






前置设置及代码
目录结构如下,将驱动器chromedriver.exe复制粘贴到此目录下,具体环境配置参考笔记一:
Selenium Web自动化测试学习笔记(一)-CSDN博客
首先和笔记(一)一样导入一些包用于设置谷歌浏览器的代码、管理驱动、导入用于元素定位的包By,导入时间time这个包用于使操作睡眠sleep()特定的秒数
设置并启动浏览器--创建用于设置浏览器的对象q1,保持浏览器始终打开
打开指定的网址,这里统一打开百度这个网址
from selenium import webdriver # 操作浏览器
from selenium.webdriver.chrome.options import Options # 设置谷歌浏览器
from selenium.webdriver.chrome.service import Service # 管理驱动
from selenium.webdriver.common.by import By#在元素定位里面需要定位的类型
import time
#设置+启动浏览器
def set_lauch():
#01创建一个用于设置浏览器的对象q1
q1 = Options()
#禁用沙箱-增加兼容性
q1.add_argument('--no-sandbox')
#保持浏览器打开(默认代码执行完自动关闭)
q1.add_experimental_option('detach', True)
#02创建浏览器a1并启动浏览器
a1 = webdriver.Chrome(service=Service('chromedriver.exe'), options=q1)
#return用于接收
return a1
a1 = set_lauch()
#打开指定网址
url = 'https://www.baidu.com'
a1.get(url)元素定位
要想元素定位比较准确,用多个元素定位方式如ID和Name合CLASS_NAME一起定位较好,定位更为准确,更容易找到唯一确认的元素
1--ID
例:百度的输入框范围内右键并点击检查,定位得到的id的value值为kw

同理,在百度一下的按钮范围内右键并点击检查 ,定位得到的id的value值为su
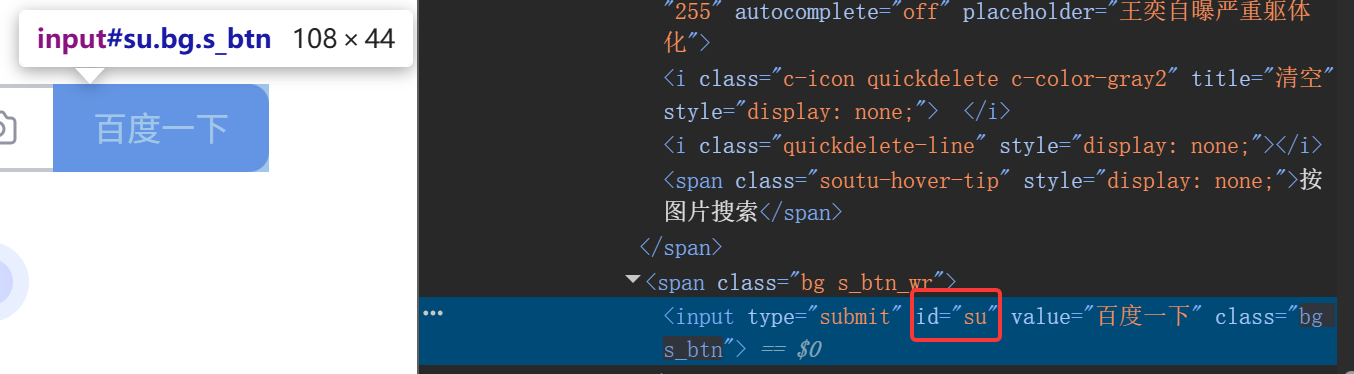
代码之ID实现元素定位,并实现元素交互如下面的元素输入和元素点击:
a1.find_element(By.ID, 'kw').send_keys('周杰伦年轻')#输入框输入周杰伦年轻
a1.find_element(By.ID,'su').click()#点击百度一下这个按钮结果:
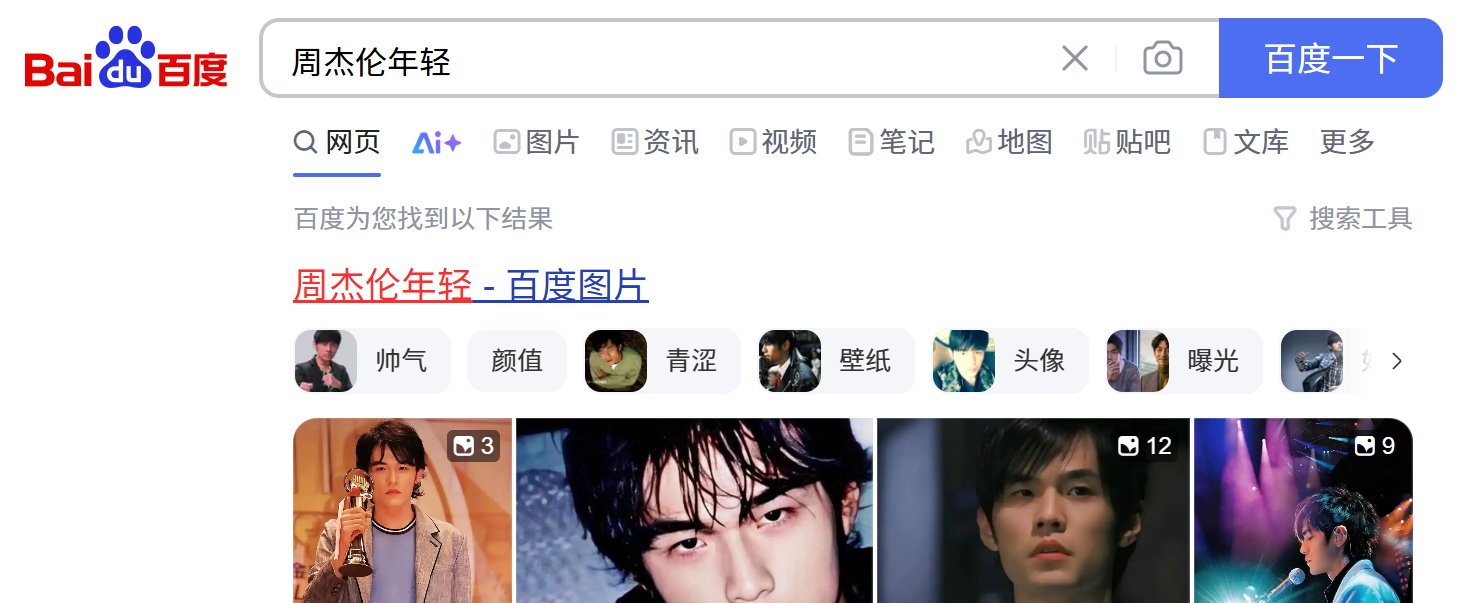
优点:ID定位一般来说比较准确
缺点:有些元素没有ID,并不是所有的网页或者元素都有ID值
2--NAME
例:百度的输入框范围内右键并点击检查,定位得到的NAME的value值为wd

