







http://blog.csdn.net/androidlushangderen/article/details/50724917
巧遇Hadoop 3.0 Erasure Coding
第一次主动去了解erasure coding这个东西纯粹是好奇,因为我平时主要混迹于Hadoop社区中HDFS模块部分,经常看到有很多的Issue Summary以单词Erasure Coding打头,而且这些任务一般都隶属于HDFS-8031下的子任务,比如下图所示的1个:
原来这是Erasure coding后续1阶段的工作.然后我就上网查了一下Erasure coding的意思于是就萌生了写此文的意图.Erasure coding同样作为一门技术,在学习hadoop 3.0 erasure coding之前,还是非常有必要去了解学习Erasure coding这门技术.

Erasure coding纠删码
Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术.他通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性.在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复.下面结合图片进行简单的演示,首先有原始数据n个,然后加入m个校验数据块.如下图所示:
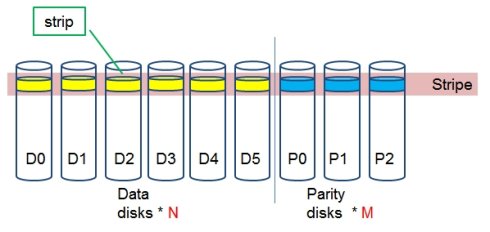
Parity部分就是校验数据块,我们把一行数据块组成为Stripe条带,每行条带由n个数据块和m个校验块组成.原始数据块和校验数据块都可以通过现有的数据块进行恢复,原则如下:
- 如果校验数据块发生错误,通过对原始数据块进行编码重新生成
- 如果原始数据块发生错误, 通过校验数据块的解码可以重新生成
而且m和n的值并不是固定不变的,可以进行相应调整.可能有人会好奇,这其中到底是什么原理呢? 其实道理很简单,你把上面这图看成矩阵,由于矩阵的运算具有可逆性,所以就能使数据进行恢复,给出一张标准的矩阵相乘图,大家可以将二者关联.
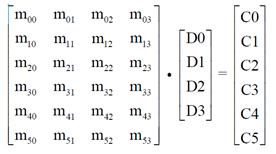
至于里面涉及数学推理的方面,同学们可以自行寻找资料进行学习.
Erasure Coding技术的优劣势
优势
纠删码技术作为一门数据保护技术,自然有许多的优势,首先可以解决的就是目前分布式系统,云计算中采用副本来防止数据的丢失.副本机制确实可以解决数据丢失的问题,但是翻倍的数据存储空间也必然要被消耗.这一点却是非常致命的.EC技术的运用就可以直接解决这个问题.
劣势
EC技术的优势确实明显,但是他的使用也是需要一些代价的,一旦数据需要恢复,他会造成2大资源的消耗:
- 网络带宽的消耗,因为数据恢复需要去读其他的数据块和校验块
- 进行编码,解码计算需要消耗CPU资源
概况来讲一句话,就是既耗网络又耗CPU,看来代价也不小.所以这么来看,将此计数用于线上服务可能会觉得不够稳定,所以最好的选择是用于冷数据集群,有下面2点原因可以支持这种选择
- 冷数据集群往往有大量的长期没有被访问的数据,体量确实很大,采用EC技术,可以大大减少副本数
- 冷数据集群基本稳定,耗资源量少,所以一旦进行数据恢复,将不会对集群造成大的影响
出于上述2种原因,冷数据集群无非是一个很好的选择.
Erasure Coding技术在Hadoop中的实现
前面花了大量的篇幅介绍EC技术,相信大家已经或多或少了解了这项技术.现在才是本文的一个重点,Hadoop Erasure Coding的实现.因为我们都知道,Hadoop作为一个成熟的分布式系统,用的也是3副本策略,所以这项技术的产生对于Hadoop本身来说,意义还是非常重大的.考虑到EC技术在Hadoop中的实现细节可能比较复杂,所以我不会逐行代码般的进行分析,从大的方向上理一理实现思路.
EC概念在Hadoop中的演变
EC概念指的是data block数据块,parity block校验块,stripe条带等这些概念在HDFS中是如何进行转化的,因为要想实现EC技术,至少在概念上相同的.
