







 本文介绍了基于深度学习的生成模型,包括VAE、GAN及其变种Info-GAN。VAE利用变分推导进行建模,通过Encoder和Decoder实现图像生成;GAN通过对抗学习,让生成模型与判别模型互相博弈以提高生成效果;InfoGAN则通过约束互信息,提升隐变量的可解释性,能生成具有特定特征的图像。
本文介绍了基于深度学习的生成模型,包括VAE、GAN及其变种Info-GAN。VAE利用变分推导进行建模,通过Encoder和Decoder实现图像生成;GAN通过对抗学习,让生成模型与判别模型互相博弈以提高生成效果;InfoGAN则通过约束互信息,提升隐变量的可解释性,能生成具有特定特征的图像。
编者按:本书节选自图书《深度学习轻松学》第十章部分内容,书中以轻松直白的语言,生动详细地介绍了深层模型相关的基础知识,并深入剖析了算法的原理与本质。同时还配有大量案例与源码,帮助读者切实体会深度学习的核心思想和精妙之处。
本章将为读者介绍基于深度学习的生成模型。前面几章主要介绍了机器学习中的判别式模型,这种模型的形式主要是根据原始图像推测图像具备的一些性质,例如根据数字图像推测数字的名称,根据自然场景图像推测物体的边界;而生成模型恰恰相反,通常给出的输入是图像具备的性质,而输出是性质对应的图像。这种生成模型相当于构建了图像的分布,因此利用这类模型,我们可以完成图像自动生成(采样)、图像信息补全等工作。
在深度学习之前已经有很多生成模型,但苦于生成模型难以描述难以建模,科研人员遇到了很多挑战,而深度学习的出现帮助他们解决了不少问题。本章就介绍基于深度学习思想的生成模型——VAE和GAN,以及GAN的变种模型。
VAE
本节将为读者介绍基于变分思想的深度学习的生成模型——Variational autoencoder,简称VAE。
生成式模型
前面的章节里读者已经看过很多判别式模型。这些模型大多有下面的规律:已知观察变量X,和隐含变量z,判别式模型对p(z|X)进行建模,它根据输入的观察变量x得到隐含变量z出现的可能性。生成式模型则是将两者的顺序反过来,它要对p(X|z)进行建模,输入是隐含变量,输出是观察变量的概率。
可以想象,不同的模型结构自然有不同的用途。判别模型在判别工作上更适合,生成模型在分布估计等问题上更有优势。如果想用生成式模型去解决判别问题,就需要利用贝叶斯公式把这个问题转换成适合自己处理的样子:
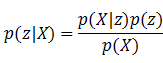
对于一些简单的问题,上面的公式还是比较容易解出的,但对于一些复杂的问题,找出从隐含变量到观察变量之间的关系是一件很困难的事情,生成式模型的建模过程会非常困难,所以对于判别类问题,判别式模型一般更适合。
但对于“随机生成满足某些隐含变量特点的数据”这样的问题来说,判别式模型就会显得力不从心。如果用判别式模型生成数据,就要通过类似于下面这种方式的方法进行。
第一步,利用简单随机一个X。
第二步,用判别式模型计算p(z|X)概率,如果概率满足,则找到了这个观察数据,如果不满足,返回第一步。
这样用判别式模型生成数据的效率可能会十分低下。而生成式模型解决这个问题就十分简单,首先确定好z的取值,然后根据p(X|z)的分布进行随机采样就行了。
了解了两种模型的不同,下面就来看看生成式模型的建模方法。
Variational Lower bound
虽然生成模型和判别模型的形式不同,但两者建模的方法总体来说相近,生成模型一般也通过最大化后验概率的形式进行建模优化。也就是利用贝叶斯公式:
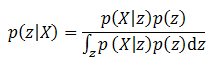
这个公式在复杂的模型和大规模数据面前极难求解。为了解决这个问题,这里将继续采用变分的方法用一个变分函数q(z)代替p(z|X)。第9章在介绍Dense CRF时已经详细介绍了变分推导的过程,而这一次的推导并不需要做完整的变分推导,只需要利用变分方法的下界将问题进行转换即可。