同理,在百度一下的按钮范围内右键并点击检查 ,定位后发现这个按钮键根本没NAME值所以不能用NAME定位,目前只能继续用ID定位
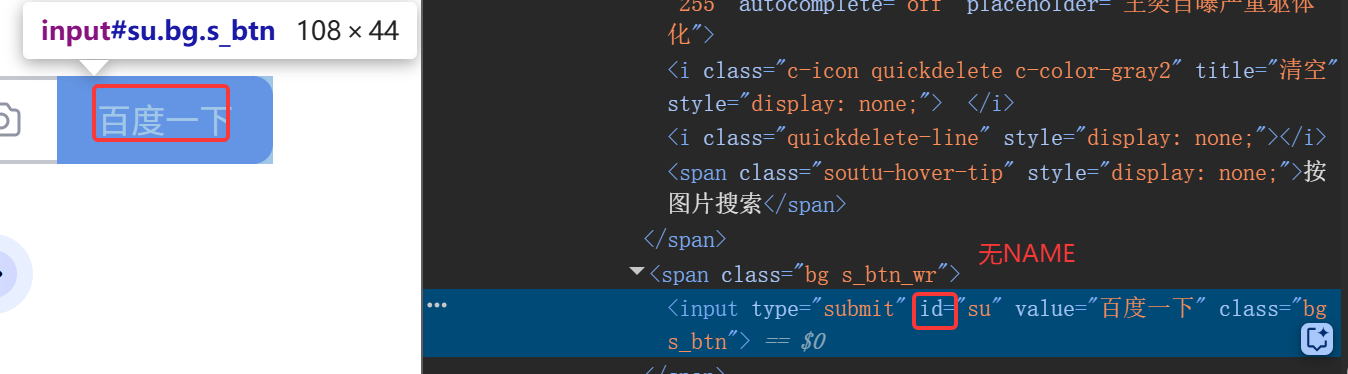
代码之NAME实现元素定位,并实现元素交互如下面的元素输入和元素点击:
a1.find_element(By.NAME, 'wd').send_keys('周杰伦年轻')#改用NAME定位,value值为wd
a1.find_element(By.ID,'su').click()#因为没NAME值,只能用ID继续定位结果:与ID搜索到的相同
优点:与ID类似,NAME定位一般来说比较准确
缺点:有些元素没有NAME,而且NAME值出现的频率比ID值出现的频率还要低,有些网站基本弃用
3--CLASS_NAME
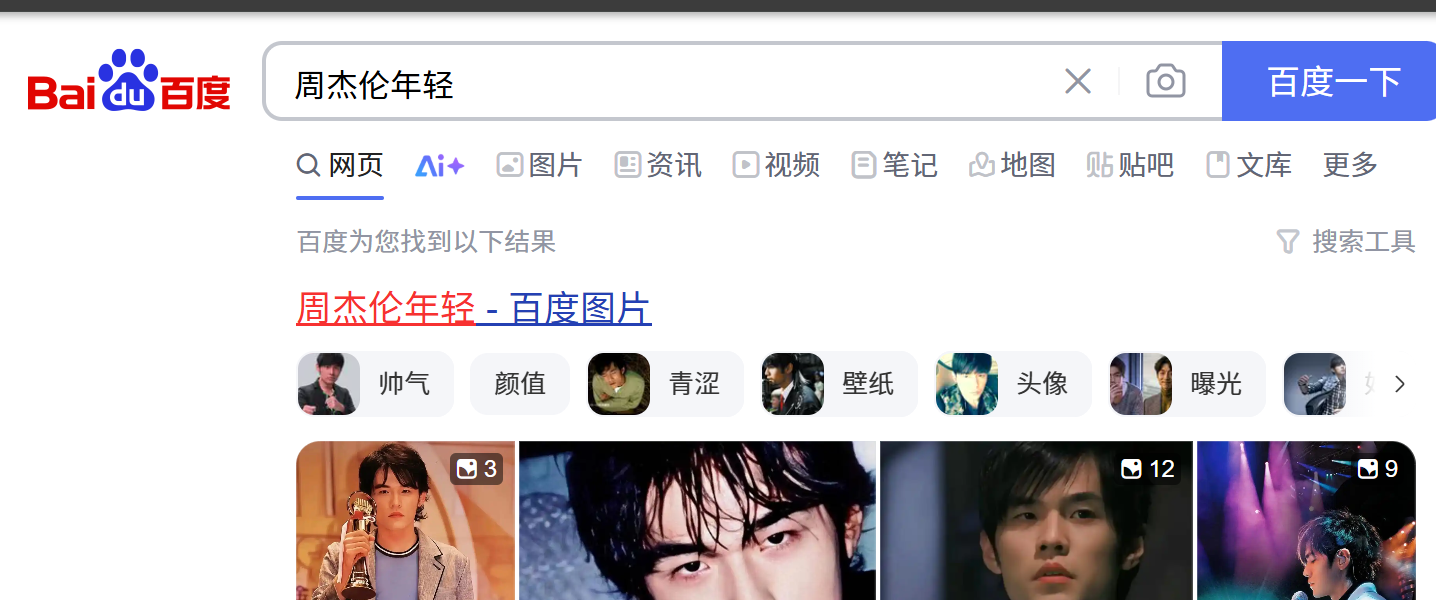
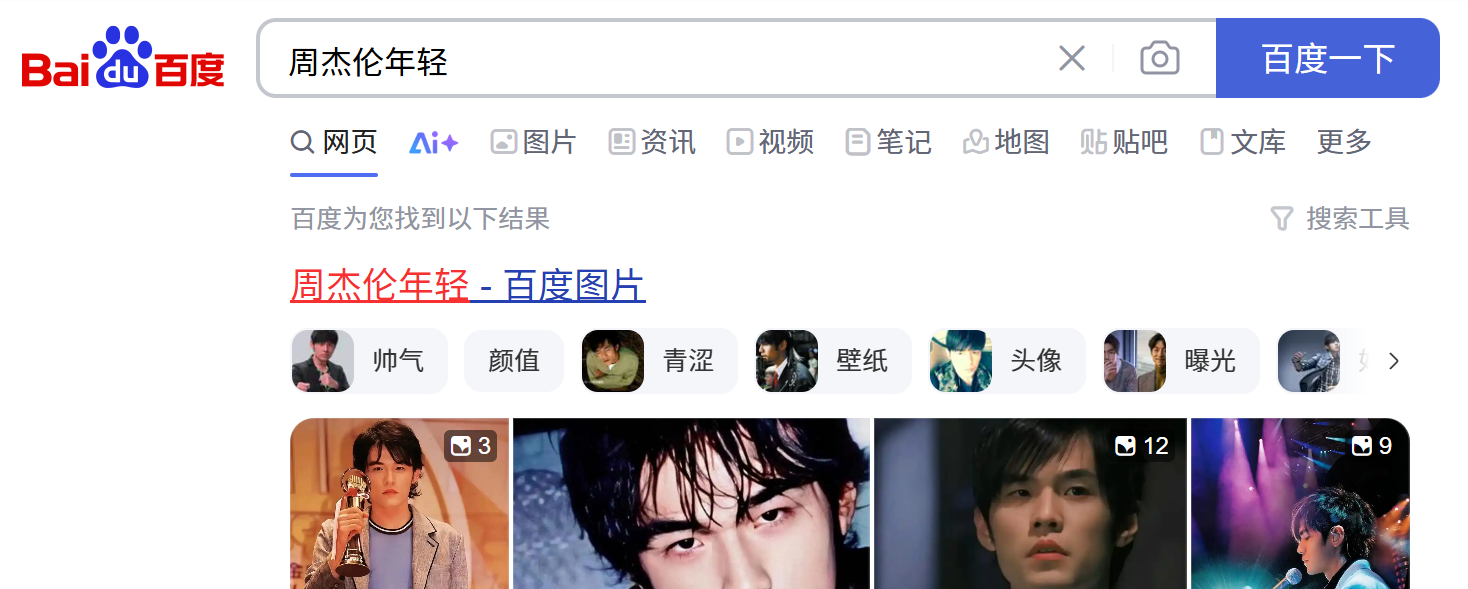
例1:实现搜索词条‘周杰伦年轻’
百度的输入框范围内右键并点击检查,定位得到的CLASS的value值为s_ipt