- data block,parity block在HDFS中的展现就是普通的block数据块
- stripe条带的概念需要将每个block进行分裂,每个block由若干个相同大小的cell组成,然后每个stripe由于一行cell构成,相当于所有的data block和parity block抽取出了一行
下面用图形直观展示
上面的横竖结构可以看出来很像之前提到的矩阵.为什么要有stripe条带概念就是因为矩阵运算就会读到每行的数据.OK,接下来我们放大上面这个图
要对应上面的3种概念,需要设计几种逻辑上的单元概念,有下面2个逻辑概念

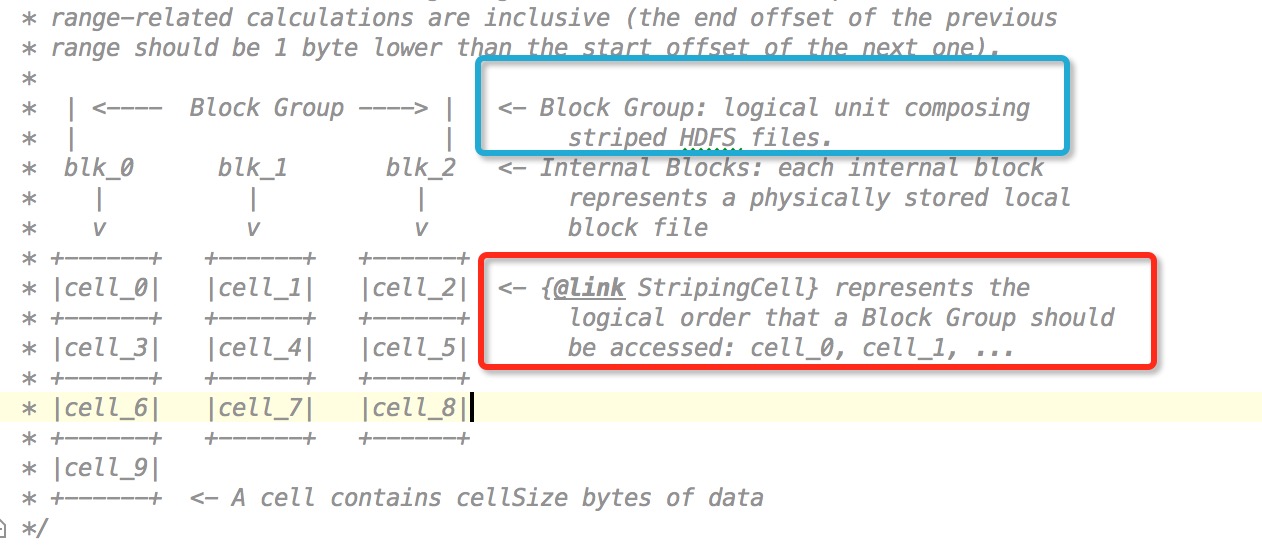
- Block Group的组概,图中蓝色矩阵中的部分,逻辑上代表者一个hdfs文件.
- cell概念,就是从逻辑上将每个block块进行cell大小的拆分,因为不同block大小不同,所以不同block块的cell数量可能也会不同.
中间的internal blocks才是最终存储数据的block块,也就是我们平常说的HDFS中的block块.
stripe的大小在HDFS中的计算逻辑如下:
- 1
- 2
- 1
- 2
就是一行的大小.获取block长度的实现逻辑如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果恰好最后一行stripe长度为0,则说明每个block长度相等,直接返回即可,否则还要另外加上lastCellSize的大小.
