







Automated Peer Reviewing in Paper SEA: Standardization, Evaluation, and Analysis
前言
一篇关于长文本大语言模型应用的相关工作,面向于自动化论文评审领域。作者提出了一个新颖的自动化论文评审框架,解决了当前大语言模型无法为论文生成有全面有价值评审意见的同时,又为自动化论文评审领域定义了一个新的评估指标。该项目不仅在工作量上投入巨大,更在创新性和应用性方面达到了新的高度,为科研工作者提供了强有力的工具,显著提升了他们的工作质量。| Paper | https://arxiv.org/pdf/2407.12857 |
|---|---|
| HomePage | https://ecnu-sea.github.io/ |
| Code | https://github.com/ecnu-sea/sea |
Abstract
当前,学术论文的激增对传统评审机制造成了严重的冲击,造成出版物质量不一。尽管现有的方法已经探索利用LLMs进行自动化评审,但是往往生成片面或泛泛的内容。为此,本文提出自动化论文评审框架SEA,包含三个模块:标准化,评估和分析,分别对应着三个模型SEA-S,SEA-E和SEA-A。SEA-S蒸馏GPT-4的数据整合能力获取高质量的评审整合意见。SEA-E基于这些数据微调得到,从而可以生成高质量的评审意见。最后,SEA-A引入了一个新的评估指标名为mismatch score,用于分析文章与评审内容的一致性。基于此,作者设计了一个自我修复策略来增强这种一致性。在八个领域数据集上的实验表明SEA可以生成有用的评审意见,来帮助作者提高他们文章的质量。
Motivation
科学出版物的快速增长为传统的科学评审带来挑战,造成如下问题:
- 增大了同行评审的压力。
- 质量不一的工作会对科研环境产生负面影响。
因此急需一个自动化论文评审框架来帮助作者提升工作质量。
