






目前最火的容器技术当属Docker,而DaoliNet是一个软件定义网络(SDN)系统,其设计目的是为Docker容器提供动态、高效的链接。在Docker容器中,微服务工作负载具有轻量且短暂的性质,DaoliNet恰好适用于这种性质。
6月初,DaoliNet将入驻CSDN-CODE平台,将技术无偿贡献给开源社区,希望更多企业与开发者能在实践中应用DaoliNet,积极使用并一起推动其发展。
以下为DaoliNet介绍:
顶层特点
资源高效:当容器处于相互不主动通信,但可随时切换到提供全连接性能的状态下,容器之间的连接几乎不消耗主机资源。这同容器高效利用主机CPU资源的方式相同。使用者可以从服务器资源中获得更多;
任意分布:Docker服务器可以是办公室或家中防火墙内的笔记本电脑或PC机,也可以是自建数据中心内的服务器,亦或诸如AWS的公共云中的虚拟机,跨数据中心的通信始终加密;
网络虚拟化:可以为容器选择任意CIDR IP地址,并且在物理位置改变后,容器保持IP地址不变;
使用Open-V-Switch(OVS)的纯软件实现:可提供网络功能,如分布式交换机、路由器、网关和防火墙。系统部署采用简单的即插即用。
架构
DaoliNet的网络体系结构基于OpenFlow标准。它使用OpenFlow控制器作为智能控制平面,并用Open-V-Switches(OVSes)实现数据通路。DaoliNet中的OpenFlow控制器逻辑上为集中化的实体,但实际上为一组HA分布式类Web服务代理。OVSes在Linux内核中无所不在,因此也存在于所有Docker服务器中。
在DaoliNet网络中,所有Docker服务器处于同一以太网,彼此或实际连接或VPN连接。每个Docker服务器都像虚拟路由器一样工作,所有容器工作负载都托管在该服务器上。这些虚拟路由器遵循OpenFlow技术,不运行任何路由算法。当一个容器初始化连接时,所涉及的虚拟路由器将由OpenFlow控制器实时配置,从而建立路由路径。
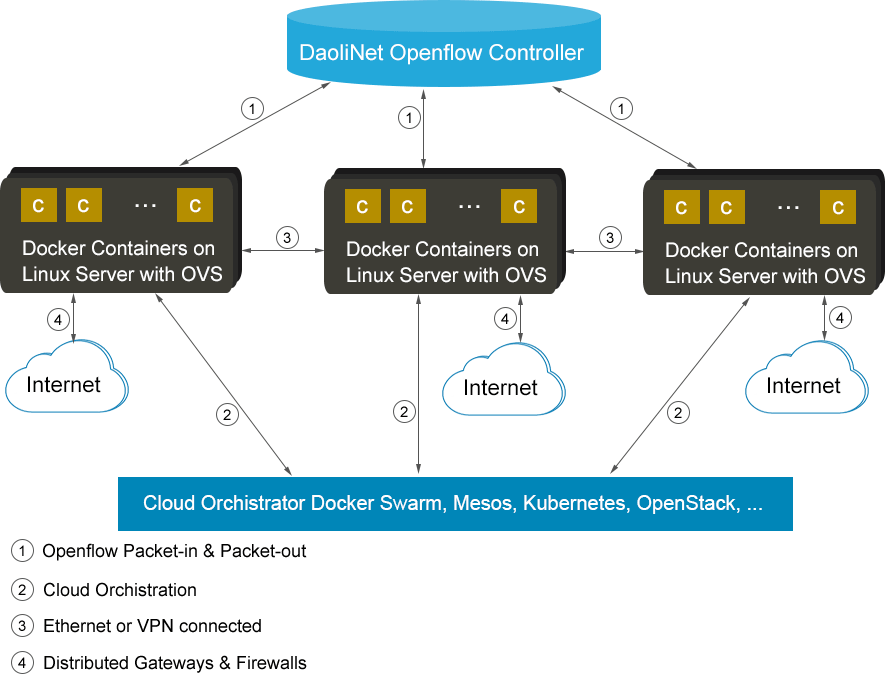
工作过程
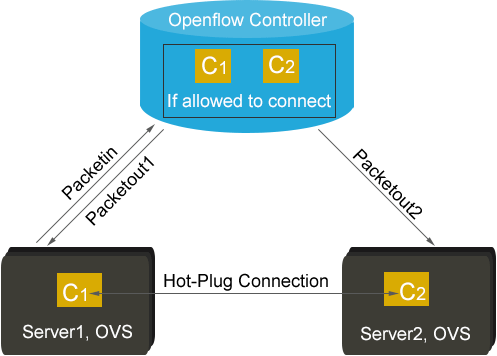
当容器发起连接,作为源路由器,宿主Docker服务器中的OVS将给OpenFlow控制器发出一个PacketIn请求。该请求是起始容器的第一个数据包。OpenFlow控制器知晓系统中作为OpenFlow路由器的全部Docker服务器,并且可发现其PacketIN;它还可以识别另一个作为目标工作负载,并承载容器的Docker服务器。第二个Docker服务器是连接的目标路由器。OpenFlow控制器将响应一对PacketOut流,其中一个流用于源服务器,另一个用于目标服务器。PacketOut流将在两个容器之间建立热插拔路由,如图2“热插拔路由的建立”所示。
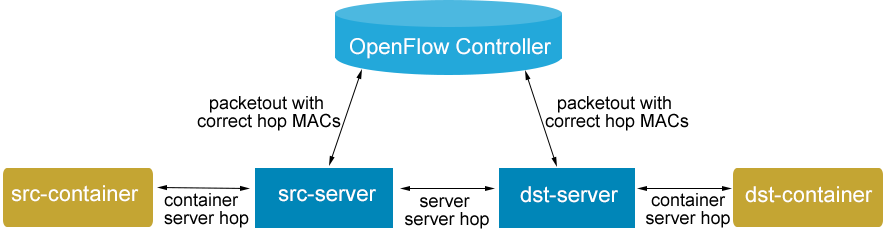
