







前言
我带队的整个大模型项目团队超过40人了,分六个项目组
- 每个项目组都是全职带兼职,且都会每周确定任务/目标/计划
- 然后各项目组各自做任务拆解,有时同组内任务多时 则2-4人一组 方便并行和讨论,每周文档记录当周工作内容,平时群内随时讨论 1-2周一次语音会
- 最后通过相关课程不断招募各项目组成员
比如在我司审稿项目之前的工作中,我们依次想尽各种办法微调以下模型(我之外,包括且不限于阿荀、朝阳、apple、三太子、文弱、鸿飞、不染、贾斯丁等)
- 七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV
- 七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4
- 七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩大对GPT4的优势
- 七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma
- 七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b,对GPT4胜率超过80%
如上面「第五篇 Mixtral-8x7b微调一文」的文末回复一读者的评论所说,“近期 我们一方面 等llama2 70b的结果,一方面 准备提高下数据的质量了”,故有了本文
而如何提高数据质量呢,便是我和我司审稿项目组在24年3月底登杜甫江阁时所确定的:

- 一个是提高review的质量(从而考虑到可以提高GPT对一篇篇paper的多个review做多聚一摘要出来的大review的质量,由于是让GPT根据设计的prompt做多聚一的摘要操作,故可以优化下该prompt)
- 一个是看有没办法可以拿到review出来之前更早期的论文版本
总之,对于4月和整个Q2而言,除了RAG 2.0版(含通用文档理解)、机器人、两个agent项目之外,论文项目组也有9个事待并行推进:
- 1 70b的微调
2 清洗prompt的优化
3 论文早期版本的爬取
4 review特异性的增强 - 5 论文评分
6 审稿新数据爬取
7 金融审稿模型的微调
8 论文翻译
9 论文检索 idea提炼
第一部分 提升七月论文审稿之数据质量的三大要素
1.1 数据清洗(paper不变 review变):让GPT对Review做多聚一操作的摘要prompt的优化
1.1.1 我司目前所有审稿数据的全部细节
如本文开头所说,当我们把各种模型都微调一遍之后,发现最终还是得回归到我司爬的数据上
首先,在数据的爬取时间点上,在针对review做多聚一之前,只是经过简单初筛(比如去除过短的review)后的总paper数-30186份,通过两次先后爬取到:
- 2023Q4(含全部会议,2018-2023):爬取23176份
后续如果做了更多数据处理之后(比如多聚一和去除长尾之后),数据量便会从23176篇带多条review的paper降到了15566条paper-review(一篇paper对应一条大review),详见此文:七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2 7B最终反超GPT4 - 2024Q1(含全部会议,2017-2024):爬取7010份
和上面Q4的23176份数据一样(只去除了过短的review),尚未做多聚一和去除长尾数据等操作
其次,在数据的组成上,这30186份里面,ICLR、NeurIPS这两个会议的总数是24210份「当然,这个数据量是在多聚一之前的(也就是只去除了Review过短项后的),后续还会根据是否有对应paper、去除无效内容等进一步过滤,还会再少一截」,包括

- 15877份ICLR(2017-2024,从某paperreview网页访问可以访问到2013-2016的iclr,但相关的详细数据接口没有暴露这部分年份的数据,所以只能取到2017-2024的iclr)
- 8333份NIPS(2019-2023,至于2024年的在24年4月初时paper和review都还没有内容 )
而这24210份,又都是什么时候爬的呢?
- 2023Q4爬到的(含ICLR 2018-2023共14224份、NeurIPS 2019-2022共6347份)-20571份
- 2024Q1爬到的(含ICLR 2017/2021/2024共1653份、NeurIPS 2019/2021/2022/2023共1986份)-3639份
最后,让鸿飞爬取NIPS官方源的review数据(这部分数据唯一的不足是paper和review均没带具体日期:即没带年月日)
- 共爬取有2485篇(2014-2020,21年review项都是导向了某paperreview网站,22年、23年均没有提供review这一选项,24年数据的话截止到24年4月初就完全还没有存在内容,且是paper和review都不存在 ),初步去掉与上面30186份中重叠的18篇,最终剩余2467篇
- 至于NIPS 2013的数据则还待爬
1.1.2 对review做多聚一摘要prompt的优化
那怎么提高数据质量呢?其中一个便是提高review的质量
在我们之前的一系列工作中,我们针对一篇篇论文的多个review做多聚一,且摘要出多个要点,从而,一篇paper 一条review,最后,就可以弄成qa对 去微调开源模型
而之前5k 15k条paper-review数据对中的review,就是根据旧prompt 通过GPT3.5 16K摘要出来的,但之前的旧prompt 比较简单,就4个点
- 重要性和新颖性
- 可能被接收的原因
- 可能被拒绝的原因
- 其他改进建议
现在,想把review摘要的更好些,好提高微调效果,说白了,如果摘要出来的review质量不够高,会非常影响咱们微调模型的效果
总之,咱们的核心目标还是
不断逼近顶会审稿人的视角,以一针见血指出论文的问题、闪光点,从而侧面帮助作者修订论文
在经过反复看一系列论文的review意见之后我个人的反复琢磨,以及七月平台上一系列顶会审稿人对审稿的意见,外加和审稿项目组阿荀、朝阳等人的反复讨论之后,暂定把摘要prompt优化如下(至于完整的prompt设计见七月官网的:大模型商用项目之审稿微调实战营)
- "1 How to evaluate the idea of the paper, such as its importance, novelty, or what significant problem it solved, and what new methods or structures it proposed ": List multiple items in a dictionary, where the key is a brief description of the item, and the value is a detailed description.
- "2 Compared to previous similar works, what are the essential differences":XXX.
- "3 How to evaluate the experimental results in the paper":XXX.
- "4 Possible reasons for its acceptance":XXX.
- "5 Possible reasons for its rejection":XXX.
- "6 Other suggestions for improving the quality of the paper":XXX.
- "7 Other important review comments":XXX.
总的思路就是,对于一篇paper,先看它的重要性、新颖性以及与众不同之处;接着看实验是否充分有说服力,然后总结闪光点、不足;最后看如果改进,看往哪几个方面做改进
1.1.3 对新prompt下gpt-3.5-turbo-1106摘要的测试:看是否有幻觉情况
prompt确定好之后,为了验证是否靠谱,便可以针对较短的2-3条review做摘要试下,但怎么选取较短的review呢?
可以从数据集里的c_content_str里看下,比如通过空格切分或者nltk.tokenize.word_tokenize()切分来统计长度,选排得比较短的几篇,具体操作流程是
- 将同篇paper(同个id)的c_content_str拼接起来
- 然后统计长度

