备知识
视觉上下文学习(Visual In-Context Learning, VICL)是一种受自然语言处理(NLP)启发的计算机视觉范式,旨在让模型通过少量示例快速适应多种视觉任务,而无需重新训练或微调。其核心思想是将视觉任务转化为图像修复(inpainting)问题,通过上下文示例(输入-输出对)引导模型预测未知样本的标签。
研究动机
VICL受自然语言处理中上下文学习启发,将视觉任务构建为图像修复问题,利用少量提示和示例让预训练模型适应多种下游任务。但实际应用中,测试数据分布常与训练数据不同,现有VICL模型在分布偏移下性能下降明显。比如图1,在6个代表性视觉任务(包括深度估计、语义分割等)面对15种常见损坏(如噪声、模糊、天气等)时,像Painter这样的现有VICL模型在零样本(任务提示来自训练分布)和单样本(任务提示来自测试分布)设置下,性能都较差,这表明其泛化能力不足,难以适应未见新领域,因此需要研究提升VICL 模型在分布偏移下的泛化性。

创新点
提出新的循环一致性任务:首次为VICL进行测试时训练,提出通过翻转任务提示和测试样本的角色,利用循环一致性损失重构原始任务提示输出,让模型适应新的测试分布,且无需额外训练数据或注释 。
研究VICL的泛化性:率先研究VICL在分布偏移下的泛化性,发现现有VICL范式泛化能力差,即使任务提示与测试输入分布相同,性能提升也不明显 。
方法
视觉上下文学习(VICL):形式化表述为![]() ,其中S是支持输入-输出示例(任务提示)集,
,其中S是支持输入-输出示例(任务提示)集,![]() ∈S,x为图像,y为视觉标签(如分割掩码),
∈S,x为图像,y为视觉标签(如分割掩码),![]() 是新测试图像,
是新测试图像,![]()
是参数为![]() 的VICL模型,
的VICL模型,![]() 是
是![]() 的相应输出标签。
