



在大模型的世界里,参数往往动辄上亿,但其实并不是所有参数更新都同样重要。低维固有维度假设告诉我们:模型真正需要的有效更新,其实存在于一个比全量参数空间小得多的低维子空间里。换句话说,并不需要把所有参数都调一遍,就能取得和全量微调差不多的效果。基于这个思路,低秩适配(Low-rank Adaptation,LoRA)诞生了。它的核心做法是用低秩矩阵去近似原始的权重更新矩阵,并且只训练这部分低秩矩阵,从而在不牺牲性能的前提下,大幅减少需要更新的参数量。接下来,我们会先聊聊 LoRA 的实现细节和它在参数效率上的优势,再带大家看看一些 LoRA 的常见变体,最后再说说 LoRA 的“插件化”特性,以及它在任务泛化上的潜力。
1 LoRA
低秩适配(Low-rank Adaptation, LoRA) 提出利用低秩矩阵近似参数更新矩阵来实现低秩适配。该方法将参数更新矩阵低秩分解为两个小矩阵。在微调时,通过微调这两个小矩阵来对大语言模型进行更新,大幅节省了微调时的内存开销。
1) 方法实现
给定一个密集神经网络层,其参数矩阵为 W0 ∈ Rd×k,为适配下游任务,我们通常需要学习参数更新矩阵 ∆W ∈ Rd×k,对原始参数矩阵进行更新 W = W0 + ∆W。对于全量微调过程,∆W 是需对该层所有 d × k 个参数计算梯度,这通常需要大量的 GPU 内存,成本高昂。为解决这一问题,如上图,LoRA 将 ∆W 分解为两个低参数量的矩阵 B ∈ Rd×r 和 A ∈ Rr×k,使得更新过程变为:
W = W0 + αBA
其中,秩 r ≪ min{d, k},B 和 A 分别用随机高斯分布和零进行初始化,α 是缩放因子,用于控制 LoRA 权重的大小。在训练过程中,固定预训练模型的参数,仅微调 B 和 A 的参数。因此,在训练时,LoRA 涉及的更新参数数量为 r × (d + k),远小于全量微调 d × k。实际上,对于基于 Transformer 的大语言模型,密集层通常有两种类型:注意力模块中的投影层和前馈神经网络(FFN)模块中的投影层。在原始研究中,LoRA 被应用于注意力层的权重矩阵。后续工作表明将其应用于 FFN层可以进一步提高模型性能。
LoRA 仅微调部分低秩参数,因此具有很高的参数效率,同时不会增加推理延迟。此外,低秩矩阵还可以扩展为低秩张量,或与 Kronecker 分解结合使用,以进一步提高参数效率。除了参数效率外,在训练后可以将 LoRA 参数与模型参数分离,所以 LoRA 还具有可插拔性。LoRA 的可插拔特性使其能够封装为被多个用户共享和重复使用的插件。当我们有多个任务的 LoRA 插件时,可以将这些插件组合在一起,以获得良好的跨任务泛化性能。
2)参数效率
我们以一个具体的案例分析 LoRA 的参数效率。在 LLaMA2-7B模型中微调第一个 FFN 层的权重矩阵为例:
全量微调需要调整 11, 008 × 4, 096 =45, 088, 768 个参数。
而当 r = 4 时,LoRA 只需调整
(11, 008 × 4) + (4 × 4, 096) =60, 416 个参数
对于这一层,与全量微调相比,LoRA 微调的参数不到原始参数量的千分之一。具体来说,模型微调的内存使用主要涉及四个部分:
权重内存(Weight Memory):用于存储模型权重所需的内存;
激活内存(Activation Memory):前向传播内存时中间激活带来的显存占用,主要取决于 batch size 大小以及序列长度等;
梯度内存(Gradient Memory):在反向传播期间需要用来保存梯度的内存,这些梯度仅针对可训练参数进行计算;
优化器内存(Optimization Memory):用于保存优化器状态的内部存在。例如,Adam 优化器会保存可训练参数的 “一阶动量” 和 “二阶动量”
根据实验结果,全量微调大约需要 60GB 显存,超出 RTX4090 的显存容量。相比之下,LoRA 只需要大约 23GB 显存。LoRA 显著减少了显存使用,使得在单个 NVIDIA RTX4090 上进行LLaMA2-7B 微调成为可能。具体来说,由于可训练参数较少,优化器内存和梯度内存分别减少了约 25GB 和 14GB。另外,虽然 LoRA 引入了额外的 “增量参数,导致激活内存和权重内存略微增加(总计约 2GB),但考虑到整体内存的减少,这种增加是可以忽略不计的。此外,减少涉及到的参数计算可以加速反向传播。与全量微调相比,LoRA 的速度提高了 1.9 倍。
2 LoRA 相关变体
虽然 LoRA 在不少下游任务上表现不错,但在一些更复杂的场景(比如数学推理中,它和全量微调之间依然存在差距。为了缩小这个差距,研究者们提出了很多 LoRA 的改进版本,试图进一步提升它在下游任务中的适配能力。总体来看,这些变体主要集中在三个方向:一是突破传统低秩分解的限制;二是根据任务需求进行动态的秩分配;三是在训练方式上做优化。接下来,我们就来分别看看这三类思路的代表性方法。
1)打破低秩瓶颈
LoRA 的低秩更新特性使其在参数效率上具有优势;然而,这也限制了大规模语言模型记忆新知识和适应下游任务的能力,即存在低秩瓶颈。Biderman 等人的实验研究表明,全量微调的秩显著高于 LoRA 的秩(10-100倍),并且增加 LoRA 的秩可以缩小 LoRA 与全量微调之间的性能差距。因此,一些方法被提出,旨在打破低秩瓶颈。
例如,ReLoRA 提出了一种合并和重置(merge-and-reinit)的方法,该方法在微调过程中周期性地将 LoRA 模块合并到大语言模型中,并在合并后重新初始化 LoRA 模块和优化器状态。具体地,合并的过程如下:
Wi ← Wi + αBiAi
其中,Wi 是原始的权重矩阵,Bi 和 Ai 是低秩分解得到的矩阵,α 是缩放因子。合并后,将重置 Bi 和 Ai 的值重置,通常 Bi 会使用特定的初始化方法(如 Kaiming 初始化)重新初始化,而 Ai 则被设置为零。为了防止在重置后模型性能发散,ReLoRA还会通过幅度剪枝对优化器状态进行部分重置。合并和重置的过程允许模型在保持总参数量不变的情况下,通过多次低秩 LoRA 更新累积成高秩状态,从而使得ReLoRA 能够训练出性能接近全秩训练的模型。
2)动态秩分配
在 LoRA 里,秩(rank)是一个很关键的超参数。一般来说,我们会觉得秩越高,模型越强大,但其实并不是这样。秩太高反而可能带来冗余,导致训练效率和模型性能下降。更复杂的是,Transformer 的不同层对任务的贡献并不一样,有的层可能需要更高的秩,有的层只需要很低的秩。所以,一个统一的固定秩并不一定是最优解。
为了解决这个问题,就有了 AdaLoRA。它的思路是:动态地给每一层分配不同的秩。具体做法是这样的:
-
重新表示参数更新矩阵
在普通 LoRA 里,更新矩阵 ΔW 是通过两个低秩矩阵分解得到的。而 AdaLoRA 则用 奇异值分解(SVD) 来表示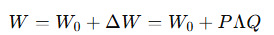