热插拔路由一般包括3个IP跳数:(1)src-容器- src -服务器;(2)src -服务器-dst-服务器;(3)dst-服务器-dst-容器。在两个容器承载于同一Docker服务器的情况下,PacketOut流路由仅包括一跳:src-容器- dst -服务器。如图3“热插拔路由的IP跳数”所示。
当一个连接变为空闲,并大于时间阈值,热插拔路由流将暂停,同时将其删除以释放服务器资源。由于热插拔路由建立速度快,所删除的闲置连接可以在重新连接时被重新热插拔。因此作为DaoliNet路由器,Docker服务器将在无连接,无资源消耗的状态下工作。这种网络资源利用率的风格与容器利用服务器CPU的风格完全匹配,因为闲置的容器会消耗很少的服务器资源。DaoliNet是一种用于连接Docker容器的动态高效的网络技术。
用于容器的简单网络
在DaoliNet中,系统中的Docker服务器正处于一种简单的状态,即彼此之间完全独立,互不知晓。该体系结构不仅节约了资源利用率,更重要的是,Docker服务器之间的独立关系极大简化了资源的管理。扩展资源库和即插即用过程(将服务器添加到库并通知OpenFlow控制器)一样简单。在所需的路由器之间没有复杂的路由表查找和更新,也没有必要使用Docker服务器来成对地运行数据包封装协议,因为这样做不仅资源利用率低,而且会使网络诊断和故障排除工具(如跟踪路由)失效。
安装
分为安装环境准备和安装两个步骤,点击此处可查看具体过程。
使用指南
在开始使用前,请确保系统已经完成安装过程,同时确保各个服务都正常启动。DaoliNet提供了一套命令行工具实现如下功能:
使用Group connect/disconnect由使用DaoliNet driver的Docker network创建的子网,在同一子网的容器默认连通;
在任何主机中使用connect/disconnect连接任意两个容器;
设置防火墙策略控制容器访问行为。
点击查看具体操作细节:
关于CSDN-CODE
CODE是国内最大的IT技术社区CSDN旗下的代码托管与社交编程平台。
CODE以代码托管与社交编程为主要切入点,力求搭建起开发者间沟通协作的桥梁,为开发者提供一个纯技术的交流环境,努力培养开发者使用和维护开源软件的习惯、倡导开放协作的精神、以期促进开源文化、改善国内软件开发环境。此外,CODE业务平台所使用的Git技术和社交编程理念在业界代表先进的技术和理念,这一技术和理念的推广将有助于革新软件开发的传统思路,提升我国软件工程水平。
CODE平台一直希望能把体验和功能场景做到“极致”,抱着这样的愿景,产品不断优化细节,也不断推出新功能,如在线集成开发环境C-IDE等,致力于为广大开发者提供尽可能的便利之处。
体验CODE:https://code.csdn.net
了解C-IDE:https://code.csdn.net/help/CSDN_Code/code_support/C-IDE_Index
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