但是自动化论文评审并不容易,传统的语言模型无法handle这个问题,基于LLMs由于出色的NLU能力和长文本能力为自动化论文评审带来了可能。现有基于LLMs的工作分为两个方向:
- Prompt工程。
- 同行评审数据微调。
前者只能生成低质量的generic意见,后者由于SFT时只利用一个评审标签,生成的意见往往是部分且片面的(如下图所示)。
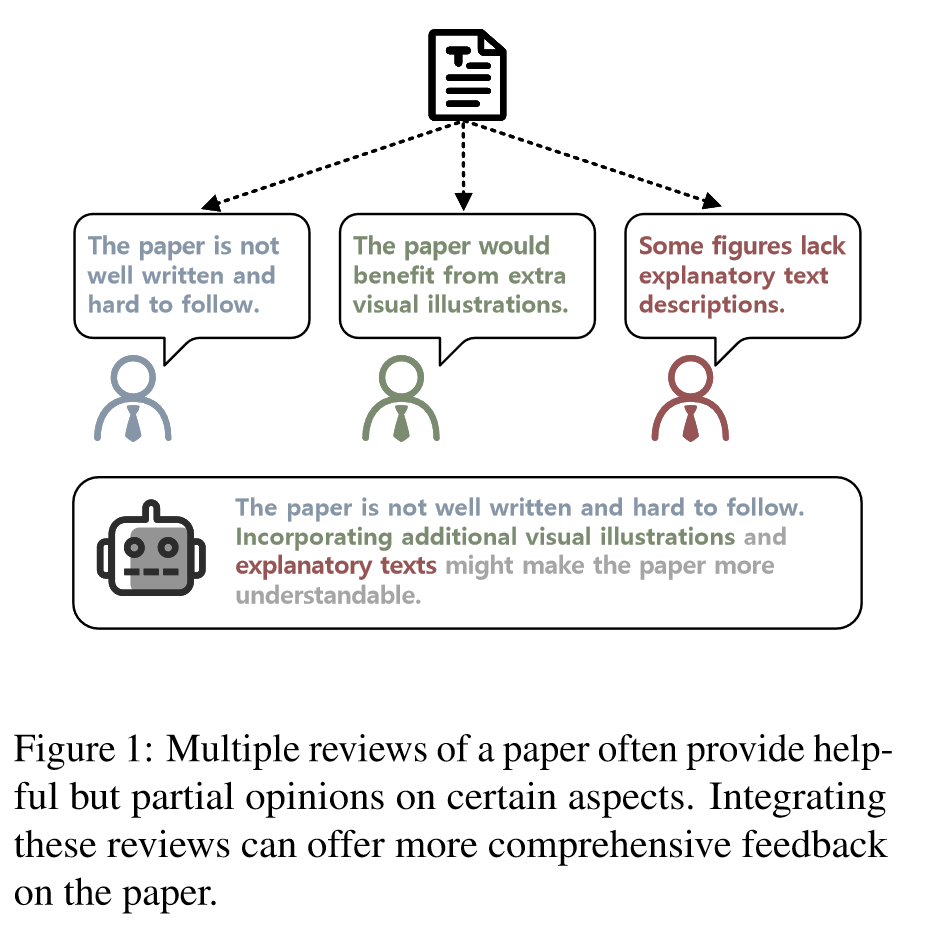
Solution
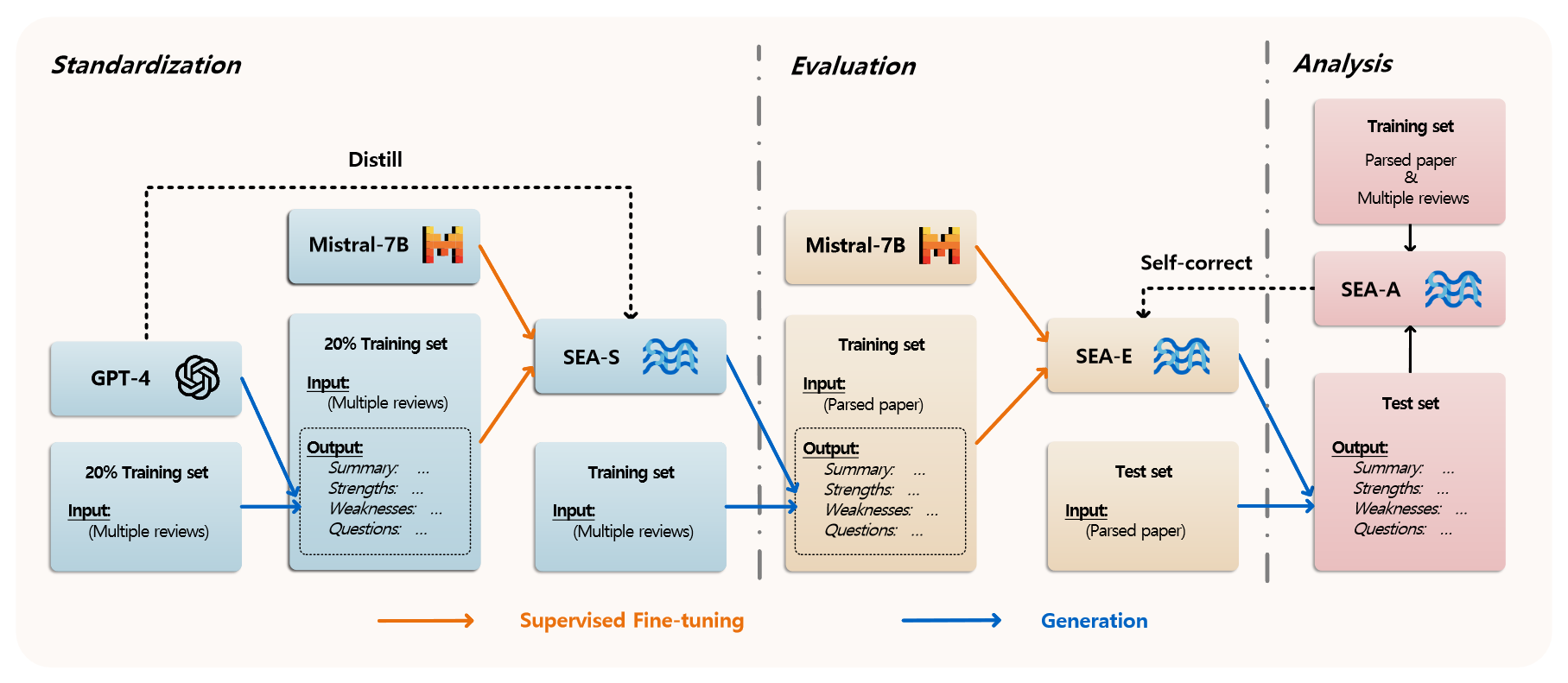
本文提出一个新颖的自动化评审框架SEA,包括三个模块:标准化,评估和分析。如上图所示。
- 标准化模块: 通过蒸馏GPT-4的整合知识得到整合模型SEA-S,SEA-S将一篇文章对应的所有评审整合为一个评审意见。
- 评估模块: 利用标准化模块的高质量评审标签和原始的文章构建指令微调数据集,训练得到评审模型SEA-E。
- 分析模块: 训练一个回归模型SEA-A用于分析生成意见与原始文章的一致性得分,基于此引入自我修复机制来帮助SEA重新生成更一致的审稿意见。
SEA
SEA-S
为了让LLMs具有审稿能力,一个高质量的SFT数据集是必不可少的。然而现有的同行评审数据集的评审标签具有两个特点:
- 一篇文章对应多条评审,不同评审根据其领域或知识提供片面的意见。
- 不同领域的评审风格各异,不统一直接SFT会导致不一致性。
为了解决上述问题,作者考虑将一篇文章的所有reviews整合为一个review,这样的review不仅内容丰富,同时统一了格式。
具体来说,作者先尝试使用不同闭源和开源的模型基于特定的指令进行整合,发现只有GPT-4可以达到理想的效果,但是GPT-4的成本高,且不具有扩展性。为此,作者先随机sample 20%的评审数据用GPT-4进行整合,然后将整合得到的review作为label,原始的多条review作为input,构建SFT数据集来微调开源模型Mistral-7B。