HDFS Erasure Coding实现
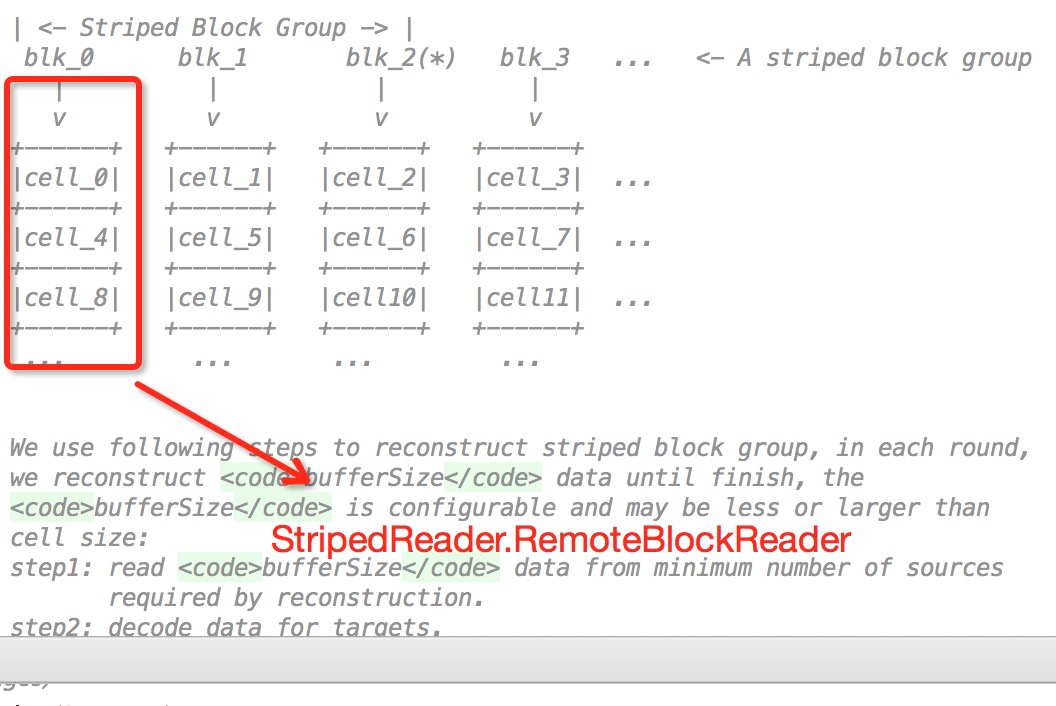
了解了上述提到的概念,就可以开始真正了解ec在hdfs的实现,实现步骤主要在ErasureCodingWorker#ReconstructAndTransferBlock类中.从注释中可以看出,主要分为3大步.
- step1: read
bufferSizedata from minimum number of sources required by reconstruction. - step2: decode data for targets.
- step3: transfer data to targets.
现在我们一步一步的来看.
Step1
看官方注释中对第一步骤的描述:
- 1
- 1
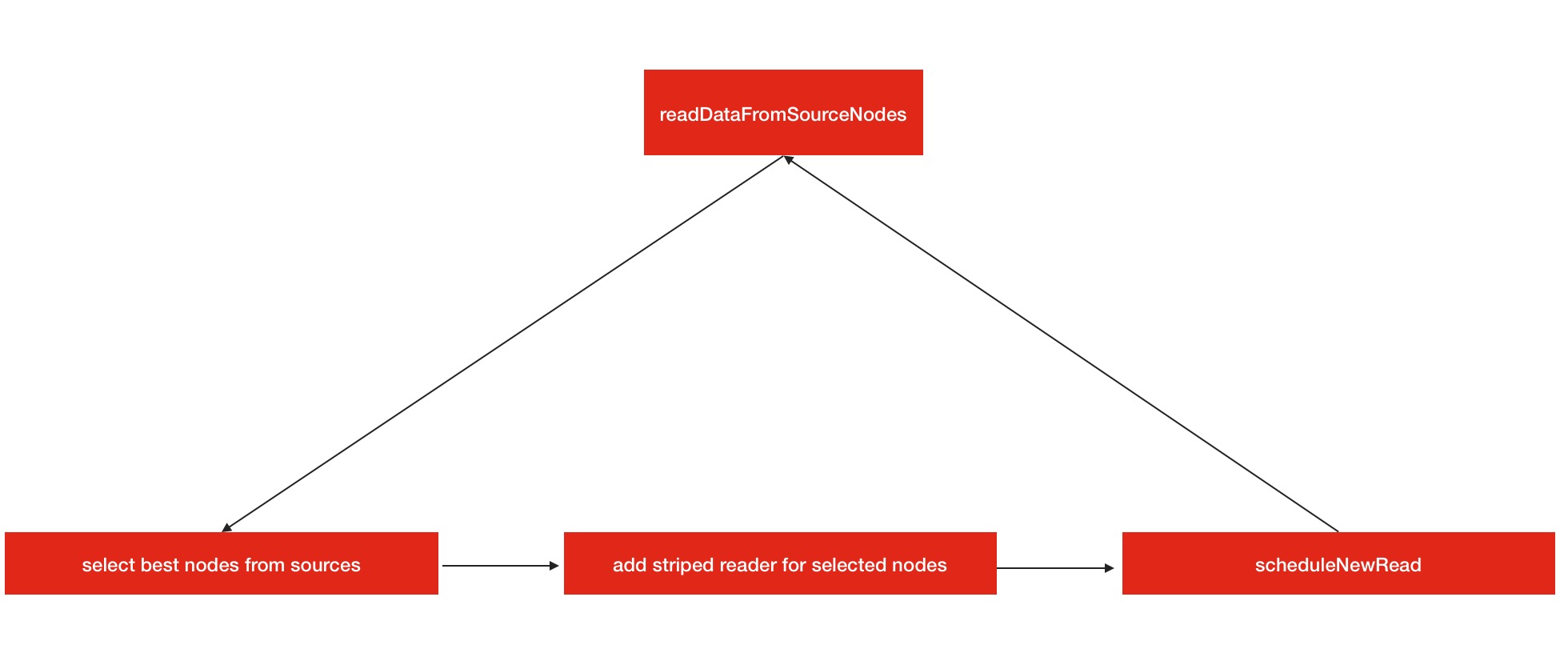
概况的说,就是他首先会从sources node源节点中选出符合最好的n个节点,如果节点中有坏的或是慢节点,则会重新进行选择一次,代码如下
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后会对每个source node新建相应的striperReader进行远程读,远程读会用到striperReader的blockReader和buffer缓冲.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
图形展示效果如下
因为第一步骤的子步骤比较多一些,所以我制作了执行顺序图
Step2
同样给出官方源码注释
- 1
- 2
- 1
- 2
第二个步骤主要在于编解码数据的过程.第一个步骤已经把数据读到缓冲区了,第二步就是计算的过程了.这里提到了很关键的一点.
- 1
- 1
编解码的决定要依靠于恢复的对象决定的,与之前在上半篇幅中提到的原则是一致的.相关代码如下
- 1
- 2
- 1
- 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
但是在这里我有一点疑惑,这里直接使用的decode解码的操作,可能在这种使用场景下都是解码的情况.
Step3
