






文章目录
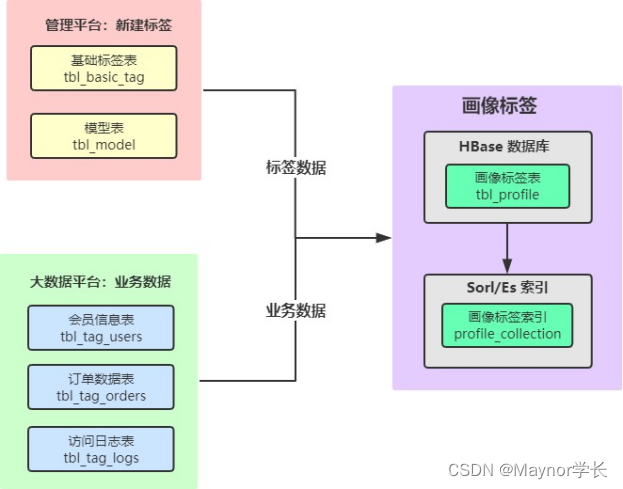
一 标签系统体系架构
1)、标签数据 标签管理平台中,每个标签开发时,首先需要在管理平台上注册(新建标签:4级标签和5级标签) 业务标签和属性标签 业务标签对应标签模型,每个标签模型就是Spark Application,运行程序可以给用户打上标签:TagName 模型表中存储数据:spark application运行时参数设置核心数据: tagName -> tagRule:标签规则
2)、业务数据 依据每个业务标签(4级标签)的标签规则rule,获取业务数据 inType 判断业务数据的数据源,然后解析参数为Meta,加载业务数据(SparkSQL) 此处:整个项目业务数据主要存储在HBase表中
3)、构建标签 使用业务数据和标签数据(属性标签对应tagName和rule)计算标签,得到modelDF,将其保存到HBase表中。 画像标签表:tbl_profile 存储标签数据时,也将标签数据存储同步存储到Elasticsearch索引中,方便使用标签进行查询用户 基于Elasticsearch为HBase表构建二级索引
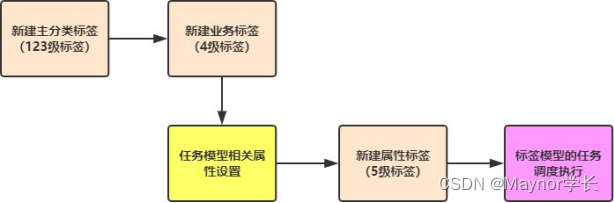
二 标签模型开发流程
展示每个标签模型在实际开发时主要流程: 1)、标签管理平台新建标签 123级标签 34级标签 设置相关属性,包含标签的属性字段的值和对应模型字段的值 标签模型对应Spark Application名称,及标签模型分类,尤其关键为标签规则 rule 5级标签 2)、开发标签模型 如何开发标签模型及测试功能,完成以后需要打成jar包 3)、调度执行 标签管理平台中可以直接调用Oozie Java API调度执行每个标签模型应用程序
三 标签模型计算逻辑
在每个标签模型开发时,计算逻辑主要涉及到四个方面:
SparkSession初始化
1)、【MySQL】依据每个标签tagId获取标签数据spark.read.format(“jdbc”) 只获取与标签相关的所有数据 2)、【HBase】解析标签规则rule,加载业务数据 spark.read.format(“hbase”) 自定义外部数据源方式 3)、【DataFrame】业务数据结合属性标签数据,计算标签modelDF

不同类型标签,计算标签方式不同,分为三种类型,规则匹配类型标签、统计类型标签和挖掘类型标签
- 规则匹配类型标签 业务字段的值与属性标签规则rule匹配即可
- 统计类型标签 设计对业务字段的数据进行统计和对属性标签规则rule进行转换,打标签
- 挖掘类型标签 使用机器学习算法构建算法模型,使用预测值与属性标签规则整合,打标签,其中涉及相关计算 4)、【HBase】标签存储将用户标签数据存储到HBase表中,同步到Elasticsearch索引中
- a)、存储最新画像标签数据 存储HBase表汇总
- b)、同步标签数据到Solr索引中 使用HBase协处理器完成,自定同步数据,批量索引插入 SparkSession资源关闭















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









