






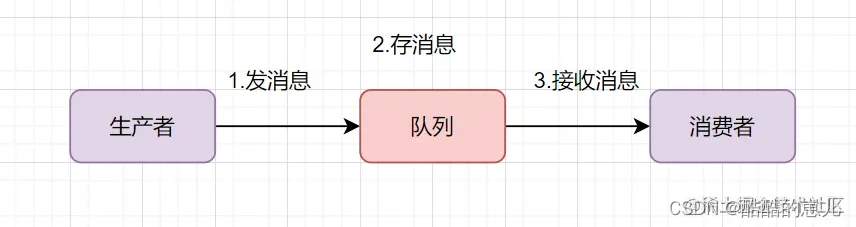
1、什么是消息队列,什么是Kafka?
我们通常说的消息队列,简称MQ(Message Queue),它其实就指消息中间件,比较流行的开源消息中间件有:Kafka、RabbitMQ、RocketMQ等。今天我们要介绍的就是其中的Kafka。
2、为什么要用Kafka?
小剧场:假如你正在上班,快递员给你打电话取快递,正常情况下,你要去找快递员拿快递,快递员需要等着你来拿,如果很多快递员同时给你打call,叫你去不同的地方拿快递,而且你还没有下班,怎么解决这种情况呢?
我们可以修一个快递站(消息队列),快递员只需要把快递都放在快递站不就行了,这样你就去快递站拿就ok了,万一哪天你生病了,快递员也能把快递送出去(解耦),你也不需要去那么多地方拿了(流量削峰),直接去快递站就行了,快递员不再需要等你(异步),可以继续去送下一单了,美滋滋。
以上就是为什么要用Kafka的原因,也是为什么用消息队列的原因。
(1)解耦(2)流量削峰(3)异步处理
3、Kafka中的一些基本概念
Producer:生产者,也就是发送消息的一方。生产者负责创建消息,然后将其投递到 Kafka 中。
Consumer:消费者,也就是接收消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理。
Broker:服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个 Broker 组成了一个 Kafka 集群。一般而言, 我们更习惯使用首字母小写的 broker 来表示服务代理节点。
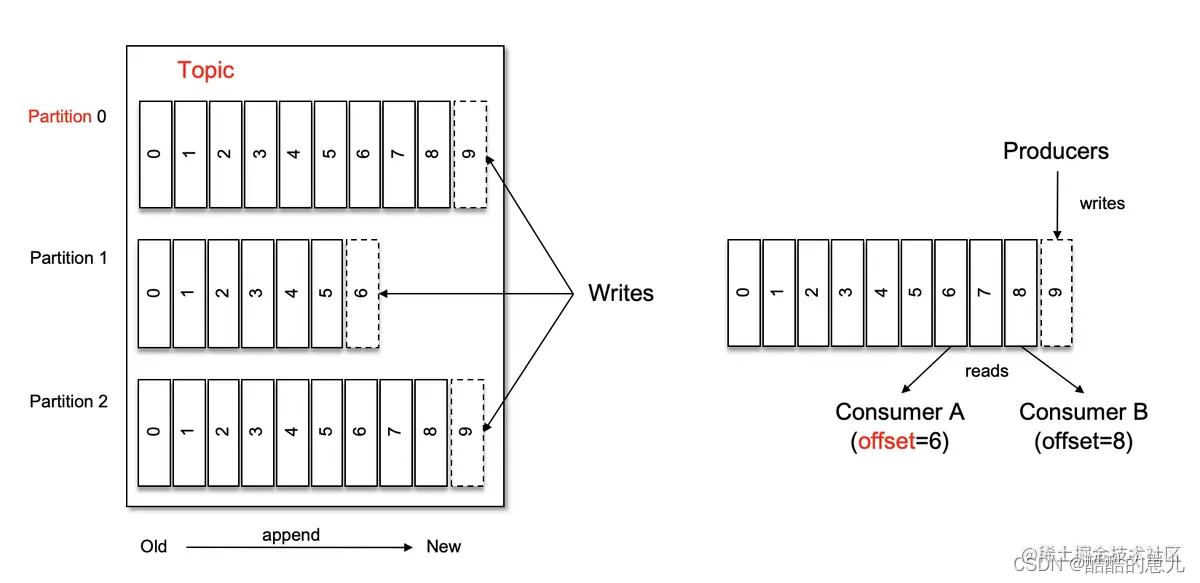
主题(Topic)与分区(Partition)。Kafka 中的消息以 topic 题为单位进行归类,生产者负责将消息发送到特定的 topic (发送到 Kafka 集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
