







第八章 查找
提前了解:
1、关键字: 若关键字能唯一标识一个数据元素,则关键字称为主关键字;若能标识若干个数据元素的关键字称为次关键字;
2、查找(检索):顾名思义,给定一个值,进行查找;若存在值则查找成功,反之查找失败;
3、查找方法评价指标:其中pᵢ为查找第i个记录的概率;cᵢ查找第i个记录需要进行比较的次数;

一、静态查找
1、定义:在查找时只对数据元素进行查询或检索,查找表称为静态查找表;
2、顺序查找:给定值,挨个找,从大往小比;
- 算法分析:
- 查找成功时的平均查找长度ASL;
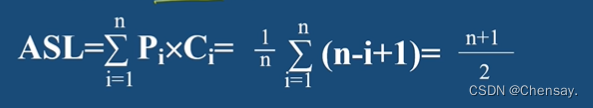
- 查找不成功时ASL=3(n+1)/4;
- 查找成功时的平均查找长度ASL;
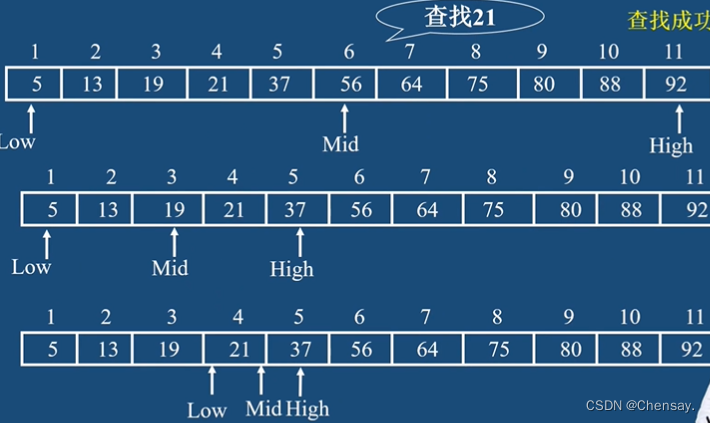
3、折半查找(二分查找):效率高;查找表中的所有记录都是按照关键字有序或者降序排好的;查找时都是将待查记录所在的区间缩一半,直到找到或者找不到为止;查找成功时ASL=n+1/n·log₂(n+1)-1,但n>50时,ASL=log₂(n+1);
- 查找思想:采用Mid、Low、Hight指针;和二分排序差不多;Mid=(Low+Hight)/2取下整(就是数学里的取中位数);
4、散列查找
二、动态查找
1、定义:在实施查找的同时,插入查找表中不存在的记录,或从查找表中删除已存在的某个记录,查找表称为动态查找表;
2、二叉排序树的查找:找最大值即为右子树最后的结点值,找最小值即左节点最后的结点值;或为空,或具有以下性质;
- 左子树不为空即所有左子树上的结点都小于根结点的值;
- 右子树不为空即所有右子树上的值大于根结点的值;
- 左右子树也分为二叉排序树;
3、二叉排序树的插入:遇到比根大值往右走,遇到比根小值往左走;

4、二叉排序树的删除:如果被删的结点只有一个子结点,可直接将子结点连到被删结点的父结点上;若被删结点有两结点,那就以右子树内最小的结点代替被删的结点树;
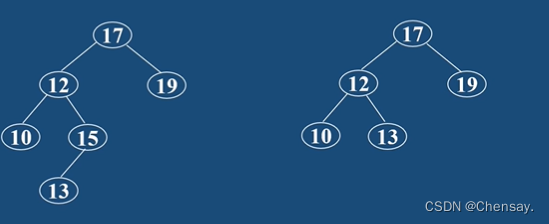
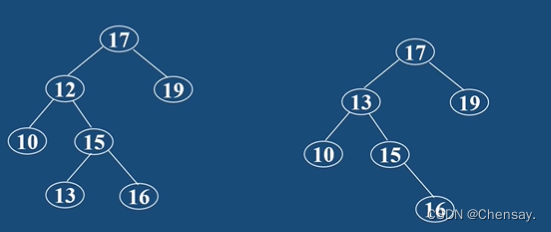
5、二叉排序树的性能分析:插入和删除运行时间为O(H),H为树的高度;
6、二叉排序树的查找如何求ASL:左是等概率的情况,右是最坏的情况;

7、二叉排序树查找算法的平均查找长度ASL,主要取决于树的高度,即与二叉树的形态有关。如果二叉排序树是一个单支树,其平均查找长度与单链表相同,为O(n);如果二叉排序树的左右子树的高度差不超过1,这样的二叉排序树称为平衡二叉树。它的平均查找长度达到O(log₂n)。
8、平衡二叉树:左右子树深度之差不超过1,左右子树也都是平衡二叉树;递归定义;
- 平衡因子:左子树的深度减去右子树的深度则称为该结点的平衡因子;一般只能是-1、0、1;一棵二叉树既是二叉排序树又是平衡二叉树则称为平衡二叉排序树;
- 平衡旋转:保持有序性,又具有平衡性;