- 根据长度排序,取较短又相对有一点内容的几篇review
最终,朝阳测了大概10个例子,发现在新的prompt下,gpt-3.5-turbo-1106对于阿旬已经处理好的较短的review数据基本没有胡编乱造的情况出现,对于无法摘要的点会正常返回空 (暂基于“之前博客中一直说的gpt3.5 16k”,也就是继续统一用gpt-3.5-turbo-1106,下图的图源是:https://platform.openai.com/docs/models/gpt-3-5-turbo)

不过我个人认为还可以对伪词数小于120的再截断下,一方面发现伪词数104的有60多条都是一样的,且没有实质性的内容,截图如下

另一方面,对于新的prompt的7点来讲,如果内容太少总结出的摘要内容也会较少
后续确实还是用更加严格的长度限制合适些,甚至可以限制更大的长度,优先保证质量,一方面可以保证review信息充足,另一方面可以缓解摘要幻觉
1.1.4 通过新prompt针对1.5K、15K份数据分别做多聚一的摘要操作
接下来,我们便可以通过Q4那份23176的数据尝试下,具体而言
- 微调数据的准备(paper不变 review变)
先抽取其中的1557篇paper,然后用新的prompt,针对这部分paper的人工review重新做下多聚一的摘要操作(其实就是把线上营中的1.5k篇paper的人工review重新做了下 多聚一)
然后,我们就得到了如下图所示的paper-review数据集

- 实际微调:针对训练集中的paper做review预测,与人工review之间做loss
然后微调下llama2 7b,看下work的效果(注意,这里的1.5k都是选的有内容的,故不用再做去除长尾的操作)
当然 微调时让llama2 7b针对训练集中1500多篇paper做review预测的prompt也是相应要用新的「微调prompt」
且虽然这个「微调prompt」的重要性不如数据的重要性大「毕竟当数据量大了上去之后(比如从1.5K到15K),模型会领悟的更多了,类似想作诗,熟读唐诗30首,肯定不如熟读300首(比如30首 模型领悟能力30分,300首 模型领悟能力90分)」instruction = "You are a professional machine learning conference reviewer who reviews a given paper and considers 7 criteria: ** how to evaluate the idea of the paper **, ** compared to previous similar works, what are the essential differences **, ** how to evaluate the experimental results in the paper **, ** possible reasons for its acceptance **, ** possible reasons for its rejection **, ** other suggestions for improving the quality of the paper **, and ** Other important review comments **. In these 7 different criteria, based on the content of the paper, you can list out as many sub-items as possible under each criterion, but do not fabricate content. The given paper is as follows.\n\n\n".strip()
但数据量大上去之前,我认为还可以通过更丰富的prompt让模型领悟到更多「比如让模型领悟能力50分,虽然没90分,但也是进步了」 - 为了让llama2 7B PK GPT4-1106,故让它两分别针对测试集中的paper做推理
让上面微调后的llama2 7b,在新的「推理prompt」下针对测试集中的paper做推理,得到llama2 7b的review结果
让GPT4-1106,在新的「推理prompt」下,针对测试集中的paper做推理,得到GPT4-1106的review结果
最后把咱们之前的测试集中的人工review,也基于新的「多聚一prompt」通过GPT3.5 16k做下摘要,作为ground Turth - 模型评估
需要注意的是,在评估阶段的处理过程中,需要提取review的子项来进行比较,由于新的prompt关于摘要的描述相对较长,故如果基于原来的代码
对新prompt生成的review,可能会出现把摘要描述也算作是子项的情况,如下图红框所示:def add_order(review_text): # 输入单条review文本,返回处理得到的(项数, 带序号的子项文本) mark = 1 ordered_items = [] for line in review_text.split("\n"): item = line.strip() if len(item) > 50: ordered_item = "{}. {}".format(mark, item) ordered_items.append(ordered_item) mark += 1 else: continue return (mark-1, "\n".join(ordered_items))
而实际上的项数只有13项,如下:
那具体应该怎么修改呢?详见七月官网的《大模型商用项目之审稿微调实战营》
再往下,我们再用Q4那份15K的数据试下,从而就需要把15K数据中的人工review都用新的多聚一摘要prompt生成新的ground truth
然后通过这份15K规模的「不变paper-7个方面的review」继续通过longqlora微调咱们的llama2 7B:对比「其对15K份paper的review预测」与「人工review(即新的ground truth)」之间的差异,建loss
最后评估时,让GPT4-1106、微调后的llama2 7B分别通过新推理prompt对测试集中的paper做推理,最后把这两者的推理结果依次与「测试集中人工review在新的多聚一摘要prompt下的结果」做命中数的对比
// 待更
1.2 数据溯源(paper变 review先不变后变):论文早期版本的爬取
1.2.1 爬取论文所对应的最早版本近3万篇,这样和review的匹配程度 才能更高
我们之前爬的paper-review数据中,paper大部分都是根据某个或某几个review意见而修改后的版本,相当于paper是新paper,可review还是旧review,相当于没法做到paper与review的100%匹配,这个问题曾一度困扰我们
包括来自厦门大学NLP实验室的这篇论文《MOPRD: A multidisciplinary open peer review dataset,其对应数据地址为dataset》也提到了这个问题:
“大多数提供公开访问同行评审数据的期刊只呈现其论文的已发表版本,而原始手稿通常是保密的。没有原始手稿,许多与开放同行评审相关的研究将变得不可能。 例如,基于修订来研究审稿意见将毫无意义。毕竟在修订中,已经采纳了审稿意见,并解决了原始手稿中的相关问题。总之,如果没有可靠地与原始手稿进行比较,将无法充分理解审稿意见的有效性,对于开放同行评审的研究,审稿意见将变得不太有效 ”
顺带,意外收获了一个可以获取各个学科审稿意见的网站,即:PeerJ
4.3日,我又开始反复琢磨之前阿荀爬下来的review数据