既然希望用q(z)这个新函数代替后验概率p(z|X),那么两个概率分布需要尽可能地相近,这里依然选择KL散度衡量两者的相近程度。根据KL公式就有:
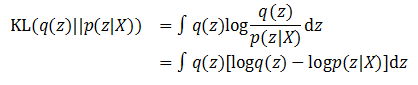
根据贝叶斯公式进行变换,就得到了:
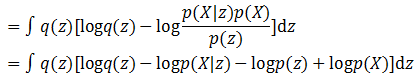
由于积分的目标是z,这里再将和z无关的项目从积分符号中拿出来,就得到了:
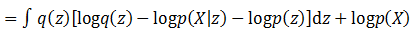
将等式左右项目交换,就得到了下面的公式:
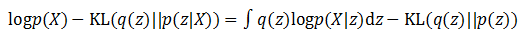
虽然这个公式还是很复杂,因为KL散度的性质,这个公式中还是令人看到了一丝曙光。
首先看等号左边,虽然p(X)的概率分布不容易求出,但在训练过程中当X已经给定,p(X)已经是个固定值不需要考虑。如果训练的目标是希望KL(q(z)||p(z|X))尽可能小,就相当于让等号右边的那部分尽可能变大。等号右边的第一项实际上是基于q(z)概率的对数似然期望,第二项又是一个负的KL散度,所以我们可以认为,为了找到一个好的q(z),使得它和p(z|X)尽可能相近,实现最终的优化目标,优化的目标将变为:
- 右边第一项的log似然的期望最大化:
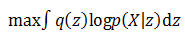
- 右边第二项的KL散度最小化:
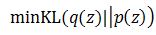
右边两个项目的优化难度相对变小了一些,下面就来看看如何基于它们做进一步的计算。
Reparameterization Trick
为了更方便地求解上面的公式,这里需要做一点小小的trick工作。上面提到了q(z)这个变分函数,为了近似后验概率,它实际上代表了给定某个X的情况下z的分布情况,如果将它的概率形式写完整,那么它应该是q(z|X)。这个结构实际上对后面的运算产生了一些障碍,那么能不能想办法把X抽离出来呢?
例如,有一个随机变量a服从均值为1,方差为1的高斯分布,那么根据高斯分布的性质,随机变量b=a-1将服从均值为0,方差为1的高斯分布,换句话说,我们可以用一个均值为0,方差为1的随机变量加上一个常量1来表示现在的随机变量a。这样一个随机变量就被分成了两部分——一部分是确定的,一部分是随机的。
实际上,q(z|X)也可以采用上面的方法完成。这个条件概率可以拆分成两部分,一部分是一个观察变量g?(X),它代表了条件概率的确定部分,它的值和一个随机变量的期望值类似;另一部分是随机变量ε,它负责随机的部分,基于这样的表示方法,条件概率中的随机性将主要来自这里。
这样做有什么好处呢?经过变换,如果z条件概率值完全取决于ε的概率。也就是说如果z(i)=g?(X+ε(i)),那么q(z(i))=p(ε(i)),那么上面关于变分推导的公式就变成了下面的公式:
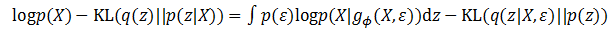
这就是替换的一小步,求解的一大步!这个公式已经很接近问题最终的答案了,既然?完全决定了z的分布,那么假设一个?服从某个分布,这个变分函数的建模就完成了。如果?服从某个分布,那么z的条件概率是不是也服从这个分布呢?不一定。z的条件分布会根据训练数据进行学习,由于经过了函数g?()的计算,z的分布有可能产生了很大的变化。而这个函数,就可以用深度学习模型表示。前面的章节读者已经了解到深层模型的强大威力,那么从一个简单常见的随机变量映射到复杂分布的变量,对深层模型来说是一件很平常的事情,它可以做得很好。
于是这个假设?服从多维且各维度独立高斯分布。同时,z的先验和后验也被假设成一个多维且各维度独立的高斯分布。下面就来看看两个优化目标的最终形式。