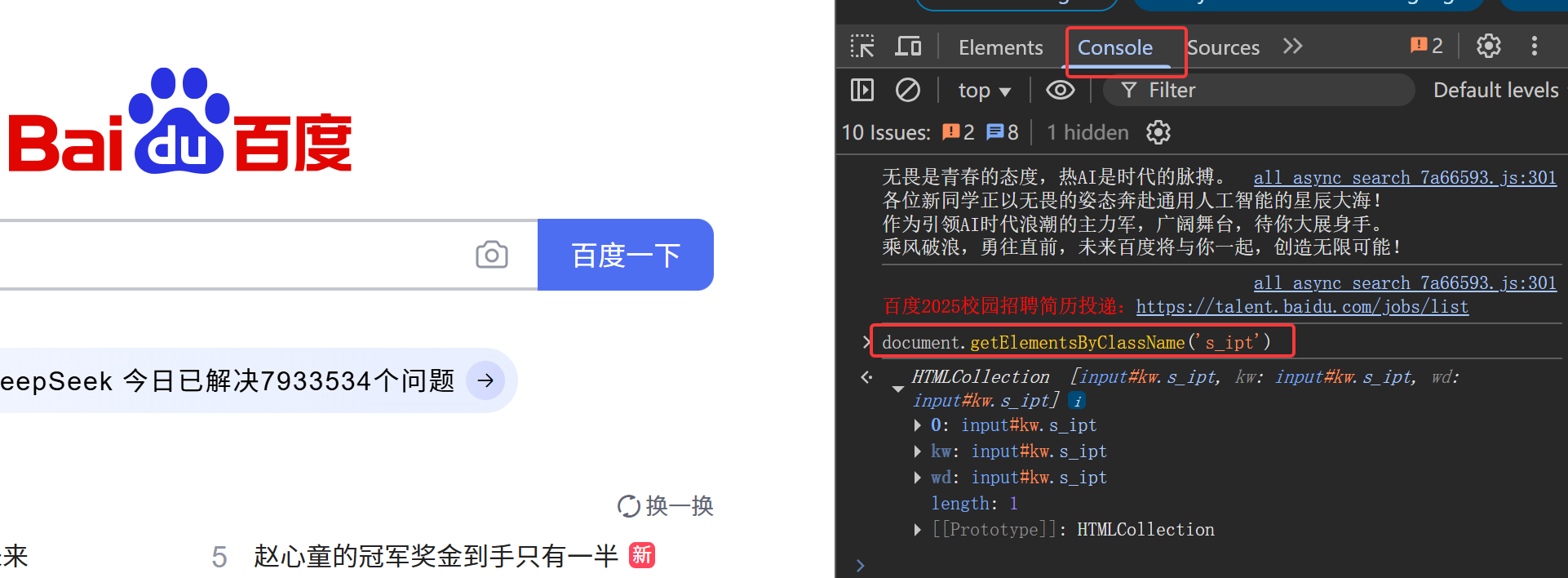
在使用这个CLASS_NAME定位前,先检查是否有重复的值 ,检查方法为先点击Console控制台,再在控制台中输入
document.getElementsByClassName('s_ipt')
如下图所示,得到的结果只有一个就是这个输入框,kw和wd分别为ID值和NAME值,说明没有重复的值
同理,在百度一下的按钮范围内右键并点击检查 ,定位得到class="bg s_btn"
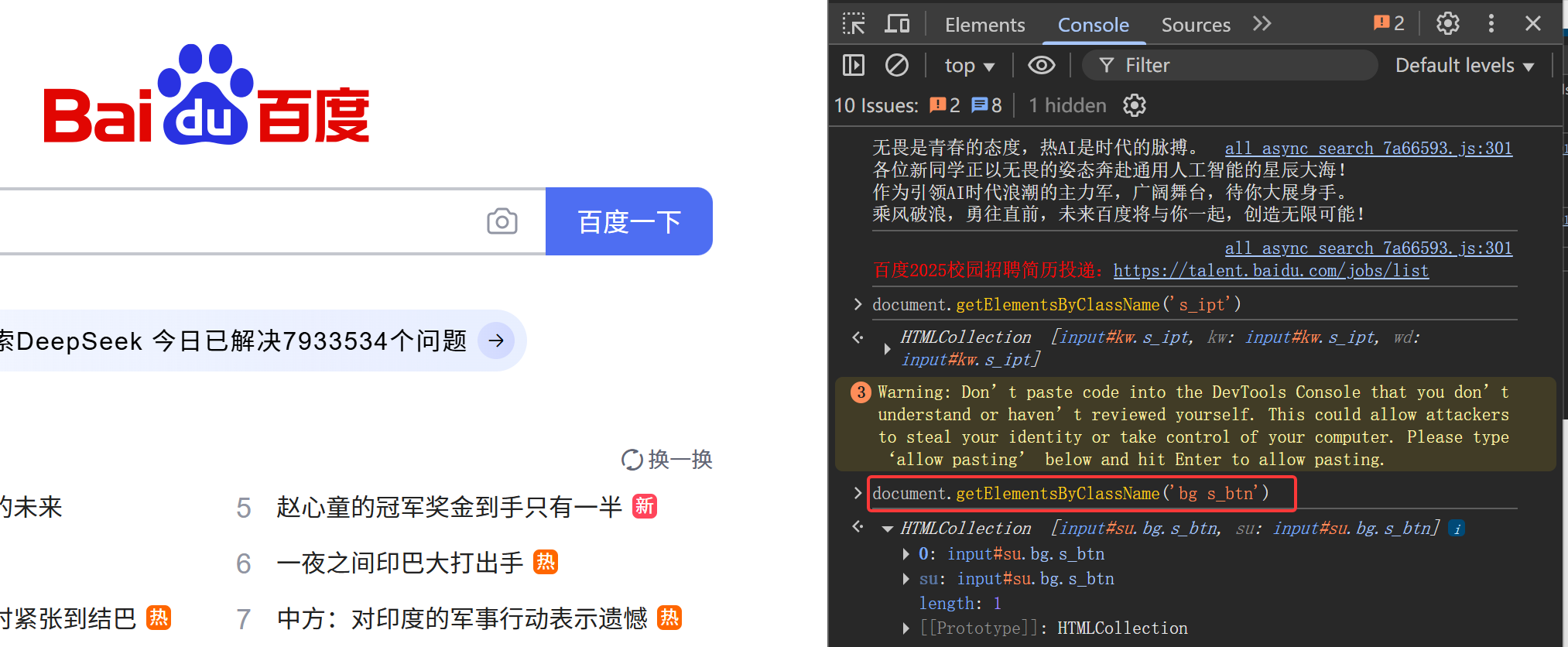
在控制台中输入如下
document.getElementsByClassName('bg s_btn')
如下图所示,得到的结果只有一个就是这个百度一下按钮的值,su是其ID值,说明没有重复的值
代码实现(有空格出错版) :
a1.find_element(By.CLASS_NAME,'s_ipt').send_keys('周杰伦年轻')#改用CLASS_NAME定位,value值为s_ipt
a1.find_element(By.CLASS_NAME,'bg s_btn').click()#改用CLASS_NAME定位,value值为bg s_btn但结果出错

