







 该专栏为热销专栏榜 第14名
该专栏为热销专栏榜 第14名大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。
本文主要介绍了Perplexity的详细使用方法,希望对新手有所帮助。需要说明的是,Perplexity不需要上网工具,很方便新手和小白上手使用。Perplexity的官网链接为:https://www.perplexity.ai/ 。

1. 为什么要讲Perplexity?
虽然ChatGPT能够完成文章创作(创作故事、撰写新闻、编写论文)、代码辅助(编写代码、查找Bug)、回答各类问题。看似是无所不能,但作为一名深耕AI多年的从业者,客观的说ChatGPT的确是有史以来功能最为强大的聊天机器人,它各种实用功能于一身,而且能够在精细的提醒下修正错误信息,具有强大的互动能力。但它还是包括了一些缺点的:
- 无法连接互联网,所以无法获取最新信息。
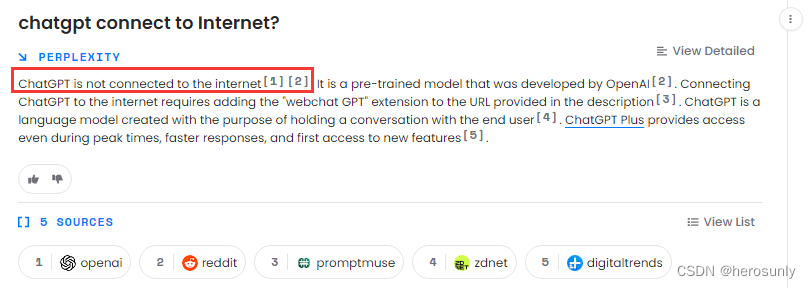
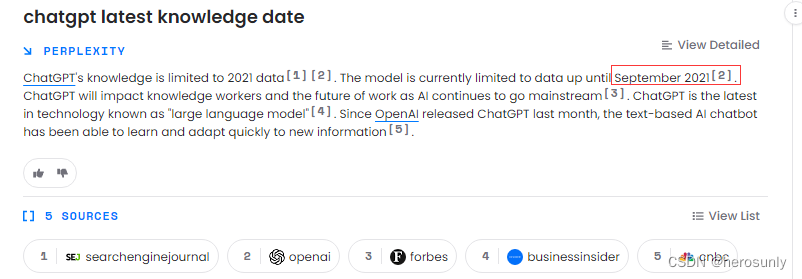
- 基于2021年9月及其以前的数据进行训练而成的,所以无法获取到近两年的事实信息
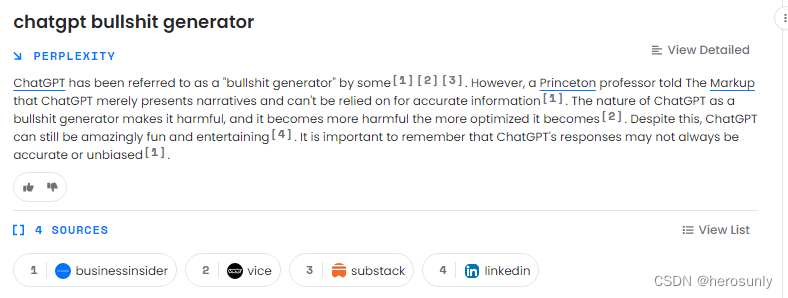
- 由于ChatGPT是纯生成式模型,并且无法给出信息来源,所以可能在部分场景中会存在一本正经的胡说八道的情况。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 370
370












 到【灌水乐园】发言
到【灌水乐园】发言









