







实现LRU淘汰算法
LRU 缓存算法是一个非常经典的算法,在很多面试中经常问道,不仅仅包括前端面试
LRU英文全称是Least Recently Used,英译过来就是” 最近最少使用 “的意思。LRU是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间t,当须淘汰一个页面时,选择现有页面中其t值最大的,即最近最少使用的页面予以淘汰
通俗的解释:
假如我们有一块内存,专门用来缓存我们最近发访问的网页,访问一个新网页,我们就会往内存中添加一个网页地址,随着网页的不断增加,内存存满了,这个时候我们就需要考虑删除一些网页了。这个时候我们找到内存中最早访问的那个网页地址,然后把它删掉。这一整个过程就可以称之为
LRU算法
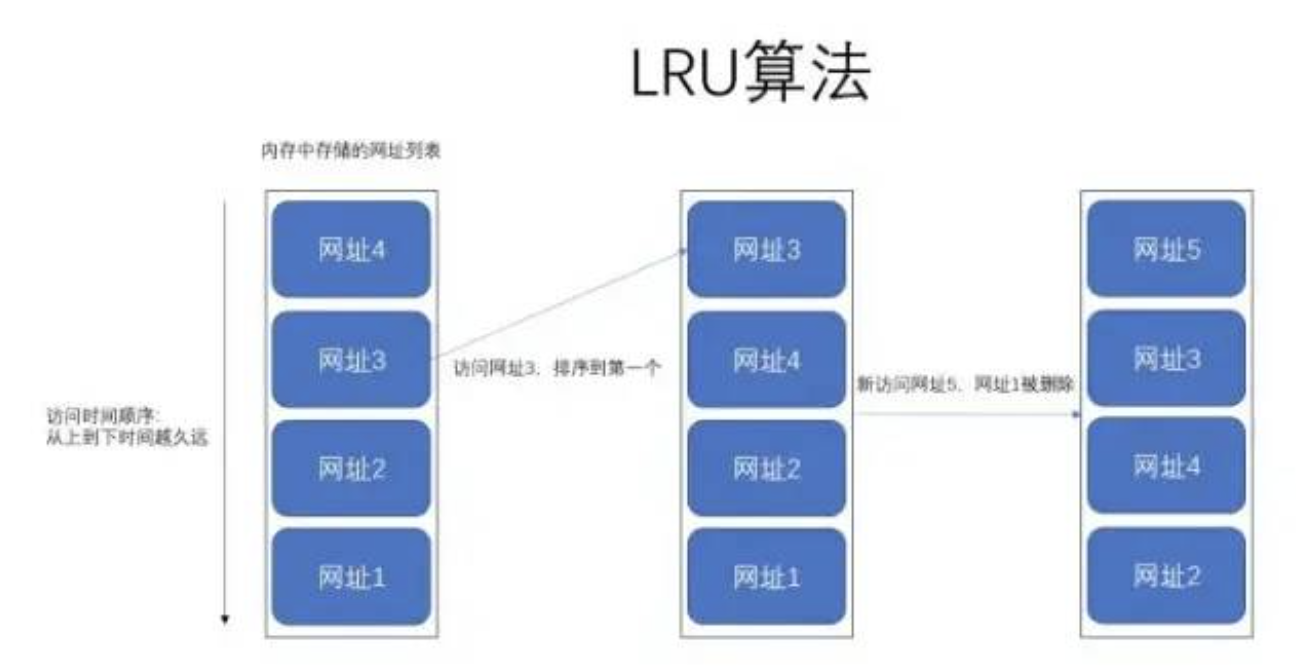
上图就很好的解释了 LRU 算法在干嘛了,其实非常简单,无非就是我们往内存里面添加或者删除元素的时候,遵循最近最少使用原则
使用场景
LRU 算法使用的场景非常多,这里简单举几个例子即可:
- 我们操作系统底层的内存管理,其中就包括有
LRU算法 - 我们常见的缓存服务,比如
redis等等 - 比如浏览器的最近浏览记录存储
vue中的keep-alive组件使用了LRU算法
梳理实现 LRU 思路
- 特点分析:
- 我们需要一块有限的存储空间,因为无限的化就没必要使用
LRU算发删除数据了。 - 我们这块存储空间里面存储的数据需要是有序的,因为我们必须要顺序来删除数据,所以可以考虑使用
Array、Map数据结构来存储,不能使用Object,因为它是无序的。 - 我们能够删除或者添加以及获取到这块存储空间中的指定数据。
- 存储空间存满之后,在添加数据时,会自动删除时间最久远的那条数据。
- 我们需要一块有限的存储空间,因为无限的化就没必要使用
- 实现需求:
- 实现一个
LRUCache类型,用来充当存储空间 - 采用
Map数据结构存储数据,因为它的存取时间复杂度为O(1),数组为O(n) - 实现
get和set方法,用来获取和添加数据 - 我们的存储空间有长度限制,所以无需提供删除方法,存储满之后,自动删除最久远的那条数据
- 当使用
get获取数据后,该条数据需要更新到最前面
- 实现一个
具体实现
class LRUCache {
constructor(length) {
this.length = length; // 存储长度
this.data = new Map(); // 存储数据
}
// 存储数据,通过键值对的方式
set(key, value) {
const data = this.data;
if (data.has(key)) {
data.delete(key)
}
data.set(key, value);
// 如果超出了容量,则需要删除最久的数据
if (data.size > this.length) {
const delKey = data.keys().next().value;
data.delete(delKey);
}
}
// 获取数据
get(key) {
const data = this.data;
// 未找到
if (!data.has(key)) {
return null;
}
const value = data.get(key); // 获取元素
data.delete(key); // 删除元素
data.set(key, value); // 重新插入元素
return value // 返回获取的值
}
}
var lruCache = new LRUCache(5);