这种方法通过蒸馏GPT-4的整合能力到Mistral-7B上,得到数据标准化模型SEA-S。最后,作者利用SEA-S对同行评审数据集的评审标签进行整合,得到具有高质量的评审标签。
SEA-E
受益于SEA-S的输出,作者构建高质量的同行评审指令微调数据集,对Mistral-7B进行微调,得到可以生成全面且高质量审稿意见的评审模型SEA-E。其中,由于原始爬取的论文是以PDF格式存在,因此作者应用Nougat对PDF进行解析。Nougat是一个强大的OCR工具,可以将公式解析为LaTeX代码。
SEA-A
为了衡量原始文章和生成评审内容的一致性,作者利用原始的paper的加权ratings(基于confidence加权)作为ground-truth,输入为经过表征模型得到的文章表征和评审表征,训练一个回归模型。作者提出了一个peer attention的方法,即对文章表征和评审表征相互做注意力,公式如下:
q
p
^
=
W
q
h
p
^
,
q
r
=
W
q
h
r
k
p
^
=
W
k
h
p
^
,
k
r
=
W
k
h
r
\begin{array}{ll} q_{\hat{p}}=W^q h_{\hat{p}}, & q_r=W^q h_r \\ k_{\hat{p}}=W^k h_{\hat{p}}, & k_r=W^k h_r \end{array}
qp^=Wqhp^,kp^=Wkhp^,qr=Wqhrkr=Wkhr
y
pred
p
r
=
w
(
q
p
^
k
r
T
+
q
r
k
p
^
T
)
+
b
.
y_{\text {pred }}^{p r}=w\left(q_{\hat{p}} k_r{ }^T+q_r k_{\hat{p}}{ }^T\right)+b .
ypred pr=w(qp^krT+qrkp^T)+b.
