






前传
推荐系统的框架大都是这个模式:多种召回策略,一种融合排序策略。召回策略姿势繁多,此处按下不表,单说最终的融合排序,最常见的就是CTR预估。这里说的CTR预估的C,可以是广义上的点击,包括我们视为关键动作的任何用户行为,如收藏、购买等。
CTR预估的常见做法就是广义线性模型,如Logistic Regression,外加特征海洋战术,这样做好处多多:
- 线性模型简单,其训练和预测计算复杂度都相对低;
- 工程师的精力可以集中在发掘新的有效特征上,俗称特征工程;
- 工程师们可以并行化工作,各自挖掘特征;
- 线性模型的可解释性相对非线性模型要好。
特征海洋战术让线性模型表现为一个很宽广(Wide)的模型。线性的宽模型要产生非线性效果,主要靠特征组合,尤其是二阶交叉,但如果交叉后的特征没有覆盖样本,那么交叉就然并卵。
近年来,深度学习异军突起,摧城拔寨,战火自然也烧到了推荐系统领域了,用深度神经网络来革“线性模型+特征工程”的命也再自然不过。用这种“精深模型”升级以前的“广博模型”,尤其是深度学习“端到端”的诱惑,让算法工程师们纷纷主动投怀送抱[1]。
深度学习在推荐领域的应用,其最大好处就是“洞悉本质般的精深”:优秀的泛化性能,可以给推荐很多惊喜。当然对应的问题就是容易过度泛化,会推荐得看上去像是“找不着北”,就是你们的PM和老板常问的那句话:“不知道怎么推出来的”,可解释性差一点。
既然深度模型有这么大的好处,广度模型也有诸多好处,根据人类的贪婪属性,下一秒就有人问“能都要吗?”,这时候Google站出来冷冷地说:当然。
Google公司去年提出一个新的推荐系统框架级别的解决方案,结合了传统的线性模型和当前火热的深度模型,应用在GooglePlay上的APP推荐,推荐效果提高非常明显[2]。
下面就为大家介绍一下这个方案的关键要素。
整体框架
一个典型的推荐系统架构很类似一个搜索引擎。也是由检索(或称召回)和排序两部构成(图1),这在我们前面的搜索、推荐、广告三者架构能统一吗已经讨论过[3]。不过推荐系统的检索过程并不一定有显式的query,而通常是用户特征和场景特征。
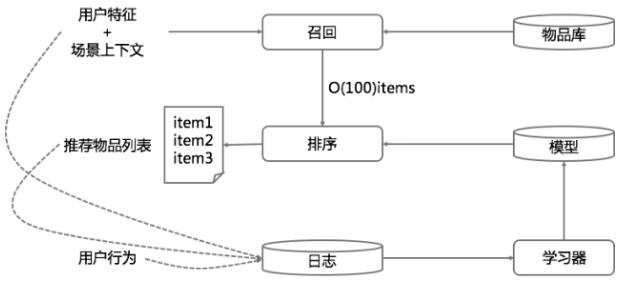
推荐系统的“query”,最重要的当然就是用户特征,哪些可以做用户特征?并不只是标签和注册资料,可以说“六经注我”,凡是可以“注我”的皆为特征:显式的有标签,注册资料,喜欢过的物品,消费过的物品,在一些维度上的统计值,隐式的有一些话题模型,embedding(如word2vec)等等,并不只是人类可读的那些维度(PS:用户标签被一些擅长忽悠的公司和大众媒体换了个迷惑人的词语,叫做“用户画像”,通常还煞有介事的画成一个“人形”,真担心被有关部门解读为“标签成精”)
本文是关于广度和深度模型的结合,解决的是架构中的“学习”“模型”“排序”这三个地方的问题,所以上面这一段可以不读,当然现在说有点晚了(逃)。
深宽的模型
现在来看看今天的主角:我们把它叫做“深宽模型”(Wide & Deep Model)。
首先,线性模型部分,也就是“宽模型”(图2左边),形式如下:
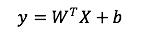
其中:
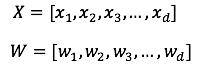
X是特征向量,W是模型参数向量,这个b是线性模型固有的偏见,哦不,偏置。线性模型中常用的特征构造手段就是特征交叉。例如:性别=女 and 语言=英语。就是由两个特征组合交叉而成,只有当“性别=女”取值为1,并且“语言=英语”也取值为1时,这个交叉特征才会取值为1。线性模型的输出这里采用的Logistic Regression。
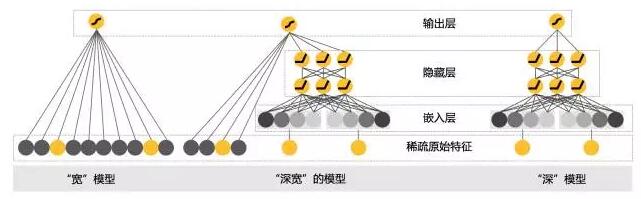