的相应输出标签。
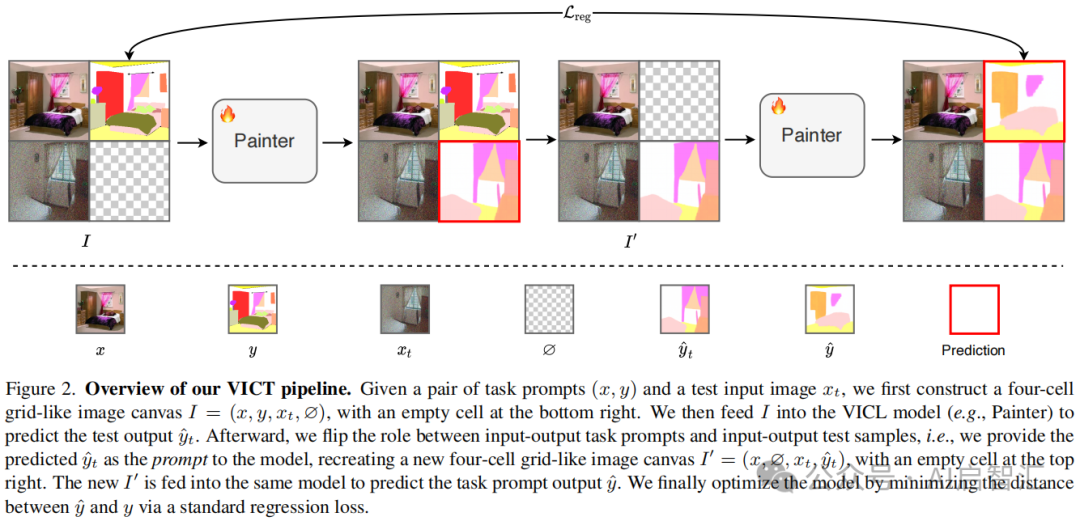
测试时视觉上下文调优(VICT):给定任务提示![]() 和测试输入
和测试输入![]() ,构建四单元格网格图像画布
,构建四单元格网格图像画布![]() (
(![]() 表示空单元格),将其输入 VICL 模型
表示空单元格),将其输入 VICL 模型![]() 得到测试输出
得到测试输出
![]() 。之后翻转角色,构建新画布
。之后翻转角色,构建新画布![]() ,再次输入模型得到任务提示输出
,再次输入模型得到任务提示输出![]() 。通过最小化
。通过最小化![]() 和y之间的距离(使用平滑
和y之间的距离(使用平滑![]() 损失)优化模型,即:
损失)优化模型,即:
![]()
算法1给出了VICT的伪代码,每次测试输入优化都从预训练模型权重![]() 开始,新测试输入到来时重置权重,独立处理每个测试输入。
开始,新测试输入到来时重置权重,独立处理每个测试输入。

实验
实验设置
评估模型在6个代表性视觉任务(深度估计、语义分割等)上的性能,使用15种常见损坏模拟分布偏移,构建相应损坏数据集(如 NYUv2-C、ADE20K-C 等)。以Painter为VICL 模型基线,研究VICT在零样本(任务提示来自训练分布)和单样本(任务提示来自测试分布)设置下的效果。训练采用AdamW优化器,学习率1e-6,批大小为1,每个测试样本训练60步,仅优化编码器权重 。
对比结果
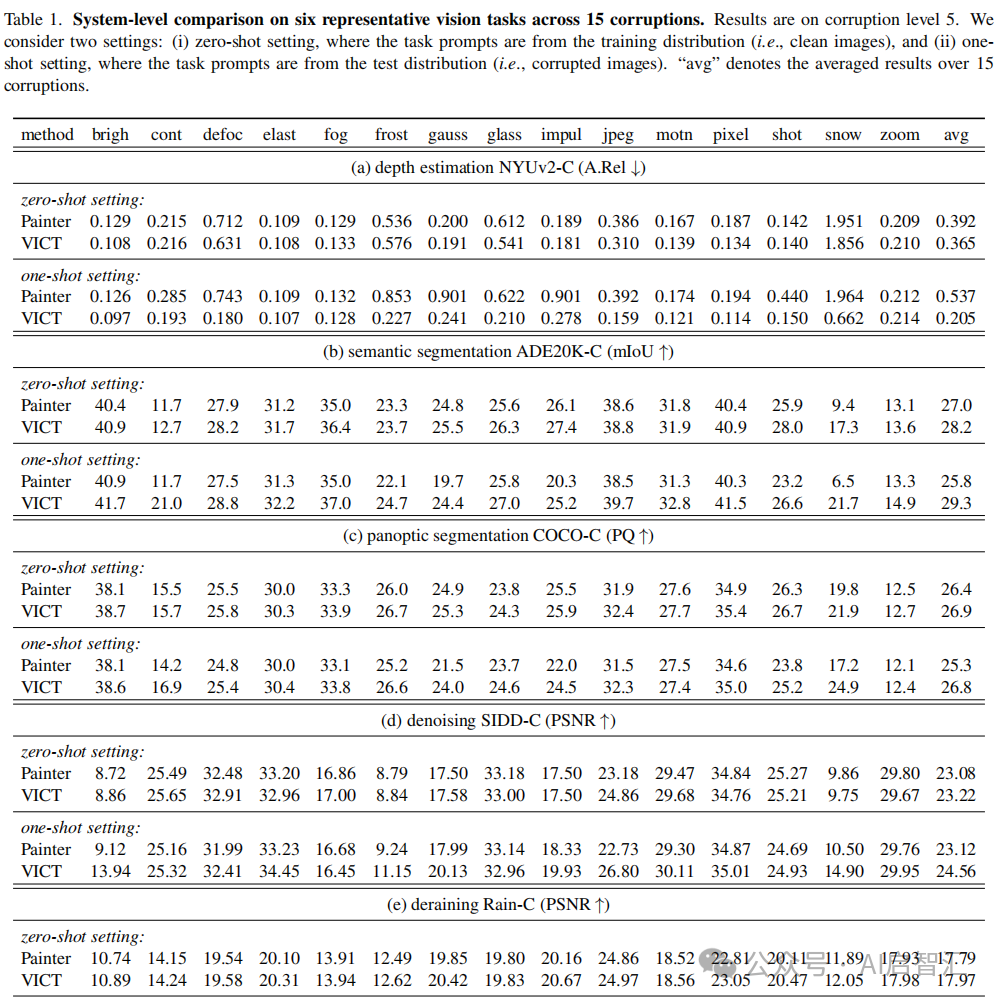
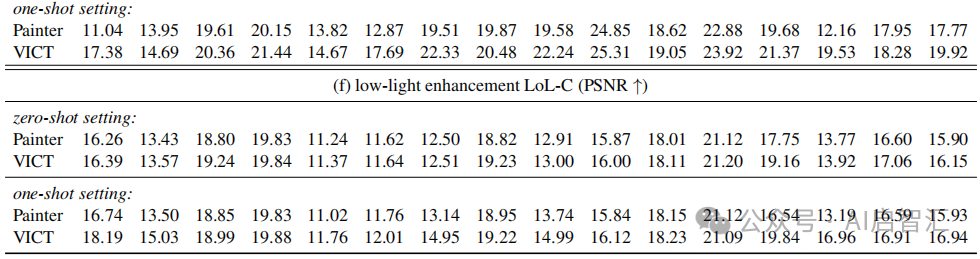