结果意外发现可爬到review对应的论文早期版本
从而,也就解决了审稿项目的这个「paper与review匹配度不足」的大问题,毕竟我们要的就是这种论文所对应的最早的审稿版本,这样和review的匹配程度 才能更高(至于如何具体爬取见七月官网的:大模型商用项目之审稿微调实战营)
如此,便出现了下述三种情况中的第二种情况
- paper不变 review变
摘要prompt变了:review变了(审稿意见出来7个方面),这是上一节《1.1 数据清洗:让GPT对Review做多聚一操作的摘要prompt的优化》的情况 - paper变,review不变
paper爬的更早期的论文版本
但摘要prompt不变:即review不变(推理时 审稿意见出来4个方面)
应该可以对我们第二版的基线 做拔高,即是很需要直接和之前的胜率 做对比的 - paper变,review变
paper爬的更早期的论文版本
摘要prompt变成新的:即review变了(推理时,审稿意见出来7个方面)
考虑到如阿荀所说,“新的paper有近3万篇量比较大,可能应该是先挑好做好多聚一的review了,决定要用哪些paper了再解析好点,不然paper解析可能要花挺长时间,有的paper解析出来也不一定能用上”
故接下来,先尝试第二种(最后再尝试第三种):毕竟第二种情况中的review是旧有现成的(即之前23年Q4时通过旧prompt已多聚一处理好的 ),解析其所对应的paper就行
1.2.2 paper变 review不变的情况下,先根据Q4的15K来解析对应的早期paper
// 待更
1.3 数据增强:增强review数据的特异性
什么叫做特异性?比如最左侧的review便是特异性,而最右侧的review则丧失了特异性(对于作者而言,最不希望看到的就是这种放之四海而皆准的review,因为其对论文的改进帮助不大)