第三步骤就很简单了,就是transfering data的操作,将buffer中的缓冲数据写入到目标节点即可.
- 1
- 1
写的方式很简单,直接远程写即可,因为此类写操作只涉及到1个节点,无须构建后续pipeline的动作.此方面可以阅读我的另外一篇博文从DFSOutputStream的pipeline写机制到Streamer线程泄漏问题.
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
OK,以上就是Hadoop 3.0中EC数据恢复技术的一个主要实现.一张完整的顺序图如下

改进优化点
在官方注释中已经提到了2个改进点,在后续应该会被完善.
- 目前的数据没有采用本地读的方式,一律用远程方式进行数据读取.
- 目标数据恢复传输没有返回packet数据包的ack确认码,不像pipeline那样有很健全的一套体系.
相关链接
在学习Erasure Coding技术的过程中,查看了很多的资料,并且提交了一个Issue给社区,HDFS-9832.顺便说一句,我是去年9月开始接触Hadoop社区的,参与开源的过程使我对Hadoop的了解程度比以往更加深入了一层,这点感受确实很深.最后希望大家多多参与开源,了解开源,向开源社区做出自己的贡献.
1.wiki Erasure Coding: https://en.wikipedia.org/wiki/Erasure_code
2.http://www.searchstorage.com.cn/whatis/word_6080.htm
3.http://blog.sina.com.cn/s/blog_3fe961ae0102vpxr.html
4.Issue 链接: https://issues.apache.org/jira/browse/HDFS-9832
5.Github patch链接:
https://github.com/linyiqun/open-source-patch/tree/master/hdfs/HDFS-9832
-
顶
- 0















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