然后,看看深度模型(图2右边)。深度模型其实就是一个前馈神经网络(Feedforward Neural Network)。深度模型对原始的高维稀疏类别型特征,先进行embedding,转换为稠密、低维的实值型向量,转换后的向量维度通常在10-100这个范围。至于怎么embedding,就是随机初始化embedding向量,然后直接扔到整个前馈网络中,用目标函数来优化。
前馈网络中每一个隐藏层激活方式如下:
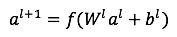
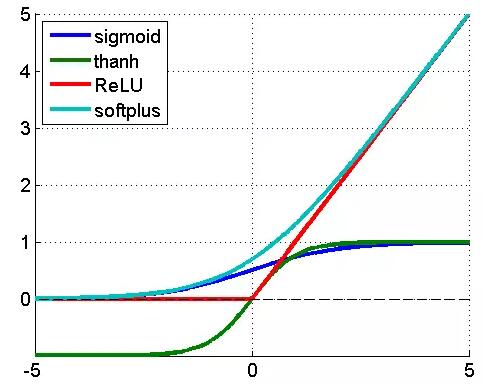
其中l表示第l个隐藏层,f是激活函数,通常选用ReLU(整流线性单元),为什么选用ReLU而不是LR,这个原因主要是LR在误差反向传播时梯度容易饱和(着急上车,来不及解释了,具体请参考任何一本深度学习教材)。ReLU及其他常用激活函数的形状见图3:
最后,看看两者的融合,示意图见图2的中间部分。深模型和宽模型,由一个logistic regression模型作为最终输出单元。训练方法采用Joint Learning,这是什么?就是通常说的端到端(end-to-end),把深模型和宽模型以及最终融合的权重放在一个训练流程中,直接对目标函数负责,不存在分阶段训练。它与ensemble方法有区别,ensemble是集成学习,子模型是独立训练的,只在融合阶段才会学习权重。
为了对比试验,Google分别用JointLearning训练“深宽模型”(Wide&Deep),FTRL+L1训练“宽模型”(LR)[4],AdaGrad训练“深模型”(Feedforward Neural Network)。
融合结果以LR模型作为输出:
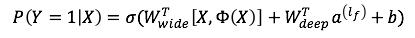
Y是我们要预估的行为,二值变量,如购买,或点击,Google原文是预估是否安装APP。σ是sigmoid函数,W_wide^T是宽模型的权重,Φ(X)是宽模型的组合特征,W_deep^T是应用在深模型输出上的权重,a^((l_f ) )是深模型的最后一层输出,b是线性模型的偏见,哦不,偏置。
整个深模型和宽模型的融合在图3的中间部分很好的展示了。
系统实现
整个数据流如图4所示。
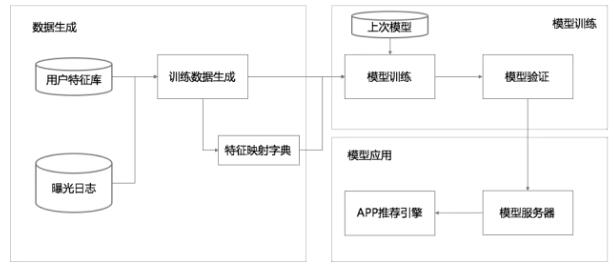
整个流程分为三大块:数据生成,模型训练,模型应用。
数据生成
数据生成有几个要点:
- 每一条曝光日志就生成一条样本,标签就是1/0,安装了APP就是1,否则就是0。
- 将字符串形式的特征映射为ID,需要用一个阈值过滤掉那些出现样本较少的特征。
- 对连续值做归一化,归一化的方法是:对累积分布函数P(X<=x)划分nq个分位,落入第i个分位的特征都归一化为
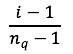
模型训练
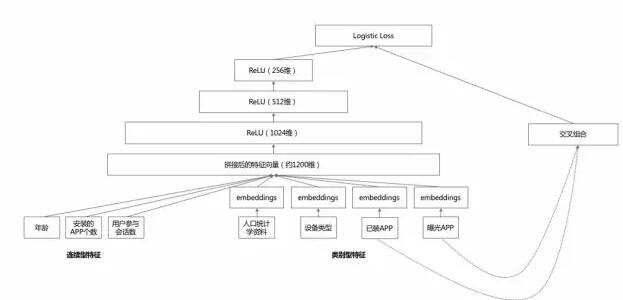
整个模型的示意如图5所示。其要点,在深度模型侧:
- 每个类别特征embedding成一个32维向量;
- 将所有类别特征的embedding变量连成一个1200维度左右的大向量;
- 1200维度向量就送进三层以ReLU作为激活函数的隐藏层;
- 最终从Logistic Regreesion输出。
宽模型侧就是传统的做法:特征交叉组合。
当新的样本集合到来时,先是用上一次的模型来初始化模型参数,然后在此基础上进行训练。
新模型上线前,会先跑一遍,看看会不会出事,算是一个冒烟测试。
列位看官,是不是觉得说起来容易,动手难?没关系,Google已经开源这一套算法了,集成在TensorFlow中[5]。
模型应用