出错原因:
class的value值不能含有空格,有空格定位就会定位出错,因此这种情况下面的这个百度一下的按钮只能先通过ID来定位
改正后的代码:
a1.find_element(By.CLASS_NAME,'s_ipt').send_keys('周杰伦年轻')#改用CLASS_NAME定位,value值为s_ipt
a1.find_element(By.ID,'su').click()#因class值有空格,只能用id定位再次运行结果正确
例2:实现哔站番剧按钮点击
因为CLASS实质就是分类,有很多不同的元素都共用一个CLASS值,所以需要使用切片来实现,如与番剧同类型的国创、综艺、动画、电影按钮的class值都是channel-link
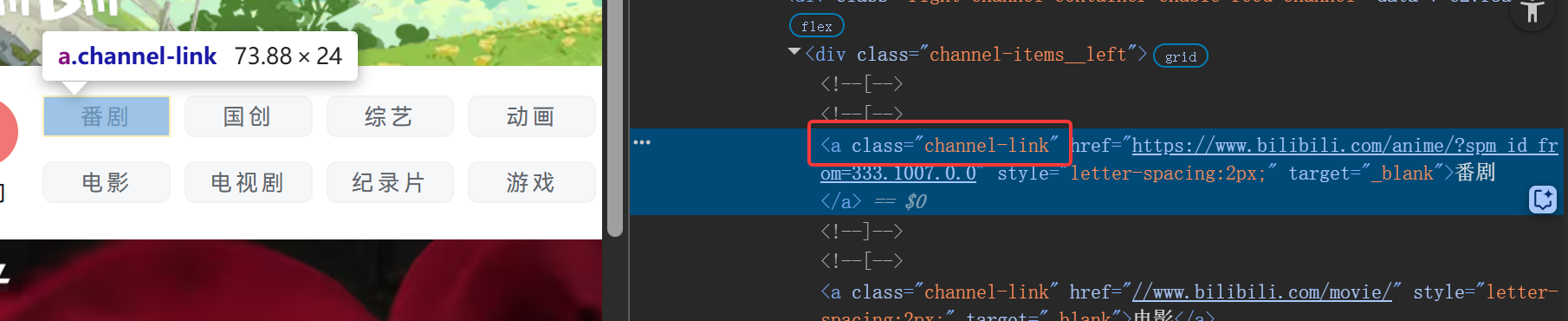
如下图搜索得到了有和番剧这个按钮一样的class值的一共有38个元素,因此不能用class唯一定位,想定位还需要借助切片来实现
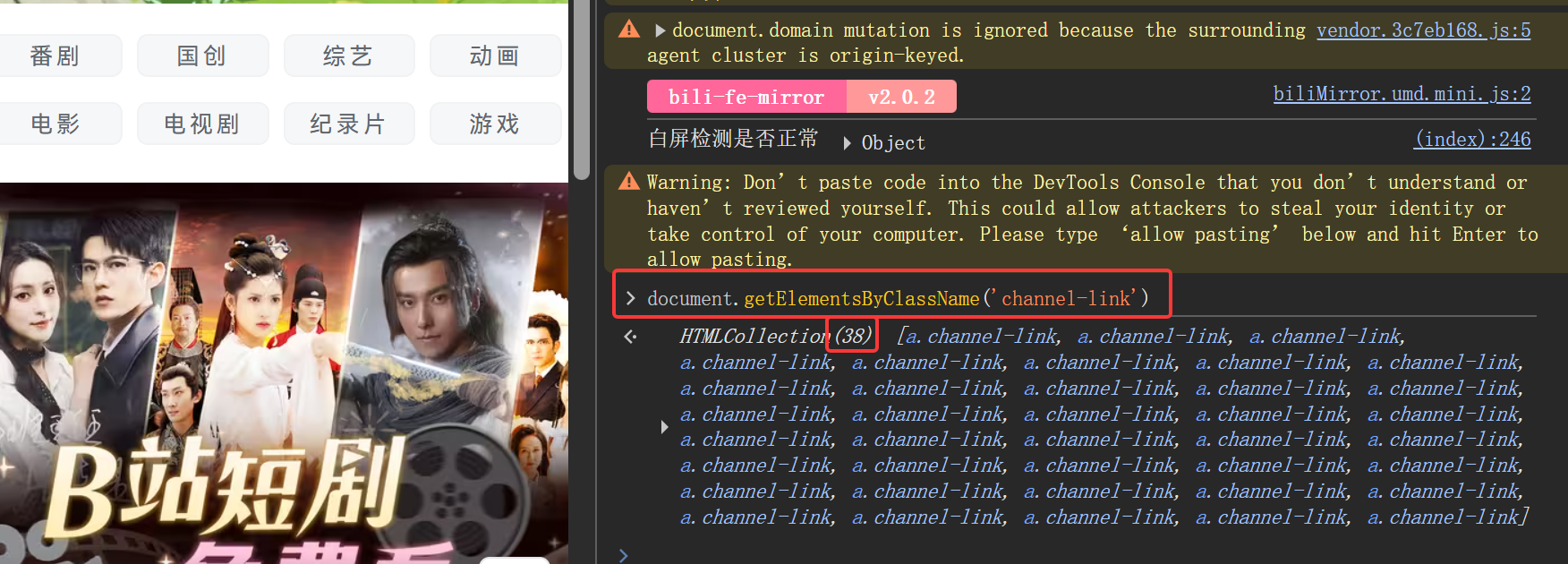
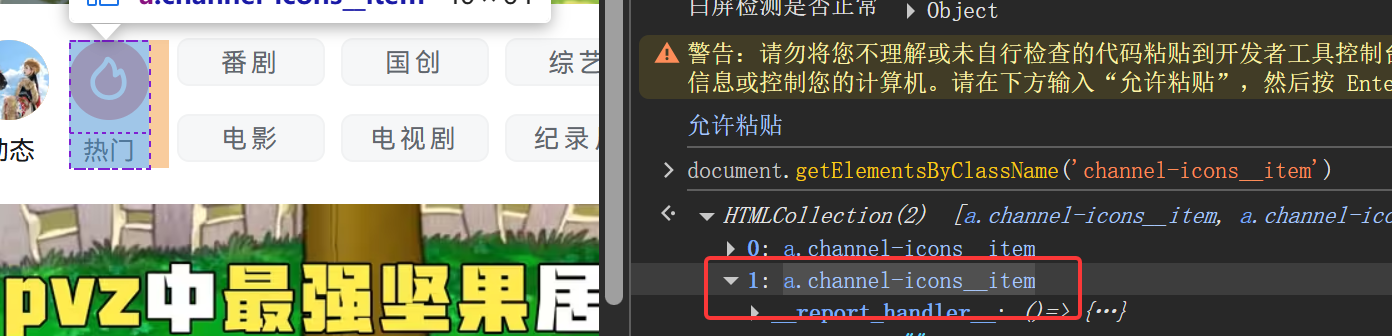
下面以这个只有两个相同类别的热门按钮为例 ,如下,class值为channel-icons__item
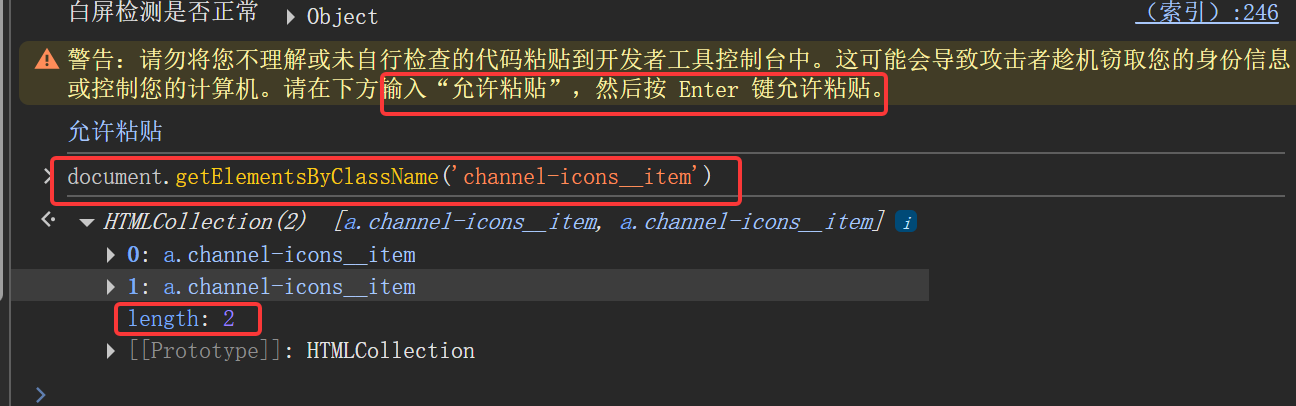
热门这个按钮的切片下标为1
代码实现:
上面这一段代码和最上面的前置代码一样,改动的地方为用a1启动浏览器打开的指定网址改为了bilibili的网址:
from selenium import webdriver # 操作浏览器
from selenium.webdriver.chrome.options import Options # 设置谷歌浏览器
from selenium.webdriver.chrome.service import Service # 管理驱动
from selenium.webdriver.common.by import By#在元素定位里面需要定位的类型
import time
#设置+启动浏览器
def set_lauch():
#01创建一个用于设置浏览器的对象q1
q1 = Options()
#禁用沙箱-增加兼容性