- LL型平衡化旋转(右单旋转):若在结点A的左孩子B结点的左子树上插入新结点,则回导致不平衡,那么先保持左孩子B结点和孩子的左子树不动,将它孩子的右子树移到结点A的左边,最后进行右翻转,A结点变成B结点(连带它们的子树一起变);
- LR型平衡化旋转(先左后右双旋转):若在A的左孩子(L)的右子树®上插入了新结点,A的平衡因子由1增至2,导致以A为根失去平衡,需要进行两次旋转操作。先左旋转后右旋转。先将A结点的左孩子B的右子树的根结点C向左上旋转提升到B结点的位置,然后再把该C结点向右上旋转提升到A结点的位置;
- RL平衡旋转(先右后左双旋转):若在A的右孩子®的左子树(L)上插入了新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡,需要进行两次旋转操作。先右旋转后左旋转。先将A结点的右孩子B的左子树的根结点C向右上旋转提升到B结点的位置,然后再把该C结点向左上旋转提升到A结点的位置。RL型平衡化旋转;
- RR平衡旋转(左单旋转):若在A的右孩子®的右子树®上插入了新结点,A的平衡因子由-1减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。将A的右孩子B向左上旋转代替A成为根结点,将A结点向左下旋转成为B的左子树的根结点,而B的原左子树则作为A结点的右子树。
三、散列表
1、哈希函数:简单理解就是你给一个数据,它给你个对应的地址;
2、哈希表:应用哈希函数,由记录的关键字确定记录在表中的地址,并将记录放入此地址,然后构成的表(里头是数据对应着地址位);
3、哈希查找:利用哈希函数进行查找的过程;
4、冲突:两不同数据地址一样;
5、同义词:两不同数据地址一样;
6、设计方法(由于哈希函数通常是一种压缩映象,所以冲突不可避免,只能尽量减少;当冲突发生时,应该有处理冲突的方法)
- 散列表的空间范围,即确定散列函数的值域;
- 构造合适的散列函数,使得对于所有可能的元素(记录的关键字),函数值均在散列表的地址空间范围内,且出现冲突的可能尽量小;
- 处理冲突的方法;即当冲突出现时如何解决。
7、如何构造:只要使任何关键字的哈希函数值都落在表长允许的范围之内即可;
8、评价因素: - 散列函数的构造简单;
- 能“均匀”地将散列表中的关键字映射到地址空间;所谓“均匀”(uniform)是指发生冲突的可能性尽可能最少。
9、方法:直接定址法、数字分析法、除留余数法、冲突处理法;
10、冲突处理方法:开放定址法;
- 线性探测法
- 优点:只要表不满总会找到个地址;
- 缺点:容易聚集(也就是每个冲突的地址都会比较靠近,那么会产生更多的冲突机会);

- 二次探测法(循环的表)
- 优点:探测序列跳跃式地散列到整个表中,不易产生冲突的“聚集”现象;
- 缺点:不能保证探测到散列表的所有地址;

- 再散列法
- 优点:不易产生冲突的“聚集”现象;
- 缺点:计算时间增加;
- 链地址法(简单来说就是余数相同的放一块)
- 优点:不易产生聚集,删除也很简单;
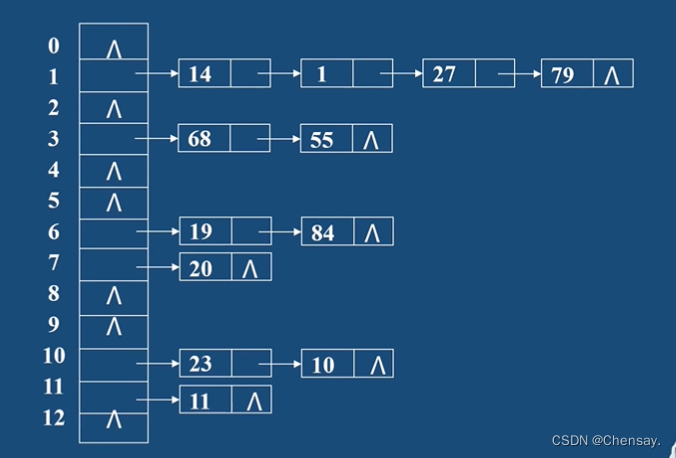
- 优点:不易产生聚集,删除也很简单;
11、散列查找性能分析:尽管散列表在关键字与记录的存储地址之间建立了直接映象,但由于“冲突”,查找过程仍是一个给定值与关键字进行比较的过程,评价哈希查找效率仍要用ASL;
- 哈希查找时关键字与给定值比较的次数取决于:
- 哈希函数;
- 处理冲突的方法;
- 哈希表的填满因子a;
- a=表中填入的记录数/哈希表长度;
12、散列表的ASL总结公式:

13、例题:

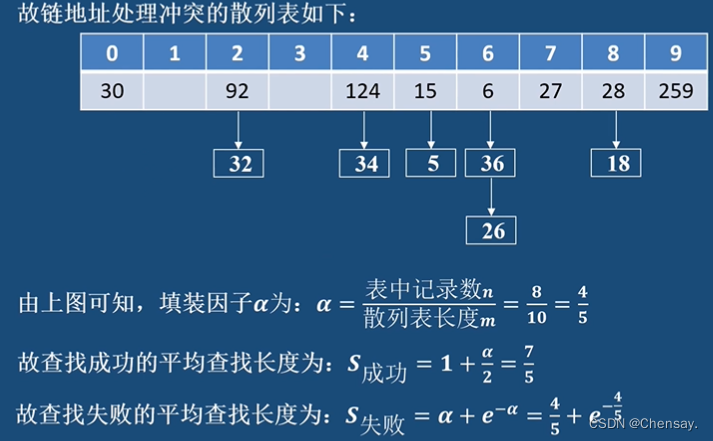















 5511
5511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









