






1. 激活函数
- Rectified Linear Unit(ReLU) - 用于隐层神经元输出
- Sigmoid - 用于隐层神经元输出
- Softmax - 用于多分类神经网络输出
- Linear - 用于回归神经网络输出(或二分类问题)
ReLU函数计算如下:
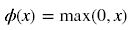
Sigmoid函数计算如下:
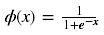
Softmax函数计算如下:
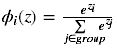
Softmax激活函数只用于多于一个输出的神经元,它保证所以的输出神经元之和为1.0,所以一般输出的是小于1的概率值,可以很直观地比较各输出值。
2. 为什么选择ReLU?
深度学习中,我们一般使用ReLU作为中间隐层神经元的激活函数,AlexNet中提出用ReLU来替代传统的激活函数是深度学习的一大进步。我们知道,sigmoid函数的图像如下:
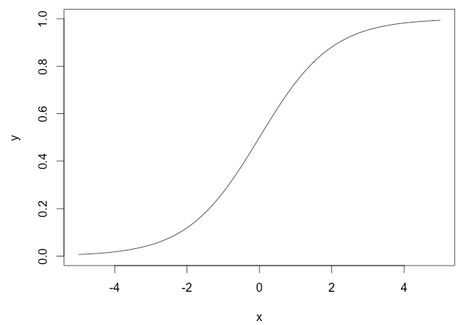
而一般我们优化参数时会用到误差反向传播算法,即要对激活函数求导,得到sigmoid函数的瞬时变化率,
其导数表达式为:
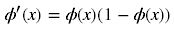
对应的图形如下:
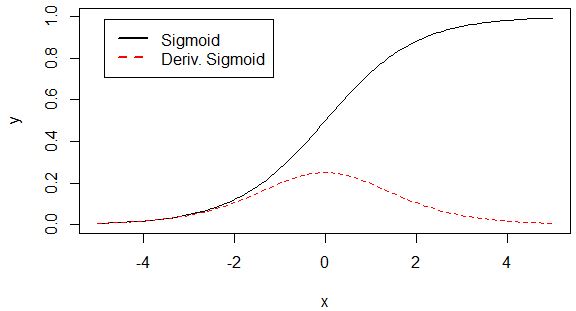
由图可知,导数从0开始很快就又趋近于0了,易造成“梯度消失”现象,而ReLU的导数就不存在这样的问题,它的导数表达式如下:
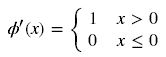
Relu函数的形状如下(蓝色):
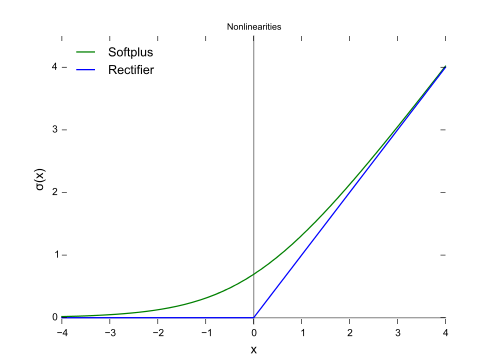
对比sigmoid类函数主要变化是:1)单侧抑制 2)相对宽阔的兴奋边界 3)稀疏激活性。这与人的神经皮层的工作原理接近。
3. 为什么需要偏移常量?
通常,要将输入的参数通过神经元后映射到一个新的空间中,我们需要对其进行加权和偏移处理后再激活,而不仅仅是上面讨论激活函数那样,仅对输入本身进行激活操作。比如sigmoid激活神经网络的表达式如下:
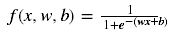
x是输入量,w是权重,b是偏移量(bias)。这里,之所以会讨论sigmoid函数是因为它能够很好地说明偏移量的作用。
权重w使得sigmoid函数可以调整其倾斜程度,下面这幅图是当权重变化时,sigmoid函数图形的变化情况:
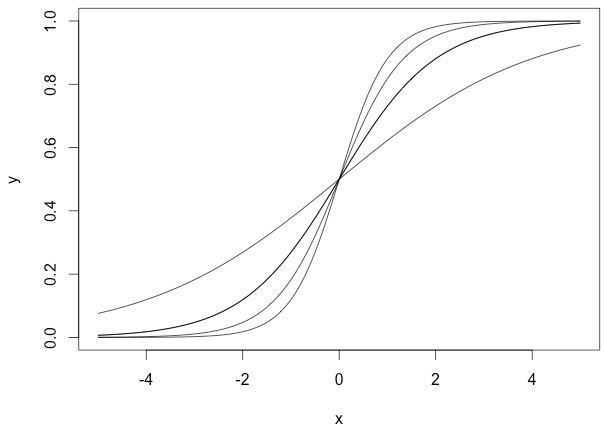
上面的曲线是由下面这几组参数产生的:
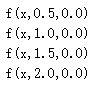
我们没有使用偏移量b(b=0),从图中可以看出,无论权重如何变化,曲线都要经过(0,0.5)点,但实际情况下,我们可能需要在x接近0时,函数结果为其他值。下面我们改变偏移量b,它不会改变曲线大体形状,但是改变了数值结果:
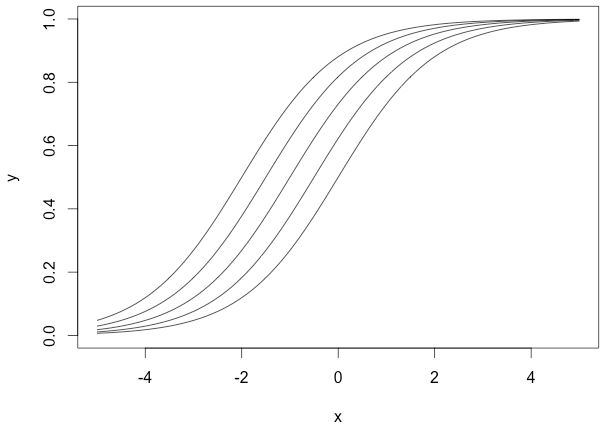
上面几个sigmoid曲线对应的参数组为:

这里,我们规定权重为1,而偏移量是变化的,可以看出它们向左或者向右移动了,但又在左下和右上部位趋于一致。
当我们改变权重w和偏移量b时,可以为神经元构造多种输出可能性,这还仅仅是一个神经元,在神经网络中,千千万万个神经元结合就能产生复杂的输出模式。
放一个福利 ===> 深度学习网
红Siraj Raval关于如何选择激活函数的viedo。














 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