Encoder和Decoder的计算公式
回顾一下10.1.2的两个优化目标,下面就来想办法求解这两个目标。首先来看看第二个优化目标,也就是让公式右边第二项KL(q(z)||p(z))最小化。刚才z的先验被假设成一个多维且各维度独立的高斯分布,这里可以给出一个更强的假设,那就是这个高斯分布各维度的均值为0,协方差为单位矩阵,那么前面提到的KL散度公式就从:
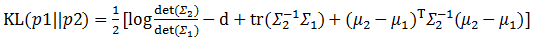
瞬间简化成为:
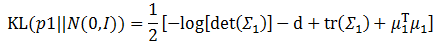
前面提到了一个用深层网络实现的模型g?(X,?),它的输入是一批图像,输出是z,因此这里需要它通过X生成z,并将这一个批次的数据汇总计算得到它们的均值和方差。这样利用上面的公式,KL散度最小化的模型就建立好了。
实际计算过程中不需要将协方差表示成矩阵的形状,只需要一个向量σ1来表示协方差矩阵的主对角线即可,公式将被进一步简化:
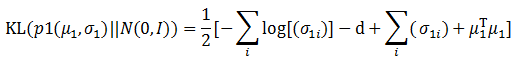
由于函数g?()实现了从观测数据到隐含数据的转变,因此这个模型被称为Encoder模型。
接下来是第一个优化目标,也就是让公式左边第一项的似然期望最大化。这一部分的内容相对简单,由于前面的Encoder模型已经计算出了一批观察变量X对应的隐含变量z,那么这里就可以再建立一个深层模型,根据似然进行建模,输入为隐含变量z,输出为观察变量X。如果输出的图像和前面生成的图像相近,那么就可以认为似然得到了最大化。这个模型被称为Decoder,也就是本章的主题——生成模型。
到这里VAE的核心计算推导就结束了。由于模型推导的过程有些复杂,下面就来看看VAE实现的代码,同时来看看VAE模型生成的图像是什么样子。
实现
本节要介绍VAE模型的一个比较不错的实现——GitHub - cdoersch/vae_tutorial: Caffe code to accompany my Tutorial on Variational Autoencoders(https://link.zhihu.com/?target=https%3A//github.com/cdoersch/vae_tutorial),这个工程还配有一个介绍VAE的文章[2],感兴趣的读者可以阅读,读后会有更多启发。这个实现使用的目标数据集依然是MNIST,模型的架构如图10-1所示。为了更好地了解模型的架构,这里将模型中的一些细节隐去,只留下核心的数据流动和Loss计算部分。
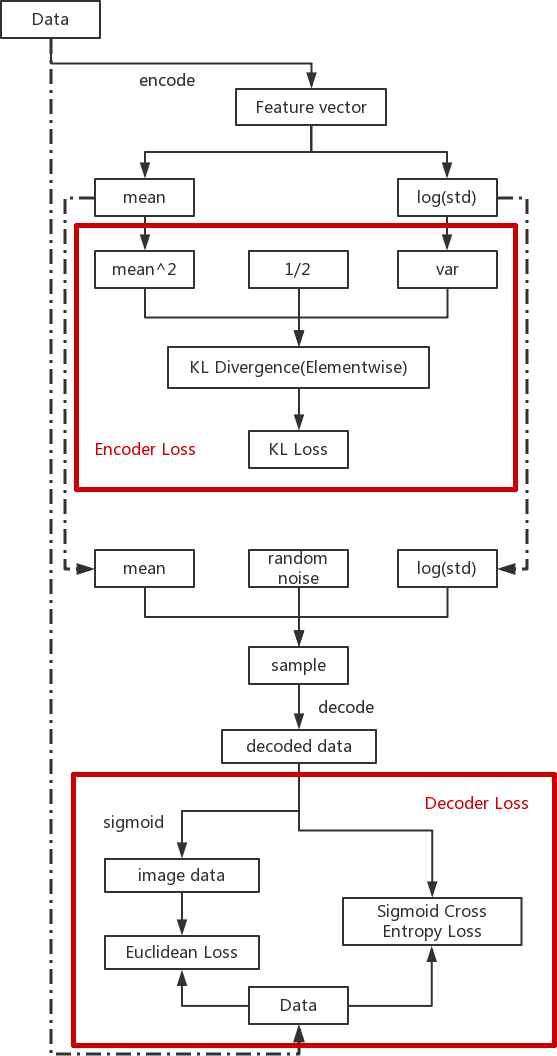
图中粗框表示求解Loss的部分。虚线展现了两个模块之间数据共享的情况。可以看出图的上半部分是优化Encoder的部分,下面是优化Decoder的部分,除了Encoder和Decoder,图中还有三个主要部分。
- Encoder的Loss计算:KL散度。
- z的重采样生成。
- Decoder的Loss计算:最大似然。
这其中最复杂的就是第一项,Encoder的Loss计算。由于Caffe在实际计算过程中只能采用向量的计算方式,没有广播计算的机制,所以前面的公式需要进行一定的变换:
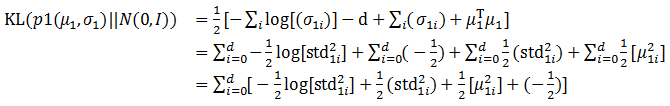
在完成了前面的向量级别计算后,最后一步就是完成汇总加和的过程。这样Loss计算就顺利完成了。
经过上面对VAE理论和实验的介绍,相信读者对VAE模型有了更清晰的认识。经过训练后VAE的解码器在MNIST数据库上生成的字符如图10-2所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