那如何解决呢?请看下文的第二部分
自从我司于23年7月开始涉足论文审稿领域之后,在业界的影响力越来越大,所以身边朋友如发现业界有相似的工作,一般都会第一时间发给我,比如本文第二部分之康奈尔大学的reviewer2
此外,我自己也会各种看类似工作的论文,毕竟
在大模型时代
- 一个技术人保持竞争力的最佳方式就两点:保持对最新技术/paper的跟踪,每天各种大量实践/折腾/实验
- 对于一个组织也是如此,通过项目(整个小组 + 2-4人的小队伍双重协作),是提高组织战斗力的最佳方式,不然各自为战
比如本文第三部分的PeerRead,毕竟同行之间的工作一定会互相借鉴的,我们会学他们,他们看到我们的工作后自然也会受到不小的启发
第二部分 康奈尔大学之Reviewer2及我司七月对其的实现
对于论文审稿,我司的思路是通过一系列paper-review对去微调一系列开源模型,而对于review数据的处理更多是把一篇篇paper的多个review做多聚一的摘要操作,且从中梳理出来4或7个要点,然后基于这4-7个要点让微调后的模型去自动生成一篇篇新paper的review
而这4-7个要点的定义就比较关键了
- 一方面要尽可能涵盖所有论文的核心特征,这叫通用性,比如斯坦福那篇论文让GPT4当审稿人,梳理出来4个方面的要点:重要性 新颖性、可能被接收的原因、可能被拒绝的原因、其他重要改进建议
- 二方面 又要尽可能抓住每一篇具体paper的各自特色,这叫特异性,比如马上要介绍的康奈尔大学的reviewer2
总之,这两方面在一定程度上是有点矛盾的,所以需要想尽办法做好平衡
接下来,咱们来具体看下康奈尔大学的reviewer2
2.1 整体训练流程、推理流程、数据集
2.1.1 Reviewer2的整体训练流程
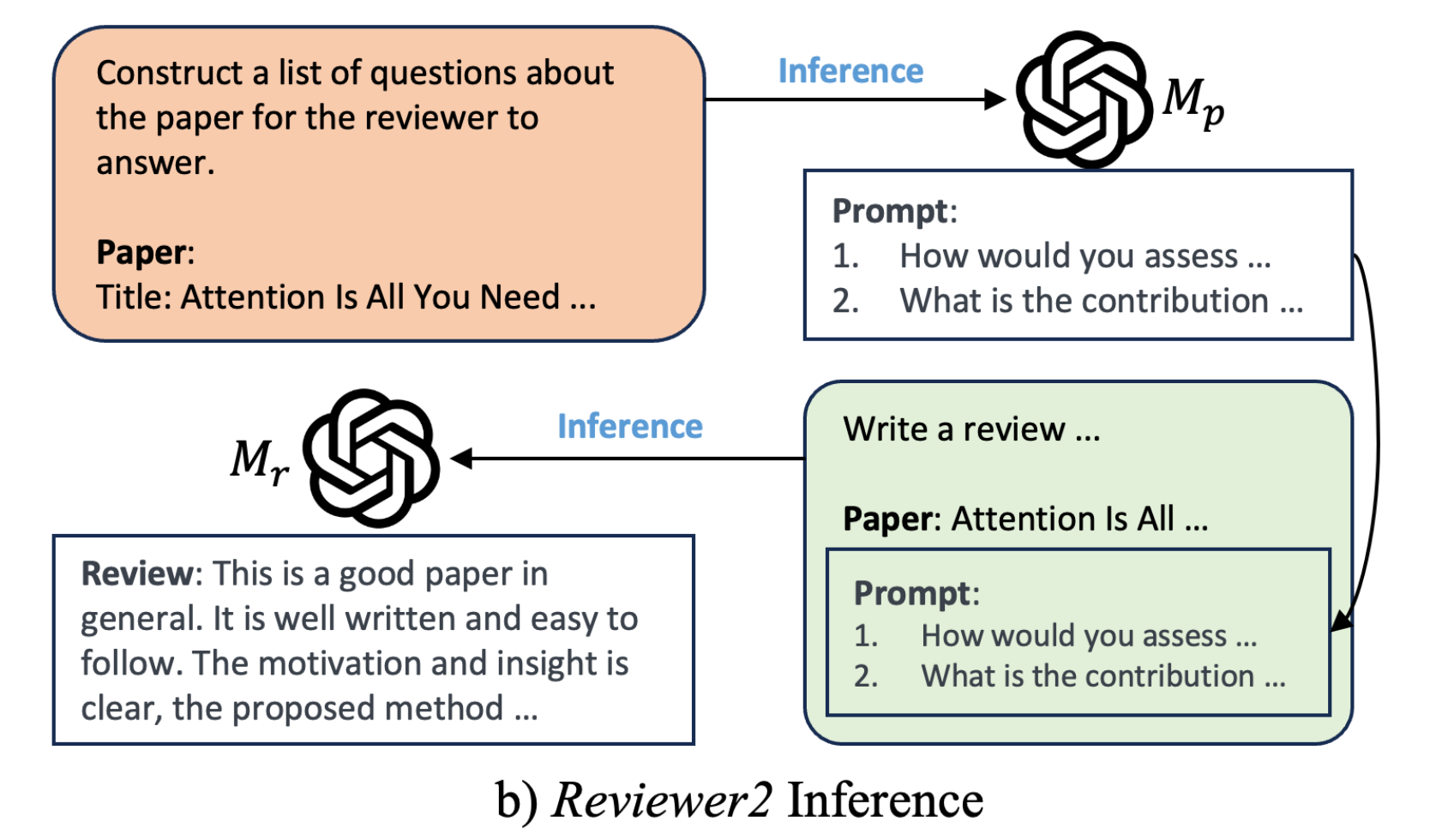
24年2月,康奈尔大学通过此篇论文《Reviewer2: Optimizing Review Generation Through Prompt Generation》,也提出了一个论文审稿模型Reviewer2,其整体流程为(注意,表示review的prompt,
表示review本身,
表示论文)

- 用PGE方法从人工review中生成预设问题数据(相当于从review当中提炼审稿人针对一篇篇paper所对应的关注问题点),相当于paper =》 人工review =》通过PGE:即llama2 70B提炼预设问题 =》预设问题
然后使用 [paper, 预设问题] 数据训练得到一个能根据不同paper提出不同预设问题的模型
相当于让模型A学会根据不同的paper提问(毕竟,每篇review的预设问题不太一样),毕竟提问是门艺术
即to produce a set of aspect prompts x1, ...xk for paper p that cover the aspects that a reviewer may comment on for this paper
这里有比较重要的一点是,可能会有读者疑问,这个prompt到底是根据paper生成,还是根据review去生成,实际上可以这么理解,即prompt的ground truth是基于PGE方法从人工review当中生成的prompt,而训练模型的时候(当然 更包括推理),
可能又有读者疑问,那为何不人工根据一些paper标注其对应的「ground truth版的prompt」,然后再训练模型 - 使用 [paper +
a) 即先把不同的paper输入模型去输出与paper息息相关的review)
b) 然后再把paper和预设问题输入模型
c) 最终和人工review对比词的重叠度以不断迭代模型
且类似七月审稿GPT,其也基于longlora的S2-Attn和FlashAttention2把llama2 70B的上下文长度扩展到了32k
2.1.2 Reviewer2的推理流程
推理的时候,在为新的论文 生成评论时,我们首先查询
以获取review prompt
。 然后我们查询
以为生成的方面提示生成review
2.1.3 Reviewer2数据集的详细信息
如下图所示,对于Reviewer2的数据集,其来源于多个会议