模型验证后,就发布到模型服务器。模型服务,每次网络请求输入的是来自召回模块的APP候选列表以及用户特征,再对输入的每个APP进行评分。评分就是用我们的“深宽模型”进行前馈计算,再按照计算的CTR从高到低排序。
为了让每次请求响应时间在10ms量级,每次并不是串行地对每个候选APP计算,而是多线程并行,将候选APP分成若干并行批量计算。
正因为有这些小的优化点,GooglePlay的APP推荐服务,在峰值时每秒计算千万级的APP。
要点总结
整个模型在线上效果还是不错的(GooglePlay的APP推荐效果,以用户安装为目标)。

线上效果直接相对于对照组(纯线性模型+人工特征)有3.9%的提升,但是线下的AUC值提高并不明显,反过来说,AUC值是不是最佳的线下评估方式,也是值得我们思考的,毕竟我们的模型还是要看线上的最终效果。
Google将传统的“宽模型”和新的“深模型”结合,是一种工程上的创新。这里简单画一下全文重点:
- 深宽模型是一个结合了传统线性模型和深度模型的工程创新;
- 这个模型适合高维稀疏特征的推荐场景,稀疏特征的可解释性加上深度模型的泛化性能,双剑合璧;
- Google已经将其开源在TensorFlow中,感兴趣的可自行取用;
- 已经在GooglePlay的APP推荐中得到了成功应用。
其中有若干经验可以供我们在实践中参考:
- 采用Joint Learning训练融合模型,深度学习End-to-End的优点要持续发挥。
- 为了提高模型的训练效率,每一次并不从头开始训练,而是用上一次模型参数来初始化当前模型的参数。
- 将类别型特征都先做embedding再送入深度模型中。
- 为了提高服务的响应效率,对每次请求要计算的多个候选APP采用并行评分计算的方式,大大降低响应时间。
嗯,Wide&Deep Model就是这样一个既博学又精深的Model,意不意外,惊不惊喜?所以,算法工程师们,可以考虑在自己的个性化推荐产品中试试这个Model,别老盯着维秘Model。
参考文献
[1] “人工特征工程+线性模型”的尽头
http://weibo.com/1953709481/zp2pcihSN?type=comment#_rnd1499686397997
[2] wide & deep learning for recommender systems
https://arxiv.org/abs/1606.07792
[3] 搜索、推荐和广告架构能统一吗?https://zhuanlan.zhihu.com/p/22560037
[4] Ad Click Prediction: a View from the Trenches
https://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
[5] TensorFlow Wide & Deep Learning Tutorial
https://www.tensorflow.org/tutorials/wide_and_deep
作者简介:陈开江@刑无刀,希为科技CTO,曾任新浪微博资深算法工程师,考拉FM算法主管,个性化导购App《Wave》和《边逛边聊》联合创始人,多年推荐系统从业经历,在算法、架构、产品方面均有丰富的实践经验。
相关阅读:
TensorFlow Wide And Deep 模型详解与应用
【CSDN在线公开课】图像算法大多都以提高精度为目标,那么如何在现有模型基础上提高精度呢?现在的CNN网络,已经优化得不能再优化了,我们还能继续提高基础的CNN网络准确度吗?为此,CSDN学院邀请到菱歌科技首席算法科学家吴岸城,他将分享的主题为「深度学习中基础模型性能的思考和优化」。点击下图立即报名

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