set 方法:往map里面添加新数据,如果添加的数据存在了,则先删除该条数据,然后再添加。如果添加数据后超长了,则需要删除最久远的一条数据。data.keys().next().value便是获取最后一条数据的意思。get 方法:首先从map对象中拿出该条数据,然后删除该条数据,最后再重新插入该条数据,确保将该条数据移动到最前面
// 测试
// 存储数据 set:
lruCache.set('name', 'test');
lruCache.set('age', 10);
lruCache.set('sex', '男');
lruCache.set('height', 180);
lruCache.set('weight', '120');
console.log(lruCache);
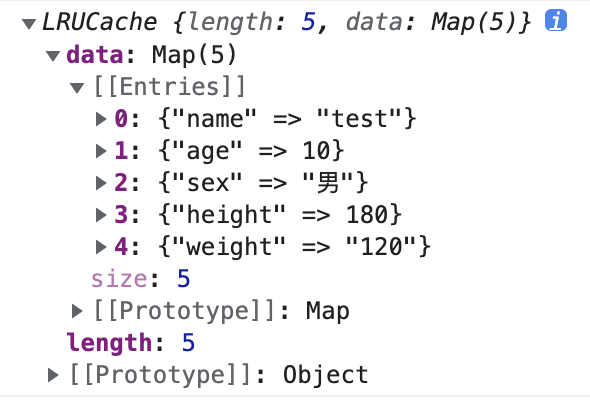
继续插入数据,此时会超长,代码如下:
lruCache.set('grade', '100');
console.log(lruCache);

此时我们发现存储时间最久的 name 已经被移除了,新插入的数据变为了最前面的一个。
我们使用 get 获取数据,代码如下:

我们发现此时 sex 字段已经跑到最前面去了
总结
LRU算法其实逻辑非常的简单,明白了原理之后实现起来非常的简单。最主要的是我们需要使用什么数据结构来存储数据,因为map的存取非常快,所以我们采用了它,当然数组其实也可以实现的。还有一些小伙伴使用链表来实现LRU,这当然也是可以的。
将虚拟 Dom 转化为真实 Dom
{
tag: 'DIV',
attrs:{
id:'app'
},
children: [
{
tag: 'SPAN',
children: [
{
tag: 'A', children: [] }
]
},
{
tag: 'SPAN',
children: [
{
tag: 'A', children: [] },
{
tag: 'A', children: [] }
]
}
]
}
把上面虚拟Dom转化成下方真实Dom
<div id="app">
<span>
<a></a>
</span>
<span>
<a></a>
<a></a>
</span>
</div>
实现
// 真正的渲染函数
function _render(vnode) {
// 如果是数字类型转化为字符串
if (typeof vnode === "number") {
vnode = String(vnode);
}
// 字符串类型直接就是文本节点
if (typeof vnode === "string") {
return document.createTextNode(vnode);
}
// 普通DOM
const dom = document.createElement(vnode.tag);
if (vnode.attrs) {
// 遍历属性
Object.keys(vnode.attrs).forEach((key) => {
const value = vnode.attrs[key];
dom.setAttribute(key, value);
});
}
// 子数组进行递归操作
vnode.children.forEach((child) => dom.appendChild(_render(child)));
return dom;
}
实现一个迭代器生成函数
ES6对迭代器的实现
JS原生的集合类型数据结构,只有Array(数组)和Object(对象);而ES6中,又新增了Map和Set。四种数据结构各自有着自己特别的内部实现,但我们仍期待以同样的一套规则去遍历它们,所以ES6在推出新数据结构的同时也推出了一套 统一的接口机制 ——迭代器(Iterator)。
ES6约定,任何数据结构只要具备Symbol.iterator属性(这个属性就是Iterator的具体实现,它本质上是当前数据结构默认的迭代器生成函数),就可以被遍历——准确地说,是被for...of...循环和迭代器的next方法遍历。 事实上,for...of...的背后正是对next方法的反复调用。