- 来自PeerRead的CONLL-16和ACL-17
- 来自NLPeer的 COLING-20和 ARR-22
- 来自openreview的ICLR papers from 2017 to 2023
- 来自papers.neurips.cc的NeurIPS papers from 2016 to 2020
- 来自openreview的NeurIPS papers 2021 to 2022
综合3 4 5,则意味着包含了ICLR 17-23 and NeurIPS 16-22的paper
2.2 PGE:在上下文示例下基于Review生成ground truth版prompt(含其评估)
为了给每个review生成相应的prompt,Reviewer2提出了带有评估的提示生成(Prompt Generation with Evaluatio,简称PGE)流程,包括生成步骤和评估步骤
具体来说,给定篇论文
,和相应的人工review
「其中
是论文
的review数量,即一篇paper一般都会有多个review,比如一篇论文5个review」
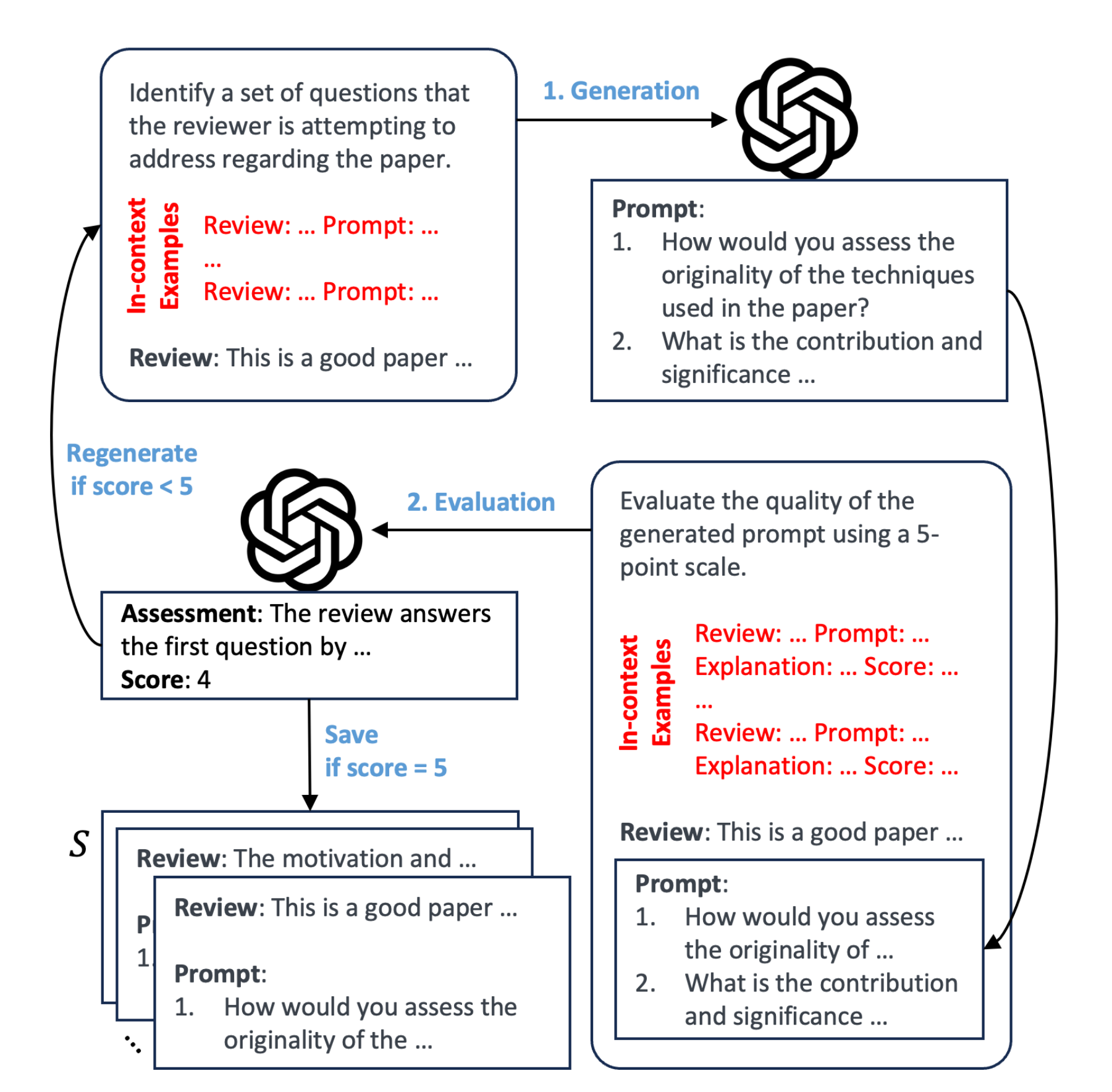
- 该流程的目标是在上下文数百个review-prompt的示例下生成一组review的prompt
,其中一个prompt对应一个review,比如5个review则有5个对应的prompt
即对于review,生成步骤生成一个prompt
- 然后对生成的prompt进行评估,评估在上下文25个review-prompt-score的示例下且基于一个5分制度,完成对生成的prompt的打分(比如1-5分)
- 如果
得分为5,那么
对便存储在集合
中,
,否则重新生成提示
整个过程跟self-instruct还是有点类似的(至于什么是self-instruct,详见此文的2.1.2 什么是self-instruct方式:提示GPT3/GPT3.5/GPT4的API收集数据 ),下面更加细致的逐一阐述上述三个步骤
2.2.1 Prompt的具体生成:基于数百个示例
为了更好的根据review生成prompt,咱们总得有些示例 是不?那怎么构建review-prompt的示例呢,先机器生成然后人工注释,最后示例生成后便可以初始化,具体而言
- 首先使用Llama-2-70B-Chat以zero-shot的方式为随机选择的100个review生成prompt「To construct these examples, we use Llama-2-70B-Chat (Touvron et al., 2023) to generate prompts for a randomly selected subset of 100 reviews in a zero-shot fashion 」
- 然后,通过删除prompt中与review不相关的问题,且添加在review中涵盖但prompt中遗漏的问题,并以与实际review中蕴含问题的开放式格式对齐等这3种方式来手动优化review prompt(we manually refine the prompts by removing irrelevant questions, adding missing questions that are covered in the review, and refining to align with the open-ended format of review questions)
以下便是一个review-prompt对的示例
这些示例之后将在prompt的生成过程中用作初始上下文示例「即We initialize S with human-annotated examples that will be used as initial in-context examples during generation,说白了,为了提高提示生成的性能,作者团队在review prompt生成的过程运用了上下文学习(in-context learning,简称ICL)」
2.2.2 Prompt的具体评估:以25个人工review-prompt-score示例为参考基准
与生成类似,Reviewer2在评估步骤中也应用ICL
- 首先,使用Llama-2-70B-Chat根据5分制评估review-prompt对,每个分数从1到5都有五个上下文示例(相当于总计有25个评分示例)。注意,此处的上下文示例是手动构建的,并在所有评估中保持一致「We use Llama-2-70B-Chat to evaluate the review-prompt pair based on a 5-point scale with five in-context ex-amples for each score from 1 to 5. The in-context examples (shown in Appendix C) are manually constructed and remain consistent across all evalutions」
以下便是一个最终对所生成的review prompt评分为3分的示例(可想而知,这样评分为3分的示例有5个)
且受到思维链提示的启发,还会提示LLM在生成最终分数之前为分数生成解释,以鼓励更准确的评估
- 其次,便可以基于一些评分示例作为上下文学习的数据,给新的review-prompt评分了

