






1.1 定义
对于图G,若存在一条路径,经过G中每条边有且仅有一次,称这条路为欧拉路径;如果存在一条回路经过G每条边有且仅有一次,称这条回路为欧拉回路。具有欧拉回路的图成为欧拉图。
1.2 判断欧拉路径是否存在的方法
有向图:图连通,且只有一个顶点出度大入度1,有一个顶点入度大出度1,其余都是出度=入度。
无向图:图连通,奇度数的结点个数不多于2个,其余都是偶数度的。
1.3 判断欧拉回路是否存在的方法
有向图:图连通,且所有的顶点出度=入度。
无向图:图连通,且所有顶点都是偶数度。
定理一:如果连通无向图  有
有 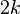 个奇顶点(奇定点数必然为偶数个),那么它可以用
个奇顶点(奇定点数必然为偶数个),那么它可以用  笔画成,并且至少要用 笔画成。
笔画成,并且至少要用 笔画成。
证明:将这 个奇顶点分成 对后分别连起,则得到一个无奇顶点的连通图。由上知这个图是一个环,因此去掉新加的边后至多成为 条欧拉路径,因此必然可以用 笔画成。但是假设全图可以分为  条欧拉路径,则由定理一知,每条链中只有不多于两个奇顶点,于是
条欧拉路径,则由定理一知,每条链中只有不多于两个奇顶点,于是 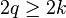 。因此必定要 笔画成。
。因此必定要 笔画成。
1.4 欧拉路径与欧拉回路的题目
程序实现一般是如下过程:
(1).利用并查集判断图是否连通,即判断p[i] < 0的个数,如果大于1,说明不连通。
(2).根据出度入度个数,判断是否满足要求。
(3).利用DFS输出路径。
P1: 给出N个节点,M个边,问要遍历一遍所有的边,需要的最小group数目。即相当于求一个图中最少需要几笔画.
(代码源自http://www.cnblogs.com/buptLizer/archive/2012/04/15/2450297.html , 此处对原作者代码做了分析,以便思路更明确。)
/*函数过程中是维护一个连通图点集A,初始时,每个单独的结点都是一个连通图,每加入一条边,则将两个连通图合并在一起,组成一个新的连通图。且对于每个连通图,都有其代表结点x。数组p[]用来记录结点与所在连通图代表结点之间的关系。*/
#include <iostream>
#include <stdio.h>
using namespace std;
const int maxv = 100 + 2;
int odds[maxv]; /* 顶点 */
int du[maxv]; /* 每个顶点的度数 */
int p[maxv]; /* 并查集数组 */
bool used[maxv];
int scc[maxv]; /* scc个数 */
void init(int n) /*初始化数组*/
{
for(int i = 0; i <= n; ++i)
{
odds[i] = 0;
p[i] = -1;
du[i] = 0;
used[i] = 0;
}
}
int utf_find(int x) /*本函数用来寻找结点x的代表结点。如果x尚未加入到数组当中或者x即 */
{ /* 为自己以及其他结点的代表结点,p[x]<0. 此时返 回自己x;*/
if(0 <= p[x]) /*若结点x已被加入到集合A中且此时x的代表结点不是自己*/
{ /* 则递归调用寻找所在连通图的代表结点x',特征是p[x']<0。*/
p[x] = utf_find(p[x]);
return p[x];
}
return x;
}
void utf_union(int a, int b) //当加入一条边的时候,是合并两个连通图。
{
int r1 = utf_find(a); //寻找新加入边的两个结点所在连通图的代表结点是否一样,
int r2 = utf_find(b); //一样的话则为“冗余边”;否则即是将两个连通图连通在一块。
if(r1 == r2)
return;
int n1 = p[r1]; //每个连通图中结点的个数,连通图A1中的结点个数为|n1|,连通图A2中的结点个数为|n2|.
int n2 = p[r2];
if(n1 < n2) //A1中结点个数大于A2中结点个数
{ //将A2中的代表结点,再链接到A1中的代表结点。
p[r2] = r1; //这样A1,A2中结点的代表结点将都是A1的代表结点。
p[r1] += n2; //实现两个连通图的合并.更新新的连通图A1中的结点个数。
}
else
{
p[r1] = r2; //同上。
p[r2] += n1;
}
}
int main()
{
int n = 0;
int m = 0;
int a = 0;
int b = 0;
int i = 0;
int cnt = 0;
while(scanf("%d%d", &n, &m) != EOF)
{
init(n);
cnt = 0;
for(i = 1; i <= m; ++i) //本段为加入边,并对边做并查集归并。具体如上所示。
{
scanf("%d%d", &a, &b);
du[a]++;
du[b]++;
utf_union(a, b);
}
for(i = 1; i <= n; ++i)
{
int f = utf_find(i);
if(!used[f]) //检查图中的连通图个数
{
used[f] = 1;
scc[cnt++] = f;
}
if(1 == du[i]%2) //检查每个连通图中度数为奇数的结点个数
odds[f]++;
}
int ret = 0;
for(i = 0; i < cnt; ++i) //对每个连通图做判断
{
if(0 == du[scc[i]]) //如果连通图是单个结点,则继续。
continue;
if(0 == odds[scc[i]]) //否则如果连通图中度数为为奇数的结点个数为0,则只需
++ret; //一笔或者或者只需一条路径就能遍历所有的边
else //若连通图中度数为奇数的节点个数不为0,
ret += odds[scc[i]]/2;//设为2k,则需要k条路径才能遍历所有的边。
}
printf("%d\n", ret); //函数最后返回遍历所有的边需要的路径数
}
return 0;
}
P2: 给出n个单词,如果一个单词的尾和另一个单词的头字符相同,那么这两个单词可以相连。求这n个单词是否可以排成一列。应用欧拉图,构图:一个单词的头尾字幕分别作为顶点,每输入一个word,则该word的头指向word的尾有一条边。记录每个顶点的出入度。利用并查集先判断是否为SCC。如果是的话再判断奇数度节点为0个或者2个。
P3: 给出n个field以及m条边连接这m个field,要求遍历每条边2次。求这样的一条路径。
若该field组成的图是连通分量,那么由于每条边遍历2次,即等效的每个结点的度均为偶数。故必然存在欧拉回路。此时只需对原图作一次DFS,即可得到这样的路径。需要记录下每次访问的结点顺序,重复访问的也需打印出来。
P4: 给出一组单词,如果一个单词的尾和另一个单词的头字符相同,那么这两个单词可以相连。问这组单词能否排成一排,如果可以求出字典序最小的那个。构图:单词作为边,单词的首字符和尾字符作为结点。读入一个单词即添加一条边。用邻接链表法存边。首先判断图是否连通,如果是,再判断该图能否构成欧拉路径或者回路。如果是回路,从字符'a'开始寻找,找到第一个存在的字母,从这个字母遍历就行。如果是路径,那么必须从出度大于入度的那个结点开始访问。由于这个题目要求的是最小字典序,然后考虑我们建立邻接表时是采用头插法,那么我们将单词从小到大排序,由于我们遍历结点肯定是从小的结点开始的,这样遍历一个结点的邻接边的时候就会从大到小访问这个结点的边,无法满足字典最小。所以从大到小排序,遍历依node数组为准,每次遍历一条边设置下标表示已访问过。

















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