如表1所示,VICT 在不同任务和设置下均显著优于Painter。零样本设置下,在NYUv2-C 深度估计中 A.Rel 平均降低 0.027,在 ADE20K-C 语义分割中mIoU平均提高1.2等;单样本设置下性能提升更明显,且VICT的单样本设置通常优于零样本设置,零样本 VICT 甚至超过单样本Painter。与少样本Painter比较,如图3所示,零样本和单样本 VICT均能持续超越单样本 Painter,在一些任务中,即使只有一个或没有标记测试样本,VICT也能达到与使用更多标记测试样本训练的模型相似的性能。
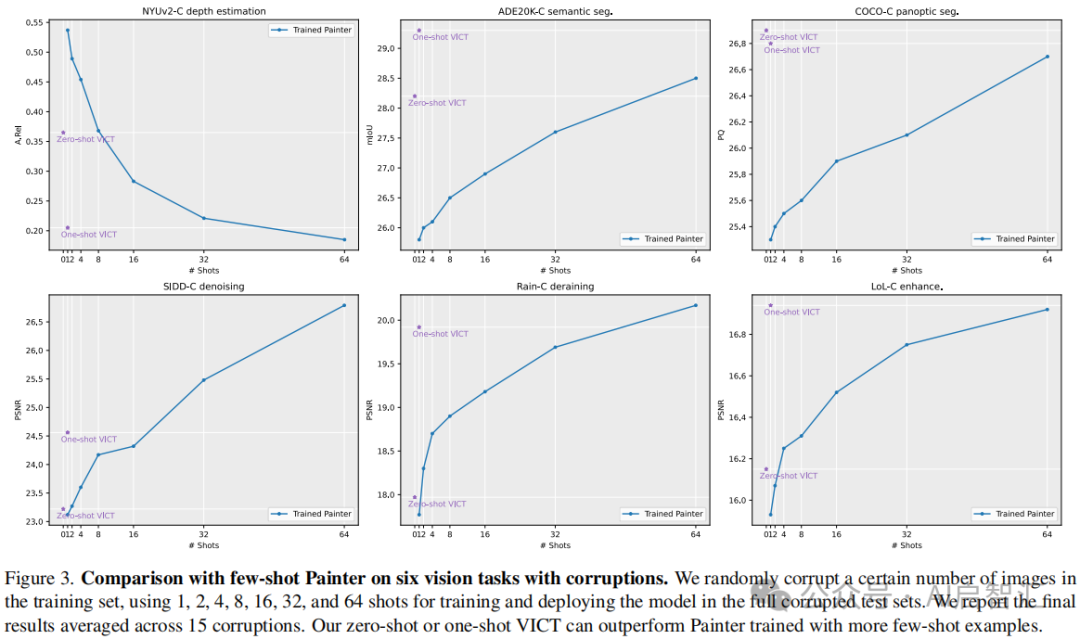
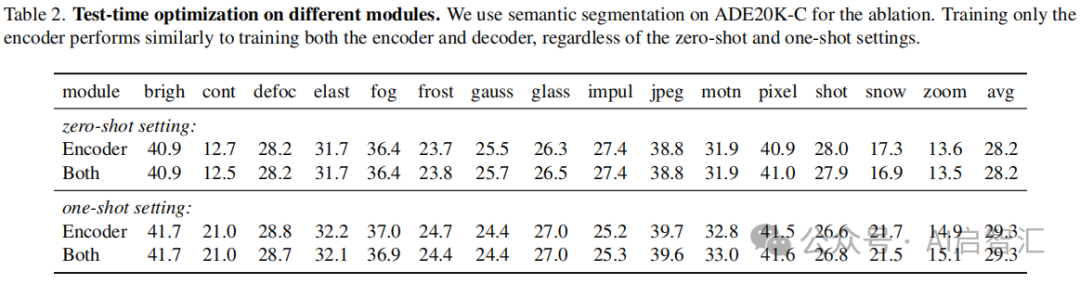
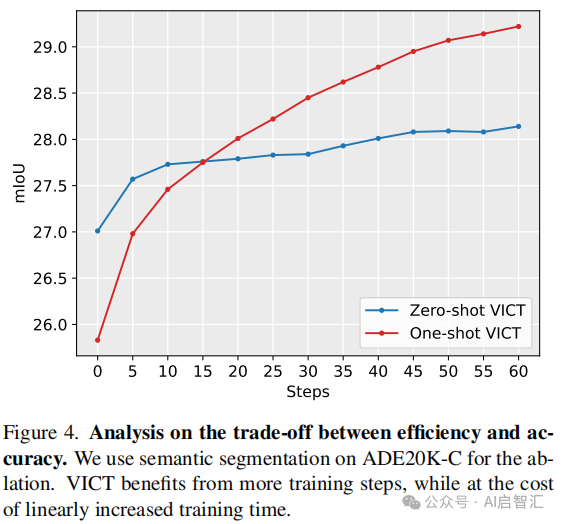
研究测试时优化模块的影响:以 ADE20K-C语义分割为例,如表2,训练仅编码器与训练编码器和解码器的效果相似,因此选择仅优化编码器。研究测试时优化步数的影响,如图4,VICT 性能随训练步数增加而提升,但运行时间也线性增加,实际应用中可根据成本预算决定步数 。
定性结果
在主要任务上,如图5,VICT 在所有任务上的预测都比 Painter 更准确。在未见任务上,如图6,VICT 能对前景对象分割和彩色化等未见任务产生不错的结果,而 Painter 在彩色化任务上无法泛化,进一步证明 VICT 在未见任务上的应用潜力。


总结
论文提出方法在线优化,未来需轻量化设计。另外,极端干扰情况下未验证,如结构破坏、对抗攻击等场景。未来可扩展多模态上下文(文本+图像)、动态优化策略。
以上仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】获取更多AI干货分享。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