2.2.3 Prompt的再生:基于人工评分基准评判下得分不够则重新生成
为了确保生成的prompt的质量,如果得分不是 5,则会重新生成prompt
由于生成prompt时的上下文示例是随机抽样而不是固定集合,重新生成步骤保证了与之前的生成相比,必会生成不同的prompt,从而减少冗余(Since the in-context examples for generation are randomly sampled rather than a fixed set, the regeneration step is guaranteed to generate a different prompt compared to the previ-ous generations, minimizing redundancy)
从而,每个review限制生成prompt 5次,并且如果超过限制,则不再生成。超过 90%的prompt在3次或更少的生成次数内达到 5分(We use a limit of 5 generations per review, and the review is excluded from further generation if it exceeds the limit. More than 90% of the reviews take less than or equal to 3 generations to reach a score of 5)
走完上面一个完整流程之后(先生成100个种子数据集,然后评分、筛选),便可以已有的review-prompt数据集,通过ICL的方式生成更多数据集了,其中,有两个小细节

- 由于上下文示例是从
As more prompts are generated and saved to S, the pool of available examples also expands, ensuring the diversity of the prompts. - 且总是在满足模型上下文长度约束的同时,采样最大可能数量的上下文示例
We always sample the maximum possible number of in-context examples while satisfying the context length constraint
2.3 七月对reviewer2工作的实现:先训练可根据paper提出预设问题的模型,然后根据prompt生成review
截止到24年4.21,康奈尔的这个reviewer2工作,并没公开其数据集、代码(连GitHub都没有),所以我司七月审稿项目组决定自行实现下
- 第一步 人工造种子数据集
120篇paper-review,总计六个人每人负责给20篇paper所对应的review,提示llama 3或GPT4-0409 生成prompt(问题)
1 文弱,3
2 三太子,3
3 吴同学,4
4 扶摇,3
5 朝阳,4
6 王同学,3
最终通过GPT4-0409来评判 - 第二步 通过上面的种子数据,基于PGE扩大更多数据
- 第三步
基于120篇paper让llama 3预测预设问题,然后通过[paper,第二步出来的预设问题]微调llama 3
2.3.1 先提示llama3或GPT4-0409生成prompt
给定的review数据均以csv文件格式进行存储,相关字段说明如下:
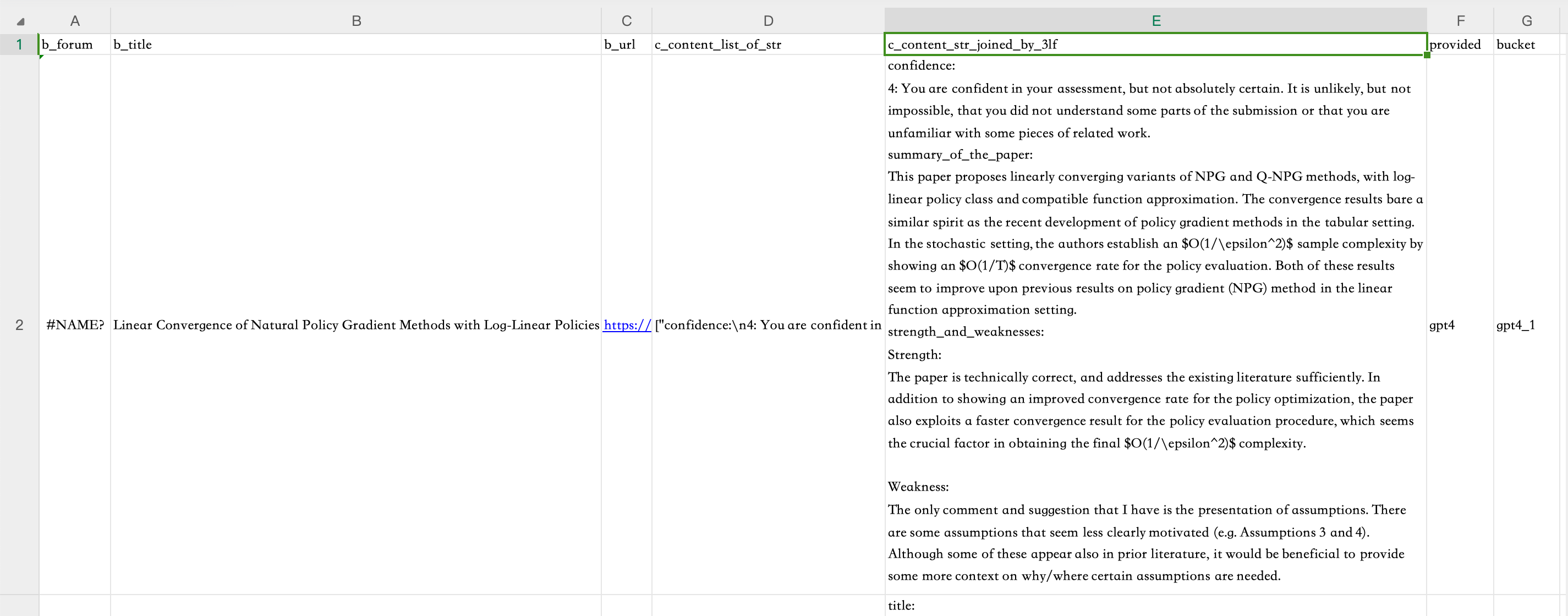
- b_forum:相关数据在paperreview网站中的id(相当于论文讨论页的id)
- b_title:Paper标题
- b_url:相关数据在paperreview网站中的链接
- c_content_list_of_str:由当前Paper对应的各个Reviews组成的列表
- c_content_str_joined_by_3lf:以3个换行符为间隔,由当前Paper对应的各个Reviews拼接成的字符串
- provided:该份数据所用于测试的模型
- bucket:该份数据所对应的序号信息
然后提示大模型生成对应review的预设问题,具体而言,有两种操作方式
- 针对每一篇paper的多个review依次去提出预设问题「比如一篇paper三个review则三段预设问题,如果每段预设问题是4个预设问题的话,三段则总计12个预设问题
- 把每一篇paper的所有review一次性给到大模型,让大模型一次性生成所有review所对应的全部预设问题