模型的最终输出作为mismatch score,损失函数为MSE loss。在训练得到SEA-A模型之后,作者进一步提出自我修复机制,对SEA-E的输出进行校正。当mismatch score超出一定的阈值后,当前的mismatch score会作为额外的prompt来引导SEA-E生成更一致的评审内容。
Experiments
Main Result
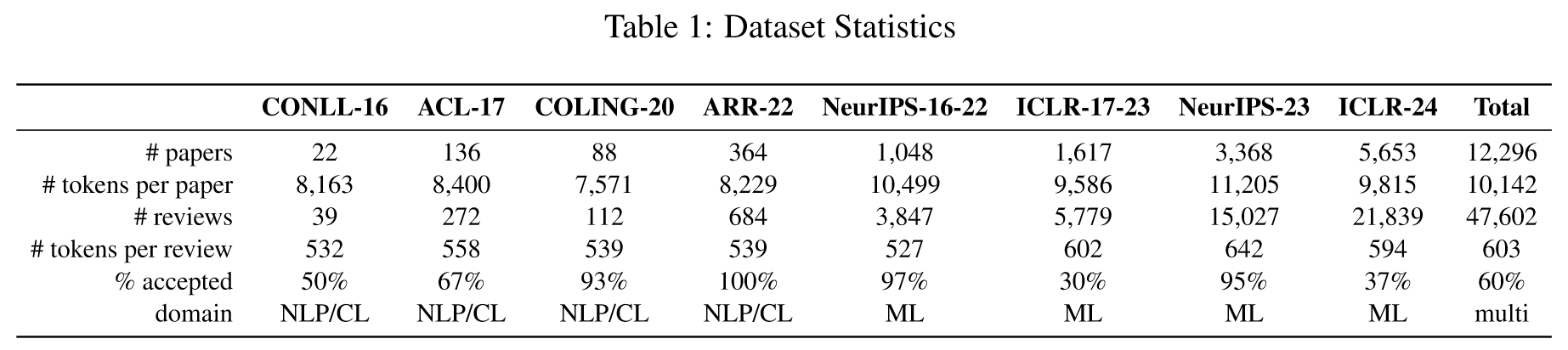
本文爬取了OpenReview上NeurIPS-2023和ICLR-2024数据,其中90%的数据作为训练数据,剩下的10%作为测试集。此外测试集还包括REVIEWER2、PeerRead、NLPeer的数据,展示如下。
baseline模型包括原始的Mistral-7B,随机挑选review进行SFT得到的Mistral-7B-R,GPT-3.5整合数据进行SFT得到的Mistral-7B-3.5。本文方法的模型包括SEA-E和SEA-EA,其中SEA-EA是将自我修复机制与SEA-E相结合的增强模型。评估指标采用BLEU,ROUGE和BERTScore。结果如下:
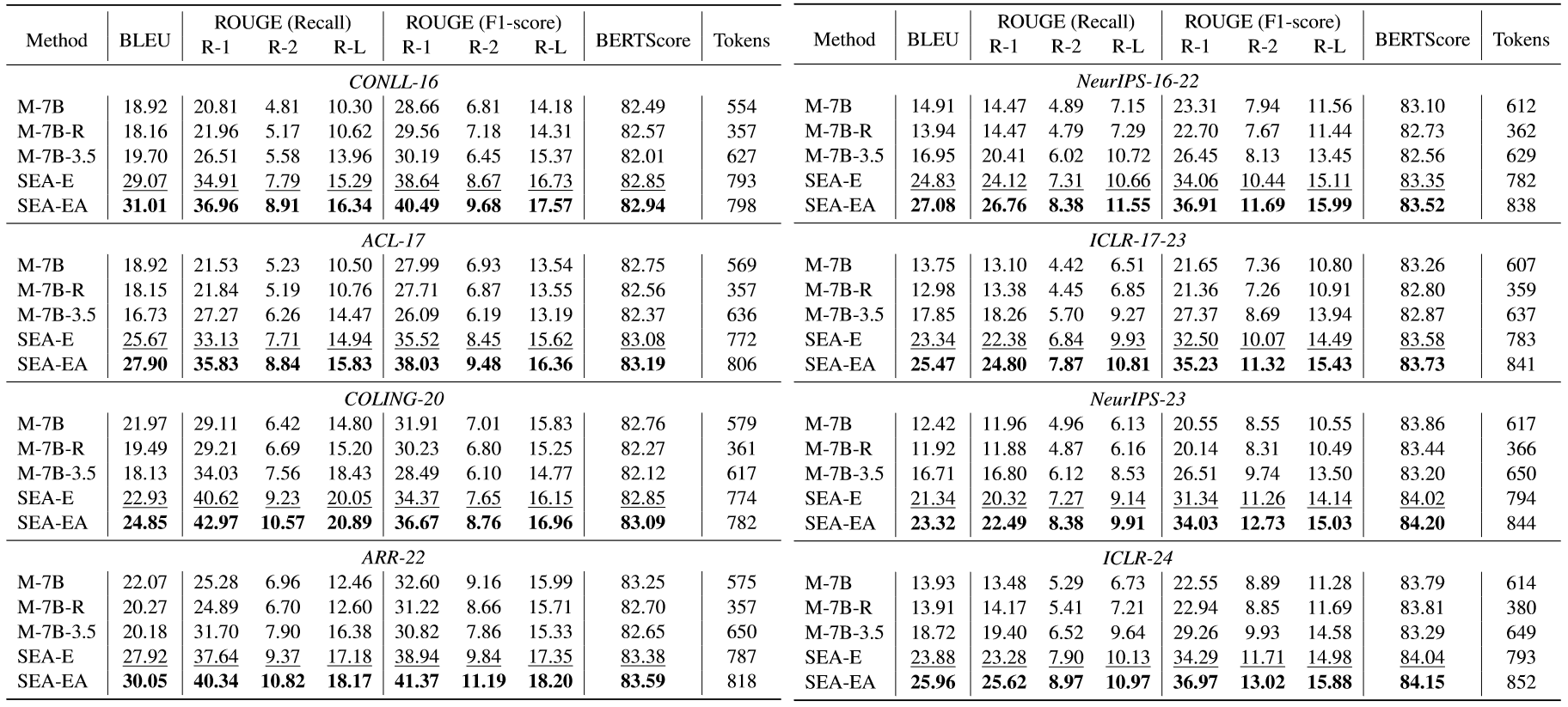
