







点间互信息(PMI)主要用于计算词语间的语义相似度,基
本思想是统计两个词语在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。两个词语word1与word2的PMI值计算公式如下式所示为:
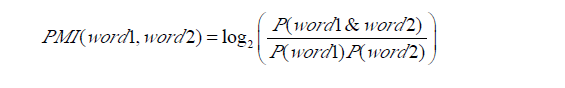
P(word1&word2)表示两个词语word1与word2共同出现的概率,即word1与word2共同出现的文档数, P(word1)与P(word2)分别表示两个词语单独出现的概率,即word出现的文档数。若两个词语在数据集的某个小范围内共现概率越大,表明其关联度越大;反之,关联度越小。P(word1&word2)与P(word1)P(word2)的比值是word1与word2两个词语的统计独立性度量。其值可以转化为3 种状态:
P(word1&word2) > 0;两个词语是相关的;值越大,相关性越强。
P(word1&word2) = 0;两个词语是统计独立的,不相关也不互斥。
P(word1&word2) < 0;两个词语是不相关的,互斥的。
情感倾向点互信息算法(Semantic Orientation Pointwise Mutual Information, SO-PMI)是将PMI方法引入计算词语的情感倾向(Semantic Orientation,简称SO)中,从而达到捕获情感词的目地。基于点间互信息SO-PMI 算法的基本思想是:首先分别选用一组褒义词跟一组贬义词作为基准词,假设分别用Pwords与Nwords来表示这两组词语。这些情感词必须是倾向性非常明显,而且极具领域代表性的词语。若把一个词语word1跟Pwords的点间互信息减去word1跟Nwords的点间互信息会得到一个差值,就可以根据该差
值判断词语word1的情感倾向。其计算公式如下式所示:

通常情况下,将0作为SO-PMI 算法的阀值。由此可以将得到三种状态:
SO-PMI(word1) > 0;为正面倾向,即褒义词
SO-PMI(word1) = 0;为中性倾向,即中性词
SO-PMI(word1) < 0;为负面倾向,即贬义词
参考网址:
http://blog.csdn.net/fighting_one_piece/article/details/39778809
http://blog.csdn.net/liugallup/article/details/51164962















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