在ES6中,针对Array、Map、Set、String、TypedArray、函数的 arguments 对象、NodeList 对象这些原生的数据结构都可以通过for...of...进行遍历。原理都是一样的,此处我们拿最简单的数组进行举例,当我们用for...of...遍历数组时:
const arr = [1, 2, 3]
const len = arr.length
for(item of arr) {
console.log(`当前元素是${
item}`)
}
之所以能够按顺序一次一次地拿到数组里的每一个成员,是因为我们借助数组的
Symbol.iterator生成了它对应的迭代器对象,通过反复调用迭代器对象的next方法访问了数组成员,像这样:
const arr = [1, 2, 3]
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 对迭代器对象执行next,就能逐个访问集合的成员
iterator.next()
iterator.next()
iterator.next()
丢进控制台,我们可以看到next每次会按顺序帮我们访问一个集合成员:
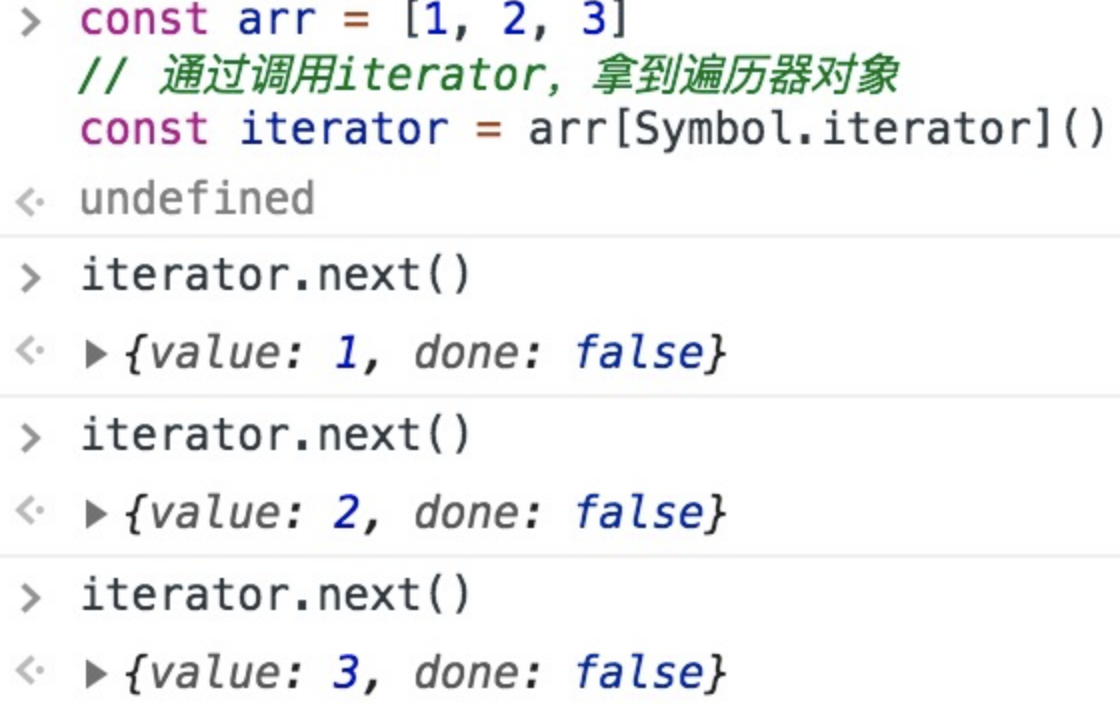
而
for...of...做的事情,基本等价于下面这通操作:
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 初始化一个迭代结果
let now = {
done: false }
// 循环往外迭代成员
while(!now.done) {
now = iterator.next()
if(!now.done) {
console.log(`现在遍历到了${
now.value}`)
}
}
可以看出,
for...of...其实就是iterator循环调用换了种写法。在ES6中我们之所以能够开心地用for...of...遍历各种各种的集合,全靠迭代器模式在背后给力。
ps:此处推荐阅读迭代协议 (opens new window),相信大家读过后会对迭代器在ES6中的实现有更深的理解。
实现深拷贝
简洁版本
简单版:
const newObj = JSON.parse(JSON.stringify(oldObj));
局限性:
- 他无法实现对函数 、RegExp等特殊对象的克隆
- 会抛弃对象的
constructor,所有的构造函数会指向Object - 对象有循环引用,会报错
面试简版
function deepClone(obj) {
// 如果是 值类型 或 null,则直接return
if(typeof obj !== 'object' || obj === null) {
return obj
}
// 定义结果对象
let copy = {
}
// 如果对象是数组,则定义结果数组
if(obj.constructor === Array) {
copy = []
}
// 遍历对象的key
for(let key in obj) {
// 如果key是对象的自有属性
if(obj.hasOwnProperty(key)) {
// 递归调用深拷贝方法
copy[key] = deepClone(obj[key])
}
}
return copy
}
调用深拷贝方法,若属性为值类型,则直接返回;若属性为引用类型,则递归遍历。这就是我们在解这一类题时的核心的方法。
进阶版
- 解决拷贝循环引用问题
- 解决拷贝对应原型问题
// 递归拷贝 (类型判断)
function deepClone(value,hash = new WeakMap){