至于完整代码,参见七月官网的大模型商用项目之审稿微调实战营
template_prompt = \
"""
Analyzing the provided review, identify a set of questions that the reviewer is attempting to address regarding the paper without being too specific.
You should output three aspects of content, including a set of questions, the causes of these questions, and the information about the questions in reviews.
The given reviews is between the "######".
######
{}
######
You should output according to the following format:
Questions:
[]
Causes of these questions:
[]
Informations:
[]
"""2.3.2 对于大模型生成的prompt进行打分
// 待更
第三部分 PeerRead:根据review给paper的各方面要点打分
昨晚在思考:如何评判一篇论文是否是好论文,或是否可以中稿顶会,然后无意中看到这篇论文:A Dataset of Peer Reviews (PeerRead): Collection, Insights and NLP Applications

接下来,咱们好好看下这篇论文
3.1 PeerRead的两个工作及对我司审稿GPT的启发
3.1.1 PeerRead的两个工作:预测论文是否能被接受、根据paper的review给paper打分
2018年,来自CMU、艾伦人工智能研究所等机构的研究者提出了同行评审数据集PeerRead,其对应论文为《A Dataset of Peer Reviews (PeerRead): Collection, Insights and NLP Applications》,对应的GitHub为:https://github.com/allenai/PeerRead
PeerRea主要做了两个工作
- 给定论文,预测其是否会被某个会议接收(ground truth自然是该篇论文的实际中稿情况),用的模型有逻辑回归、SVM、神经网络二分类、随机森林等
- 给定论文的review,预测论文在某些方面的数值评分,比如新颖性能得几分,比如1-5分
In the second task, given a textual review, we predict the aspect scores for the paper such as novelty, substance and meaningful comparison
至于预测分值所参照的的「ground truth——人工评分」是怎么来的呢?具体步骤是
a) 先爬取openreview上一篇篇paper和其对应的review(比如某paperreview上ICLR 2017的427篇paper及其对应的1304条review)
b) 然后根据实际的review内容,给论文的各个要点人工打分(比如新颖性等各个方面均做对应评分:1-5分)
当然 这第二个工作,最终本质是为了给定论文,然后评判其在某些要点方面的评分,但模型一开始时,直接根据论文给出各个方面的评分 还是相对困难的,而由于可以爬到论文的review,从而根据review去打出论文各个方面的评分 则相对容易些
毕竟review有点类似对论文的摘要、或信息上的浓缩,且review通常涵盖很多主观上的喜好、优点 缺点,相对更容易打分
3.1.2 PeerRead的工作对我司审稿GPT的启发
首先,PeerRead的第一个工作,我们可能可以通过他们爬的的paper-review数据微调,以预测review,当然,我们要的是:他们的数据里面那些我们之前没有爬到的数据
其次,PeerRead的第二个工作——review打分模型,对我们的启发在于
- 借助18年「他们人工标注的review-review各方面要点的评分」的数据(但完整度 还有待查看,当然如果有的review不涉及某几个要点,而这也正常,毕竟不同的reviewer关注不同的要点,则可以尝试把所有review做下多聚一的摘要操作)