可以看到SEA在所有数据集上都远远超出别的baseline模型,无论是in-domain还是cross-domain。此外,SEA-EA也在所有的结果上超过了SEA-E,凸显出自我纠正策略在生成与原始文章更一致的评审的有效性。M-7B-R表现不佳可能是因为生成长度不够,M-7B虽然长度长,但是未能与人类评审对齐,质量不佳。M-7B-3.5表现不如SEA-E是因为数据标准化质量不够。
Comparison of Standardized Results
整合后的评审内容由于没有ground truth,因此无法直接使用主试验的评估指标进行评估。为了评估不同模型的评审整合能力,作者设计了一个巧妙的方法。作者将SEA-S整合的评审内容作为references,其他模型整合的评审内容作为candidates。接着计算candidates与references之间ROUGE值的recall和precision,根据这两个指标,可以推断出两个评论中重叠和独立语义信息的百分比,从信息量的角度来表明哪个模型整合的review内容具有更丰富的信息,即间接说明有更好的整合内容。结果如下:
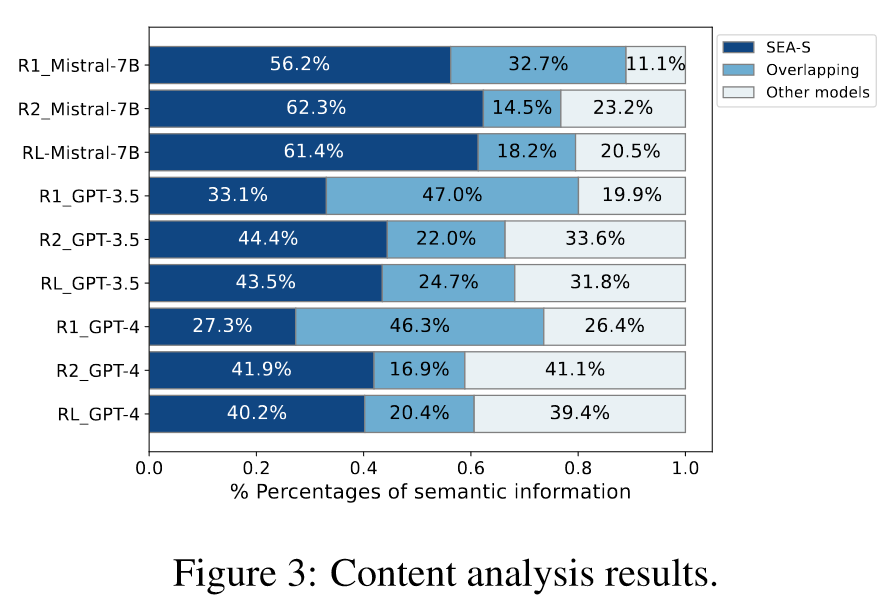
相对于Mistral-7B和GPT-3.5,SEA-S具有更丰富的内容,这进一步验证了SEA-S可以更好地标准化评审并提供更丰富的信息。此外还发现,SEA-S整合的内容甚至略好于GPT-4,因为GPT-4在整合时也会有部分情况没能遵循指令导致生成低质量的评审内容。