换句话说,ΔW 的信息现在被拆成了 方向 (P、Q) 和 重要性权重 (Λ)
2.动态剪枝奇异值
在训练过程中,AdaLoRA 会不断估计每个奇异值的重要性(用梯度相关的指标来衡量)。如果发现某些奇异值对任务没什么帮助,就会把它们剪掉,这样对应的秩就会降低。反之,如果需要更高秩的层,就会保留更多奇异值。这样,每一层的秩是动态调整的,而不是一刀切。
3.保持训练稳定性
为了让训练不跑偏,AdaLoRA 还加了一个“正交约束”的惩罚项,保证 P 和 Q 始终接近正交矩阵(像一组正交坐标系)。这个约束用 Frobenius 范数来度量偏离程度。
3)训练过程优化
虽然 LoRA 在节省参数上很有优势,但它有几个实际问题:
-
收敛速度往往比全量微调慢;
-
对超参数(比如学习率、秩)比较敏感;
-
有时候容易过拟合。
这些问题会影响 LoRA 的效果。于是有人提出了改进版 :
DoRA(Decomposed Low-Rank Adaptation,权重分解低秩适应)。
DoRA 的核心思路
DoRA 的关键点在于:把权重矩阵拆成“方向”和“大小”两个部分,只对方向做 LoRA 的更新。这样能让训练更稳定,同时避免过拟合。
具体怎么做呢?

最终权重 =大小(固定的 m)x归一化后的方向(原方向 V + 更新 △V
这样一来,训练只改变方向,不随意放大缩小大小,能让优化过程更稳定。
3 基于 LoRA 插件的任务泛化
在用 LoRA 微调模型时,我们其实只训练了两个小矩阵 AAA 和 BBB。微调完成后,这两个矩阵就相当于 “任务专属的参数补丁”。
好处是:
-
原始模型的参数 不变,不会被破坏;
-
这些 A,BA, BA,B 模块可以被 单独保存,就像插件一样;
-
想用的时候直接“插”到大模型里就行,非常灵活。
这样一来,不同任务就可以各自对应一个 LoRA 插件,我们既能保存、共享这些插件,还能在需要时随时切换。
不仅如此,我们还能把多个任务的 LoRA 插件 组合起来,让模型同时具备多种任务能力。这就是 LoRAHub 提出的思路。
LoRAHub 的流程分成 两个阶段:
 然后通过反复迭代,找到最合适的组合权重;
然后通过反复迭代,找到最合适的组合权重;
最后得到一个能适配新任务的组合 LORA 模块
介绍了低秩适配方法 LoRA。LoRA 通过对参数矩阵进行低秩分解,仅训练低秩矩阵,大幅减少了训练参数量。此外,还介绍了从打破低秩瓶颈、动态秩分配和训练过程优化等不同角度改进 LoRA 的变体。最后,介绍了基于 LoRA 插件的任务泛化方法 LoRAHub。LoRAHub 通过对已学习的 LoRA 模块加权组合,融合多任务能力并迁移到新任务上,提供了一种高效的跨任务学习范式。



















 2219
2219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