q1.add_argument('--no-sandbox')
#保持浏览器打开(默认代码执行完自动关闭)
q1.add_experimental_option('detach', True)
#02创建浏览器a1并启动浏览器
a1 = webdriver.Chrome(service=Service('chromedriver.exe'), options=q1)
#return用于接收
return a1
a1 = set_lauch()
#打开指定网址
url = 'https://www.bilibili.com'
a1.get(url)
#改方法为find_elements因为同样的class值的元素有两个
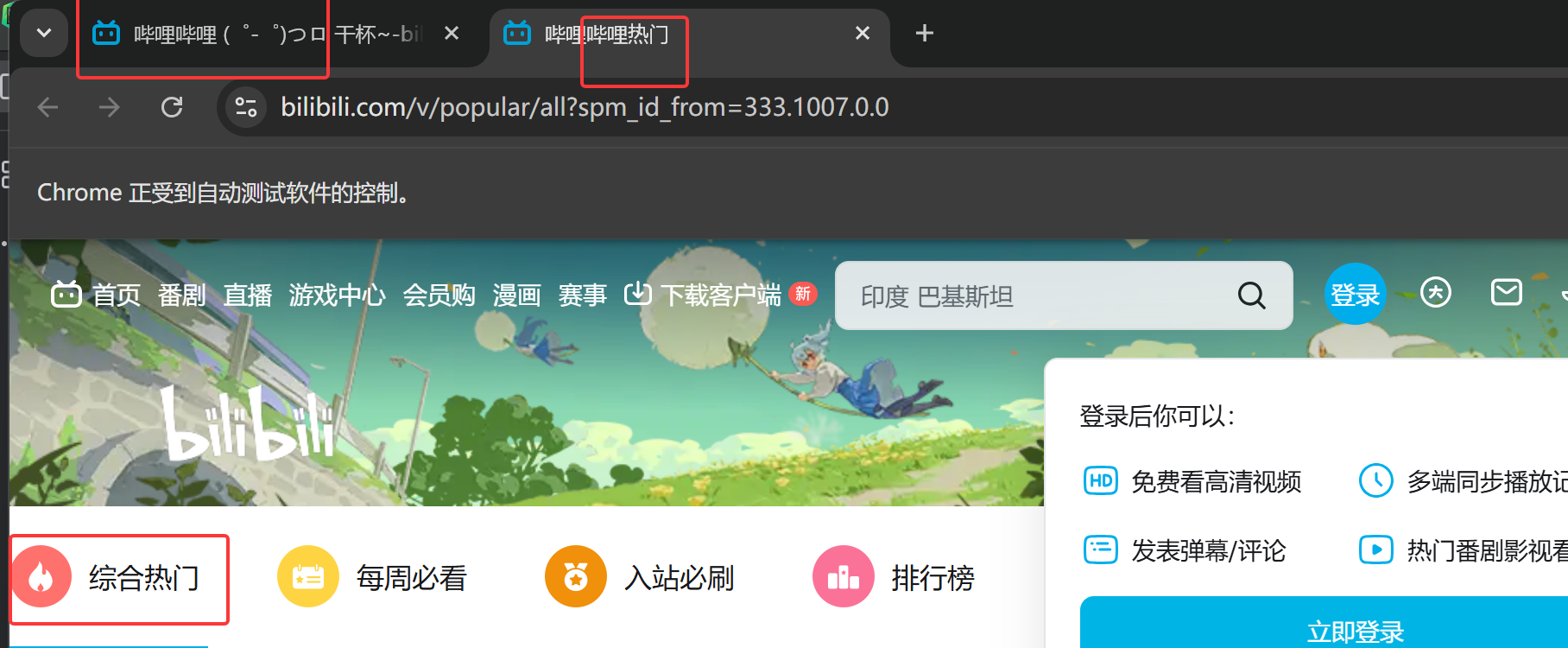
a1.find_elements(By.CLASS_NAME,'channel-icons__item')[1].click()结果:
如下图所示,打开了哔站并点击进入了热门专栏
总结 class的不足
1)class值不能有空格否则报错
2)class值重复有很多,需要切片[0]、[1]等下标定位
3)class值有很多网站是随机的
4--TAG_NAME
标签名字,查找尖括号开头<标签名字>,元素代码里面基本都有tag而且不唯一
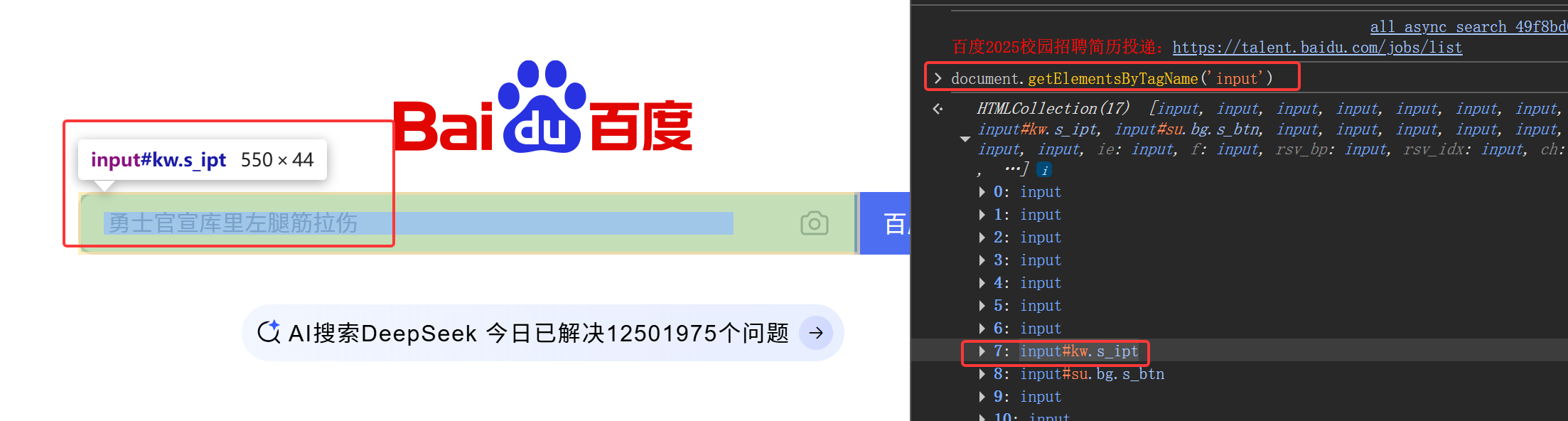
如下图搜索得到了标签tag的value值为input的一共有17个元素,因此不能用input唯一定位,想定位还需要借助切片来实现,如下图百度的输入框的标签切片下标为7
 代码实现:
代码实现:
a1 = set_lauch()
#打开指定网址--百度
url = 'https://www.baidu.com'
a1.get(url)
#利用标签定位
a1.find_elements(By.TAG_NAME, 'input')[7].send_keys('周杰伦年轻')结果: 成功在输入框搜索词条‘周杰伦年轻’
特点:
重复标的名字特别多,需要切片处理
如查找超链接<a>开头的标签,如下图一共有68个,说明百度首页的超链接超级多
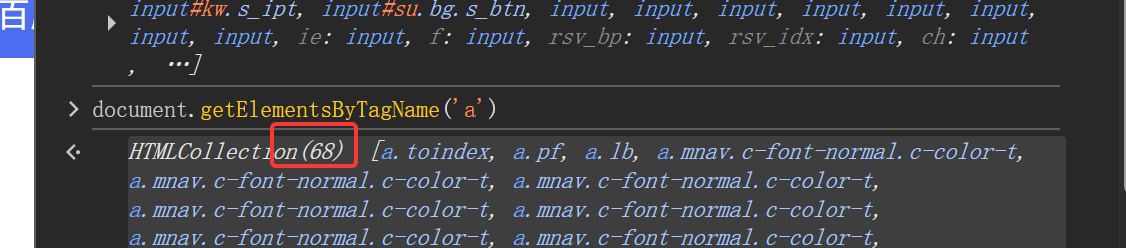
例:点击百度新闻这个链接
如下图切片下标为3