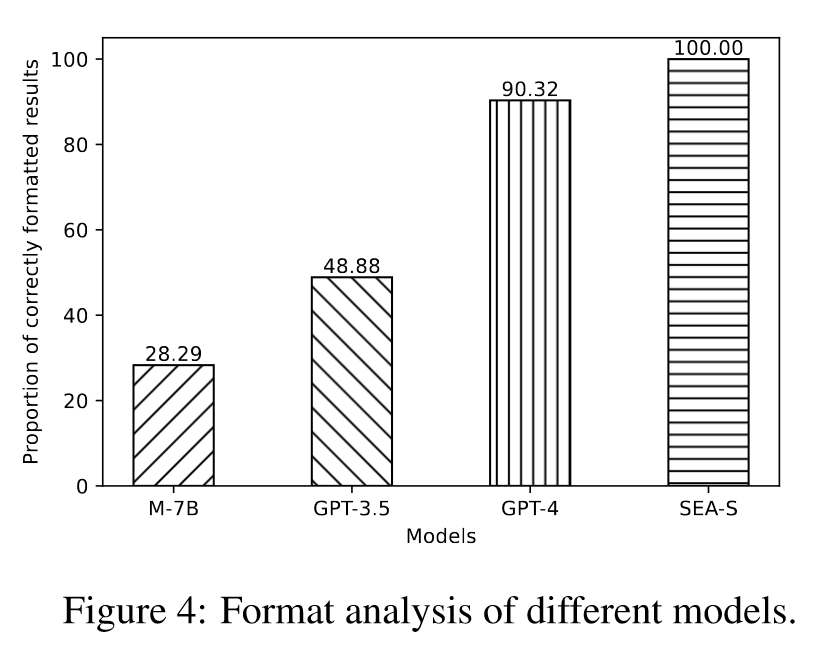
为了进一步探讨整合质量,作者利用基于指令格式的正则表达式匹配来计算不同模型整合的正确格式化的比例,如上图所示。受益于SFT,SEA-S能够生成100%正确格式的数据,相比之下,Mistral-7B和GPT-3.5表现不佳,尤其是前者。GPT-4也有10%的数据没能遵循指令。总体而言,SEA-S在处理各种格式和标准的评审方面表现出极佳的效果。
Mismatch Score in SEA-A
本小节分析不同模型生成评审和原始文章之间的一致性。作者将不同模型在测试集上生成的评审内容输入到SEA-A中,计算每个模型在不同数据集上的mismatch score。
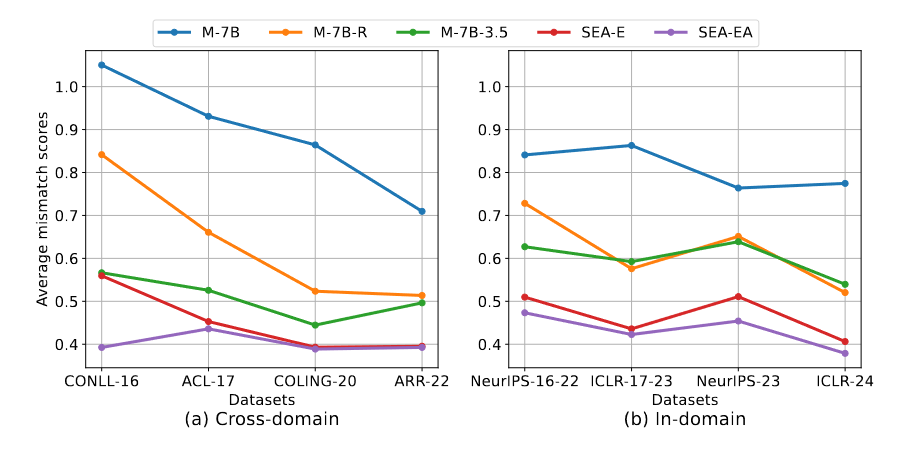
SEA-EA在所有数据集上保持最低的mismatch score,紧接着的是SEA-E,这证明了SEA可以生成与原始文章更一致的评审意见。Mistral-7B没有经过SFT,没能学习到生成评审和原始文章的一致性内容,因此表现最差。
Quantitative Score Analysis
作者还对生成评审中的分数部分进行了分析。包括Soundness,Presentation,Contribution,Rating,ground truth为基于confidence的加权均分,采用MSE作为度量标准,结果如下:
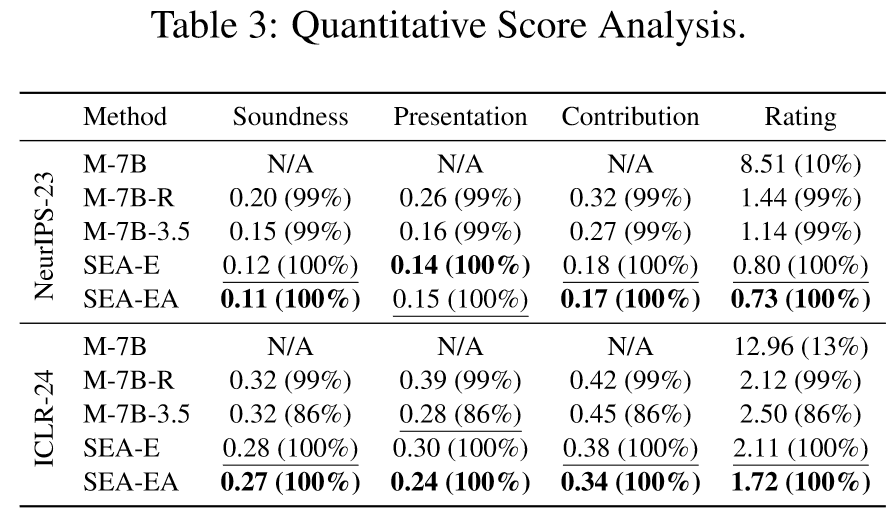
其中百分比是能准确生成分数的比例。可以看到:
- SEA确保了输出格式的有效性。
- MSE度量表明,SEA在所有情况下都优于baseline。
- SEA-EA在大多数情况下都比SEA-E表现出改进,进一步验证了自我修正策略能够使生成结果与人类反馈在定量评估结果上高度一致。
Qualitative Decision Analysis
本小节分析了生成的Decision和Reason部分,即类似于Meta-review的内容。结果如下表所示:
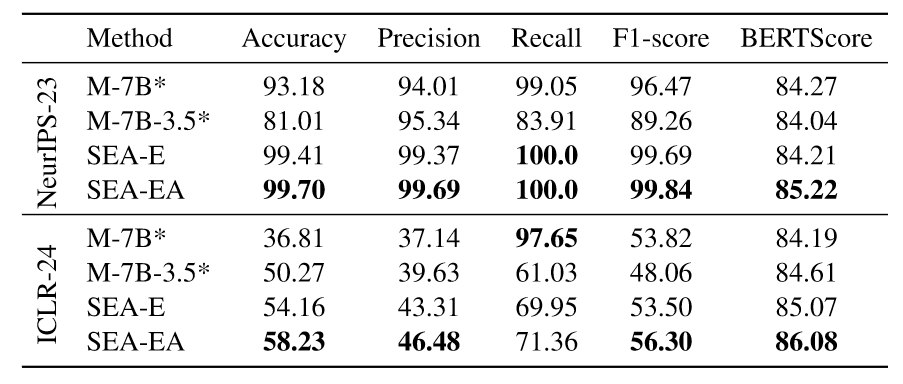
可以看到:
- SEA-EA准确率和BERTScore都是最高,后者表明生成内容和meta-review贴近。
- NeurIPS-23由于数据本身的问题(95%都是Accept),没有太大的参考价值。
- ICLR-24中,SEA-EA的accuracy超过SEA-E多达4%,进一步表明自我纠正策略的有效性。
- M-7B Recall高达97.65%,但是Precision低,这表明它倾向于迎合人类偏好,接受大部分论文。
- SEA在Precision和F1上表现更好,表明本文的方法可以更有效的识别不同质量的论文。
总的来说,SEA生成的评审内容更接近实际的审稿决策,并且不偏向于接受的决定。
Conclusion
本文提出了SEA,一个基于三个模块的自动化论文评审框架,可以为文章生成全面、高质量、一致性的评审内容。基于该框架,将有助于研究人员提高他们工作的质量,并且为自动化科学评审领域带来新的启发。
这篇工作是博主继OS-Copilot之后另一个全身心投入的工作,这种工程+research的工作经历下来确实是苦不堪言,身心俱疲,不过好在结果还是比较让我满意的。当然,对于这样的工作还是有很大改进的空间:
- 训练好的模型无法获取最新领域的知识,引入RAG可能是比较好的解决方法。
- SEA-A模型的性能没有理想中那么好,可能是因为原始数据太多boardline的意见,导致训练数据质量不高,还有一个主要的原因我认为是没有这种校正的真实数据,也许引入Rebuttal的内容可以在一定程度上解决这样的问题。
- 本文只涉及了AI和机器学习领域,还没有往别的领域拓展,但是理论上将SEA应用到别的领域,相信也能取得很好的效果。
最后必须再次强调说明,SEA明确禁止用于真实场景的论文评审,只能够作为辅助的意见,在交稿前帮助科研人员提高工作的质量。
















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