// 弱引用,不用map,weakMap更合适一点
// null 和 undefiend 是不需要拷贝的
if(value == null){
return value;}
if(value instanceof RegExp) {
return new RegExp(value) }
if(value instanceof Date) {
return new Date(value) }
// 函数是不需要拷贝
if(typeof value != 'object') return value;
let obj = new value.constructor(); // [] {}
// 说明是一个对象类型
if(hash.get(value)){
return hash.get(value)
}
hash.set(value,obj);
for(let key in value){
// in 会遍历当前对象上的属性 和 __proto__指代的属性
// 补拷贝 对象的__proto__上的属性
if(value.hasOwnProperty(key)){
// 如果值还有可能是对象 就继续拷贝
obj[key] = deepClone(value[key],hash);
}
}
return obj
// 区分对象和数组 Object.prototype.toString.call
}
// test
var o = {
};
o.x = o;
var o1 = deepClone(o); // 如果这个对象拷贝过了 就返回那个拷贝的结果就可以了
console.log(o1);
实现完整的深拷贝
1. 简易版及问题
JSON.parse(JSON.stringify());
估计这个api能覆盖大多数的应用场景,没错,谈到深拷贝,我第一个想到的也是它。但是实际上,对于某些严格的场景来说,这个方法是有巨大的坑的。问题如下:
- 无法解决
循环引用的问题。举个例子:
const a = {
val:2};
a.target = a;
拷贝
a会出现系统栈溢出,因为出现了无限递归的情况。
- 无法拷贝一些特殊的对象,诸如
RegExp, Date, Set, Map等 - 无法拷贝
函数(划重点)。
因此这个api先pass掉,我们重新写一个深拷贝,简易版如下:
const deepClone = (target) => {
if (typeof target === 'object' && target !== null) {
const cloneTarget = Array.isArray(target) ? []: {
};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepClone(target[prop]);
}
}
return cloneTarget;
} else {
return target;
}
}
现在,我们以刚刚发现的三个问题为导向,一步步来完善、优化我们的深拷贝代码。
2. 解决循环引用
现在问题如下:
let obj = {
val : 100};
obj.target = obj;
deepClone(obj);//报错: RangeError: Maximum call stack size exceeded
这就是循环引用。我们怎么来解决这个问题呢?
创建一个Map。记录下已经拷贝过的对象,如果说已经拷贝过,那直接返回它行了。
const isObject = (target) => (typeof target === 'object' || typeof target === 'function' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