我们可以训练一个「新的review打分大模型」基于review给打分
- 有了上面那两个模型,最终 就可以做到:给定任意一篇论文,不但自动生成其对应的review,我们还能依次给review当中的比如7个要点 逐一打分
然后每个要点的得分乘以各自不同的权重,得到该篇论文的最终总得分
嗯,还是挺顺畅且理想化的
3.2 PeerRead论文解读
3.2.1 peerread数据集的构成
数据构成如下图所示

- peerread的作者们与Softconf会议管理系统和CoNLL 20162和ACL 20173会议的会议主席协调,允许作者和评审者选择加入他们的草稿和评审
从而便导致CoNLL 2016的22个提交有39个评审,ACL 2017的137个提交有275个评审 - 2013年,NIPS会议开始将所有被接受的论文与匿名的文本review一起发布,还附带了1-3的置信度评级
peerread因此收集了NIPS 2013-2017年间所有被接受的论文及其review,总共有9,152条review和2,420篇论文 - 此外,还收集了ICLR 2017会议的所有投稿,总共有1,304条官方匿名review,其中包括427篇论文(177篇被接受,255篇被拒绝)
- 至于arxiv上的11778篇论文,则均没带review
3.2.2 对review各个方面要点的评分
根据review的各个方面给paper评分,本质是一个多分类任务(The second task is a multi-class regression task to predict scores for seven review aspects)
- 至于哪七个方面呢?
答案是他们为每个review注释了这七个方面:适当性、清晰度、原创性、准确性、有意义的比较、内容和影响(即‘impact’, ‘substance’, ‘appropriateness’, ‘comparison’, ‘soundness’, ‘originality’ and ‘clarity’,当然,对于这7个要点,可能大部分论文的review会涉及某个几个要点更多些,而某几个要点则在大部分review中讨论的比较少),具体操作时
比如,For this task, we use the two sections of PeerRead which include aspect scores: ACL 2017 and ICLR 2017
顺道说一嘴,CoNLL 2016部分也包括方面得分,但对于训练来说太小了 - 为了预测各个方面的分数,可以训练一个模型做多分类,每个分类得到的logits对应这个类别的被预测的分数(损失函数是预测分数与人工标注的真实分数之间的均方误差),他们选择了3种架构:CNN RNN DAN
最终不单训练根据单纯review打分的模型,还训练了分别根据paper、paper+review打分的模型
不足之处在于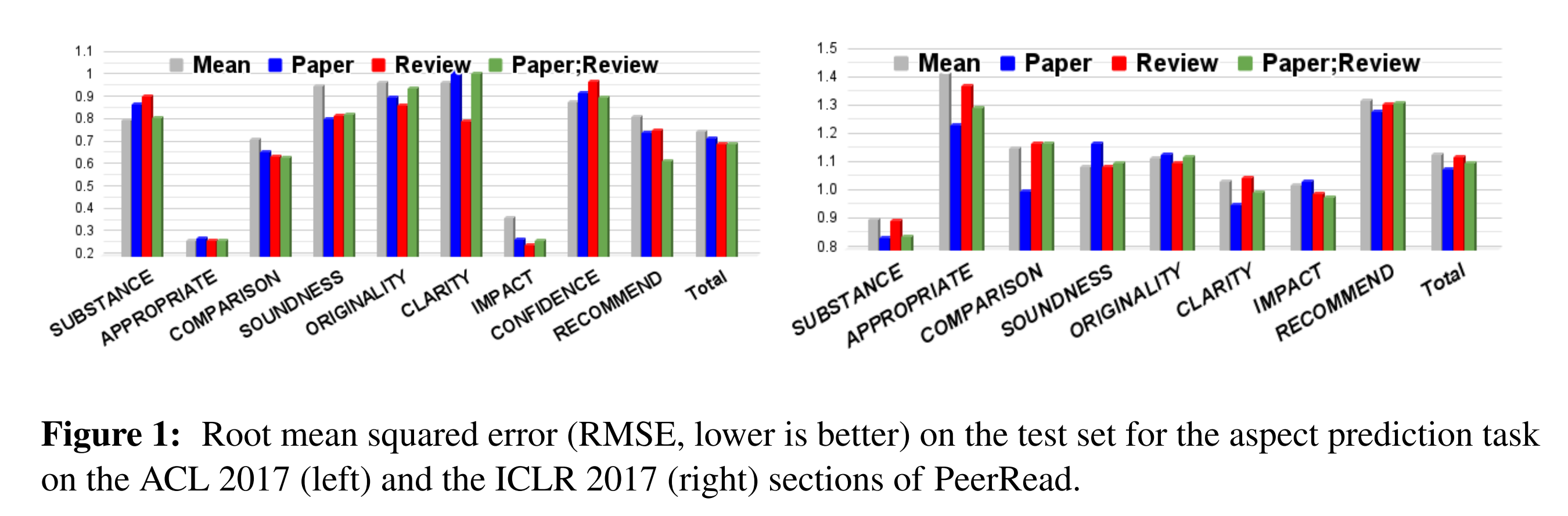
a) 用的18年或之前的模型 所以效果不会太好
b) 更何况他们当时因为由于论文往往很长,所以只取了每篇论文和review的前1000和200个token,然后在模型同时考虑论文和review时将这两个部分连接起来Since scientific papers tend to be long, we only take the first 1000 and 200 tokens of each paper and review, respectively, and concatenate the two prefixes when the model conditions on both the paper and review text


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