代码:
#利用标签定位--超链接
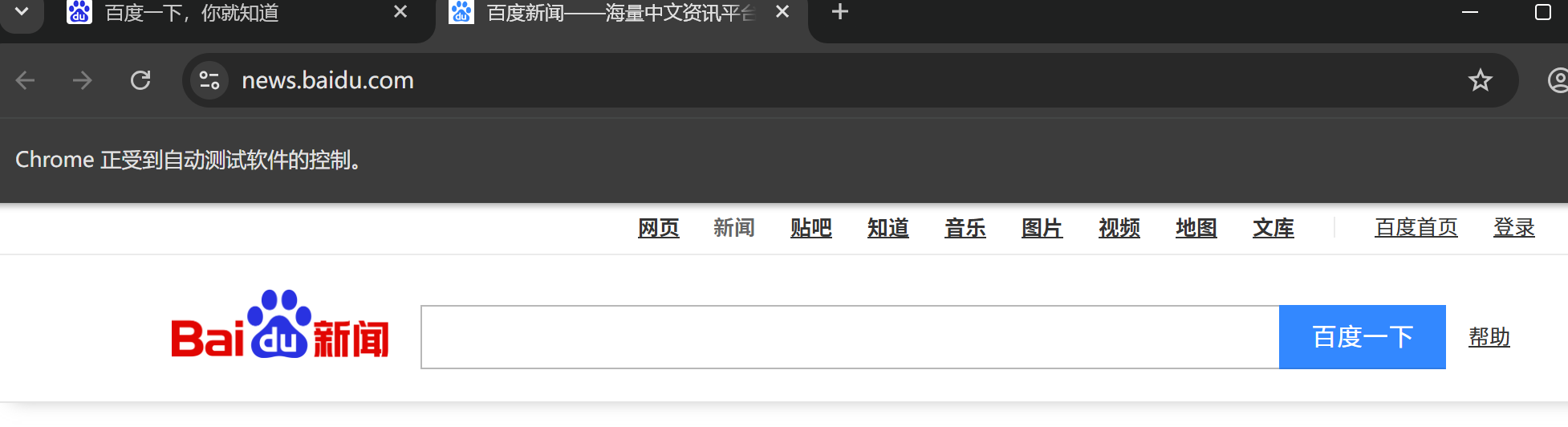
a1.find_elements(By.TAG_NAME, 'a')[3].click()结果:
成功进入百度新闻页面
此方式使用不多,要看具体情况
5--LINK_NAME(精准)
默认搜索上面tag标签的一个小分类即<a>链接标签,通过<a>标签的文本内容精准的找到这个元素
例:标签a的文本内容为‘新闻’的元素
百度页面只有唯一一个符合元素,所以查找时使用的方法是find_element而不是复数elements形式
代码:
#利用链接文本定位--通过精准链接文本找到元素
a1.find_element(By.LINK_TEXT, '新闻').click()结果:

有重复的a标签时需要使用切片定位
6--PARTIAL_LINK_TEXT(模糊)
部分链接文本,与LINK_TEXT类似,只找<a>链接标签,是LINK_TEXT的进一步改进
LINK_TEXT是精准链接文本定位,链接文本中一旦有一个元素不匹配就会定位失败;而PARTIAL_LINK_TEXT是模糊链接文本定位,只要有一个字或以上匹配就可以匹配成功,如本要匹配‘地图’,但使用PARTIAL_LINK_TEXT可以只在匹配文本中写一个字‘地’
例:打开百度地图这个标签
代码:
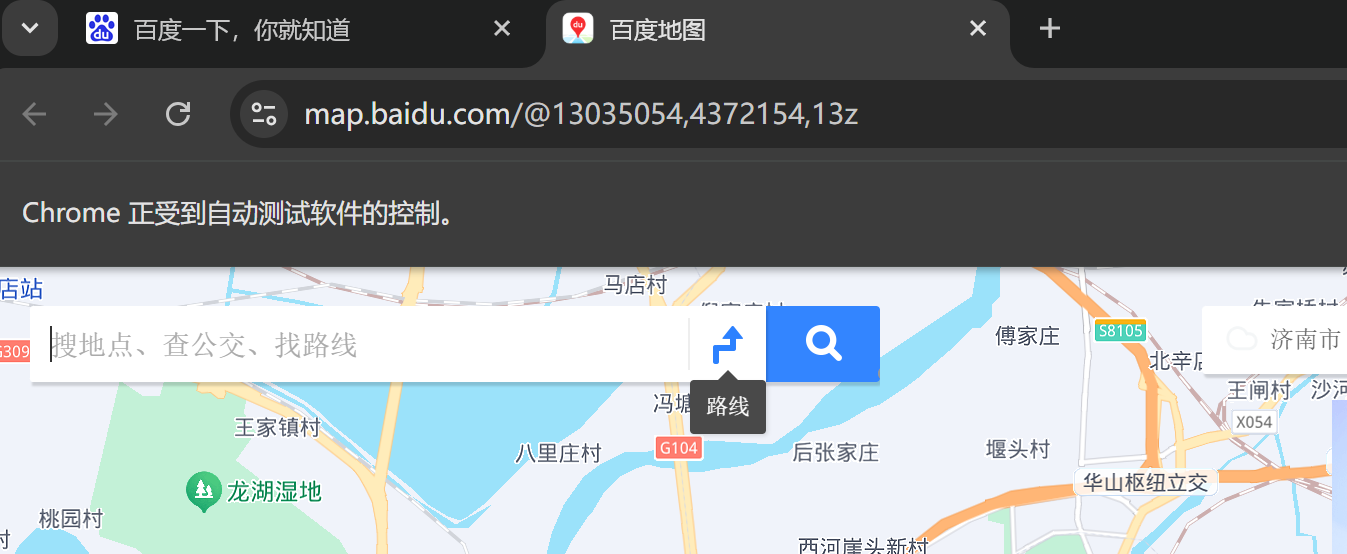
如下图只输入一个‘地’就可对链接文本‘地图’进行定位
#利用模糊链接文本定位--通过模糊匹配文本找到元素
a1.find_element(By.PARTIAL_LINK_TEXT, '地').click()结果:
7--CSS_SELECTOR(样式选择器)
多功能方式的定位,综合上面几种方式综合定位
语法:
1)id定位--要在id的value值前统一加一个‘#’号
例:输入框输入‘周杰伦年轻’--#id定位
代码:
#利用CSS样式选择器--新value=#+id
a1.find_element(By.CSS_SELECTOR, '#kw').send_keys('周杰伦年轻')结果:

2)class定位--要在class的value值前统一加上'.'
例:输入框输入‘周杰伦年轻’-- .class定位
代码:
#class值前加'.'
a1.find_element(By.CSS_SELECTOR, '.s_ipt').send_keys('周杰伦年轻')结果:

3)标签头定位--value前不加修饰符
标签符有多个,使用切片下标指定
例:输入框输入‘周杰伦年轻’-- 标签符Input定位
如下图切片下标为7

代码:
#<标签头>
a1.find_elements(By.CSS_SELECTOR, 'input')[7].send_keys('周杰伦年轻')结果:

4)通过任意类型定位 [任意类型名="value值"]
例:还是百度搜索框输入--任意类型之autocomplete

代码:
#语法:[任意类型名="value值"]
a1.find_element(By.CSS_SELECTOR, '[autocomplete="off"]').send_keys('周杰伦年轻')结果:

5)通过任意类型模糊定位 [任意类型名*="value模糊值"]
代码:
如下面的ff就是off的模糊值
#语法:[任意类型名*="value模糊值"]
a1.find_element(By.CSS_SELECTOR, '[autocomplete*="ff"]').send_keys('周杰伦年轻')结果:

6)通过任意类型模糊定位 [任意类型名^="value开头值"]
代码:
如下面的of就是off的开头值
#语法:[任意类型名^="value开头值"]
a1.find_element(By.CSS_SELECTOR, '[autocomplete^="of"]').send_keys('周杰伦年轻')结果:
7)通过任意类型模糊定位 [任意类型名$="value结尾值"]
代码:
如下面的ff就是off的开头值
#语法:[任意类型名$="value结尾值"]
a1.find_element(By.CSS_SELECTOR, '[autocomplete$="ff"]').send_keys('周杰伦年轻')结果:
8)最简单的定位方式--谷歌提示复制
右键元素控制台元素具体位置->点击复制->后面出现多种复制方式->点击selector,谷歌直接给出可以直接定位这个元素的具体值(不同元素对应不同类型)
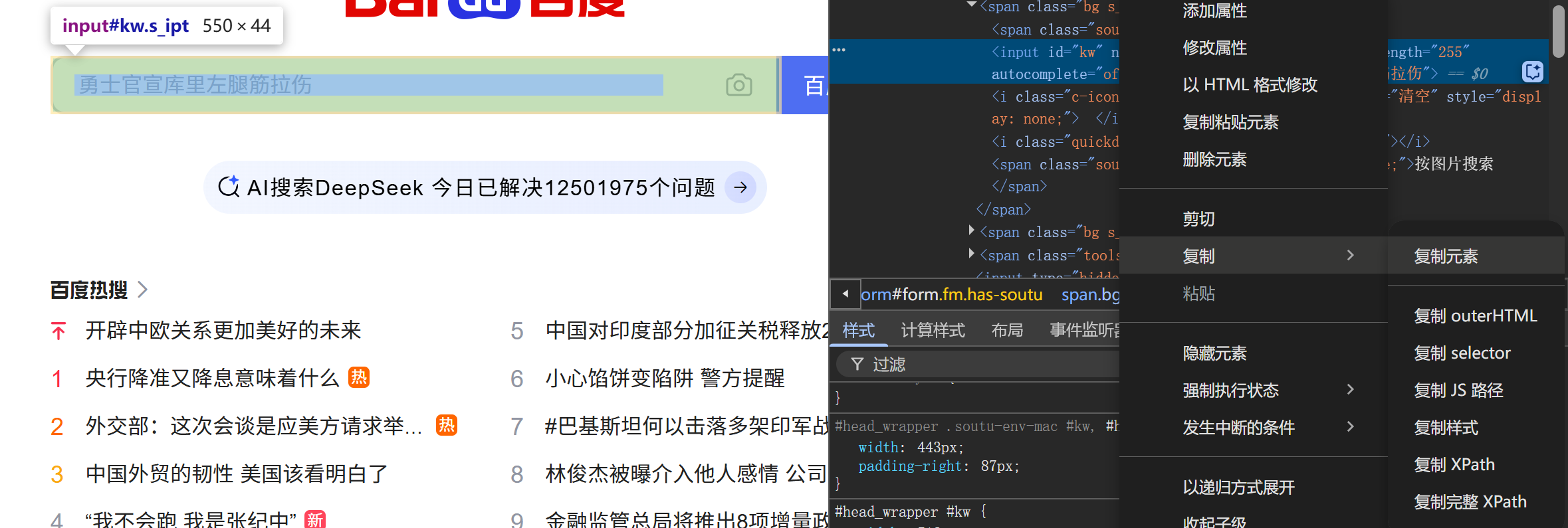
直接粘贴到‘’代表value值的单引号框中如下面阴影部分即为粘贴尽量的谷歌提供的复制
谷歌浏览器的意思就是靠这个就可以直接定位输入框
![]()
例:复制图片的value
代码:
a1.find_element(By.CSS_SELECTOR, '#s-top-left > a:nth-child(6)').click()
结果:
唯一不足:
有的标签值有可能很长
所以这个方法是实际操作中最常用的(经典前面白学,不过学了也能加深印象的)
8--XPATH
XPATH是通过属性加路径定位
1)复制xpath
同上面复制的方式,右击元素具体html部分,点击复制,点击复制xpath
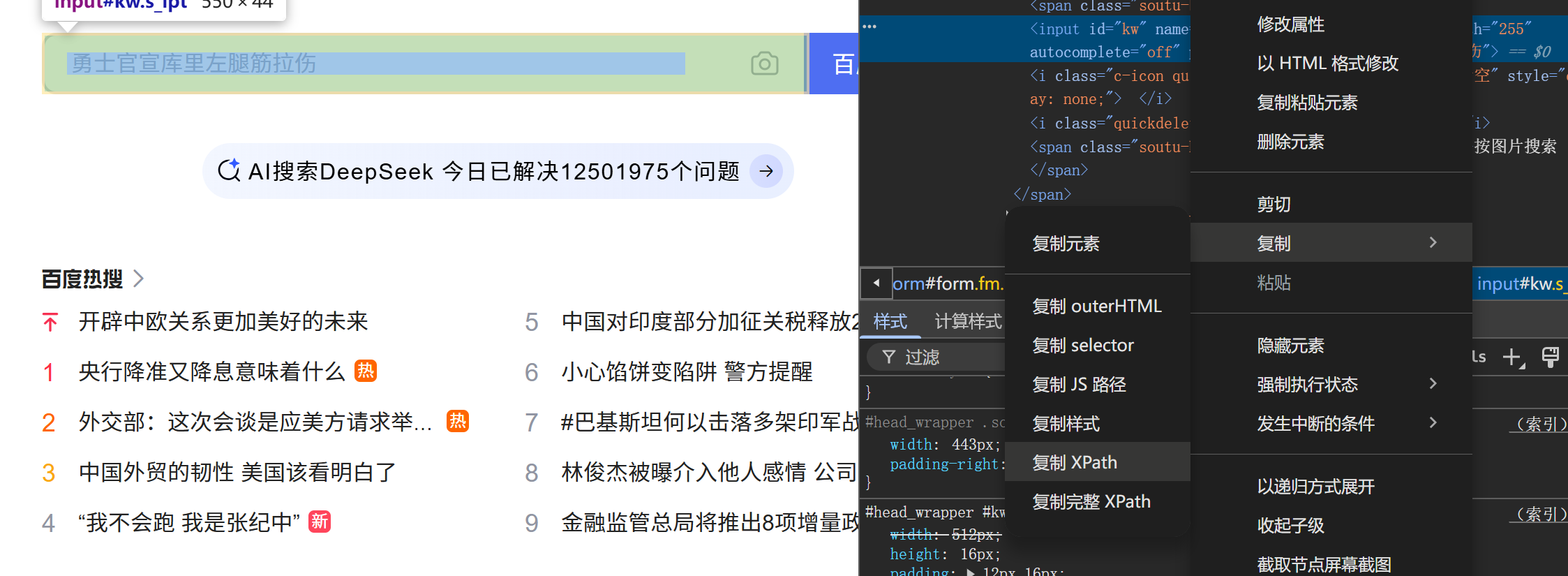
代码:
a1.find_element(By.XPATH,'//*[@id="kw"]').send_keys('周杰伦年轻')
结果:

2)复制完整xpath
和上面一样的方法找,区别是最后选择的是最下面的哪个完整xpath
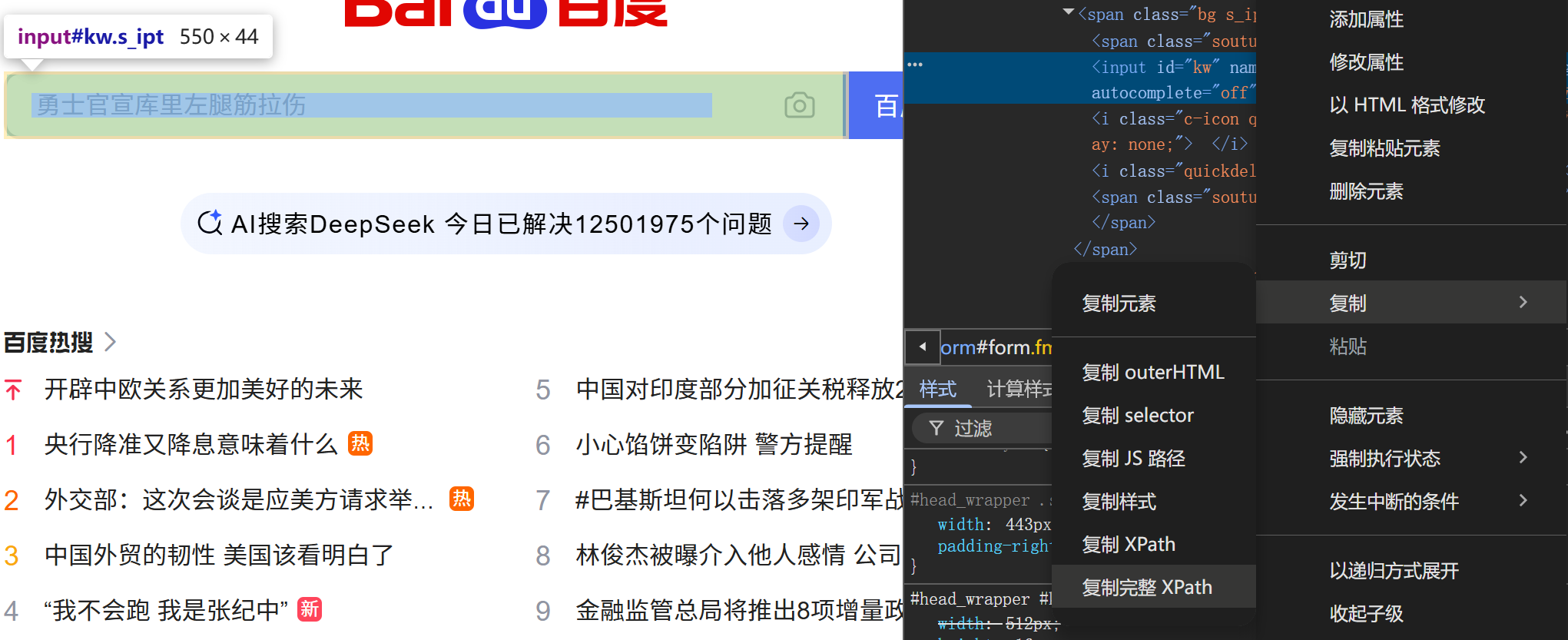
代码:
不加属性,加上完整路径
a1.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('周杰伦年轻')
优点:
因为属性的值有可能是随机的,所以为了保险期间内,用这个完整路径,不通过属性定位,所以避免了因为属性值随机造成的定位不到


















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











