







Huffman编码是一种无损压缩编码方案。
思想:根据源字符出现的(估算)概率对字符编码,概率搞的字符使用较短的编码,概率低的使用较长的编码,从而使得编码后的字符串长度期望最小。
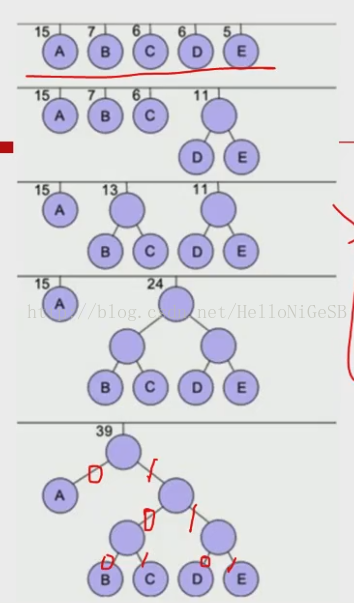
Huffman编码是一种贪心算法:每次总选择两个最小概率的字符结点结合。
算法演示称字符出现的次数为频数,则概率约等于频数初一字符总长,因此,概率可以用频数代替。
注:二叉树中结点有三种情况,1、结点为两个孩子的结点N2,。2、结点为1个孩子的结点N1。3、结点为0个孩子的N0。所以总变数为2*N2 + N1 + 0 * N0,又因为边数的另一种表达形式为N2+N1+N0-1,所以可以得到N2+N1+N0-1 = 2*N2 + N1 + 0 * N0,合并同类项后为N2 = N0 - 1,又因为哈夫曼树不会存在N1的结点,所以哈夫曼的非叶子节点数n = N0(叶子节点数) - 1。总结点数为2*N0 - 1.
#include "stdafx.h"
#include <iostream>
#include <vector>
typedef struct HuffmanNode
{
int nWeight;
int nParent;
int nLeft;
int nRight;
HuffmanNode* m_pRight;
HuffmanNode() : nWeight(0), nParent(0), nLeft(0), nRight(0){}
}HuffmanNode;
void CalcFrequency(const char* str, int* pWeight)
{
while (*str)
{
pWeight[*str]++;
str++;
}
}
void CalcExistChar(int* pWeight, int N, std::vector<int>& pChar)
{
int j = 0;
for (int i = 0; i < N; i++)
{
if (pWeight[i] != 0)
{
pChar.push_back(i);
if (j != i)
{
pWeight[j] = pWeight[i];
}
j++;
}
}
}
void SelectNode(const HuffmanNode* pHuffmanTree, int n, int& s1, int& s2)
{
s1 = -1;
s2 = -1;
int nMin1 = -1;
int nMin2 = -1;
for (int i = 0; i < n; i++)
{
if ((pHuffmanTree[i].nParent == 0) && (pHuffmanTree[i].nWeight > 0))
{
if ((s1 < 0) || (nMin1 > pHuffmanTree[i].nWeight))
{
s2 = s1;
nMin2 = nMin1;
s1 = i;
nMin1 = pHuffmanTree[s1].nWeight;
}
else if ((s2 < 0) || (nMin2 > pHuffmanTree[i].nWeight))
{
s2 = i;
nMin2 = pHuffmanTree[s2].nWeight;
}
}
}
}
void HuffmanCoding(int* pWeight, int N, std::vector<std::vector<char>>& code)
{
if (N < 0)
return;
int m = 2 * N - 1; // N个结点的Huffman树需要2N-1个结点
HuffmanNode* pHuffmanTree = new HuffmanNode[m];
int s1, s2;
int i;
// 建立叶子节点
for (i = 0; i < N; i++)
{
pHuffmanTree[i].nWeight = pWeight[i];
}
// 每次选择权值最小的两个结点,建树
for (i = N; i < m; i++)
{
SelectNode(pHuffmanTree, i, s1, s2);
pHuffmanTree[s1].nParent = pHuffmanTree[s2].nParent = i;
pHuffmanTree[i].nLeft = s1;
pHuffmanTree[i].nRight = s2;
pHuffmanTree[i].nWeight = pHuffmanTree[s1].nWeight + pHuffmanTree[s2].nWeight;
}
// 根据建好的Huffman树从叶子到根计算每个叶节点的编码
int node, nParent;
for (i = 0; i < N; i++)
{
std::vector<char>& cur = code[i];
node = i;
nParent = pHuffmanTree[node].nParent;
while (nParent != 0)
{
if (pHuffmanTree[nParent].nLeft == node)
{
cur.push_back('0');
}
else
{
cur.push_back('1');
}
node = nParent;
nParent = pHuffmanTree[node].nParent;
}
reverse(cur.begin(), cur.end());
}
}
void PrintCode(char c, std::vector<char>& code)
{
std::cout<<(int)c<<" "<<c<<": ";
for (std::vector<char>::iterator it = code.begin(); it != code.end(); it++)
{
std::cout<<*it;
}
std::cout<<'\n';
}
void Print(std::vector<std::vector<char>>& code, std::vector<int>& pChar)
{
int size = (int)code.size();
for (int i = 0; i < size; i++)
{
PrintCode(pChar[i], code[i]);
}
}
int _tmain(int argc, _TCHAR* argv[])
{
const int N =256;
char str[] = "when I was young I'd listen to the radio\
waiting for my favorite songs\
when they p;ayed I'd sing along.\
it make me smile.\
those were such happy times and not so long ago\
how I wonder where they'd gone.\
but they're back again just like a long lost friend\
all the songs I love so well.\
still shines.\
eveyry shing-a-ling-a-ling\
that they're starting\
to sing so fine";
int pWeight[N] = {0};
CalcFrequency(str, pWeight);
pWeight['\t'] = 0;
std::vector<int> pChar;
CalcExistChar(pWeight, N, pChar);
int N2 = (int)pChar.size();
std::vector<std::vector<char>> code(N2);
HuffmanCoding(pWeight, N2, code);
Print(code, pChar);
system("pause");
return 0;
}
Huffman编码总结:前缀编码
Huffman编码是不等长编码,字符的编码长度不完全相同。
不等长编码如果需要译码,必须满足“前缀编码”的条件:任何一个字符的编码都不是另外一个字符的编码的前缀。
非前缀编码例如:
因为Huffman编码时候每个目标编码对象最后都是叶子节点,不可能出现某个成为另一个的前缀,可以参看上面图例即可得出字符串:ABBC
使用编码方案:A:0 B:1 C:00
则,ABBC的编码为01100
01100的译码可以是ABBC也可以是ABBAA。
Huffman实现带来的思考
Huffman编码是如何解决前缀编码问题的?
实际算法往往是由多个“小算法”堆砌而成的
代码实现中并非直接使用指针形成的二叉树结点。而是实现开辟足够大的缓冲空间(2n+1),每次从缓冲区获取一个结点,使用数组代替二叉树。空格压缩问题
取数组最大/小的两个数,这个是不是有更快的算法么?(优先队列)
在堆排序、双数组Trie树结构等问题会再次遇到。
由于Huffman树的结点权值(频数)可能相等,因此对某些文本,Huffman编码不唯一。
左赋1,右赋0或者左赋0,右赋1都可以。














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