主题是逻辑上的概念,一个主题可能存放在很多台服务器之上,一个主题包含多个分区。分区在存储层面可以看作一个追加的日志文件,Kafka通过offset来保证消息在分区内的顺序性,已经提交的日志无法被修改,结构如右上的图所示。Kafka保证的是分区的有序而不是主题的有序。
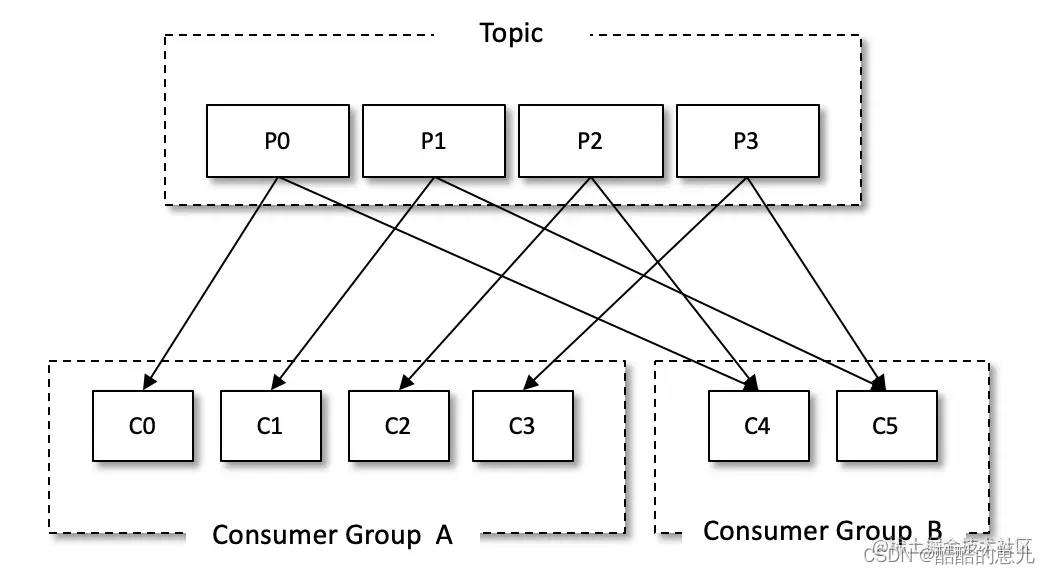
消费组。每个消费者都有一个对应的消费组,消费组由许多消费者组成。当消息发送到主题之后,会发送给已订阅的消费组中的一个消费者。
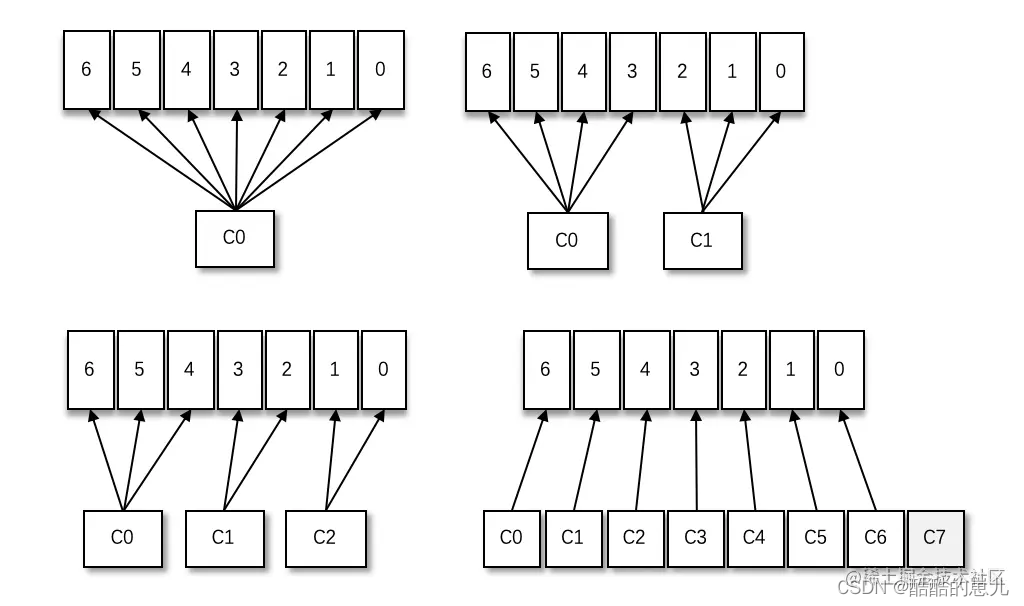
当消费组内消费者增多的时候,会将之前消费者所负责的分区分配给新增的消费者身上来,所以适当增加消费者的数量可以提高整体的消费能力(横向伸缩性),但是当消费者的数量大于分区数的时候,就会出现上图右下角的现象,C7消费者没有分到任何的分区,这就造成了资源的浪费。

也可以改变消费者分区分配策略,如上图实现组内广播。
基本概念总结:生产者、消费者、broker、Kafka集群、topic、partition、消费组。
4、Kafka多副本机制
每个分区可能会有多个副本,增加副本数量可以提升容灾机制,不同的副本存储在不同的broker中,副本之间是一主多从关系,其中leader副本负责读写请求,follower副本负责与leader副本进行同步。下面介绍三个概念:
(1)AR (Assigned Replicas):分区所有的副本
(2)ISR (In-Sync Replicas):所有与 leader 副本保持一定程度同步的副本(包括 leader 副本)
(3)OSR (Out-of-Sync Replicas):与 leader 副本同步滞后过多的副本
AR = ISR + OSR
ISR还与HW和LEO有关
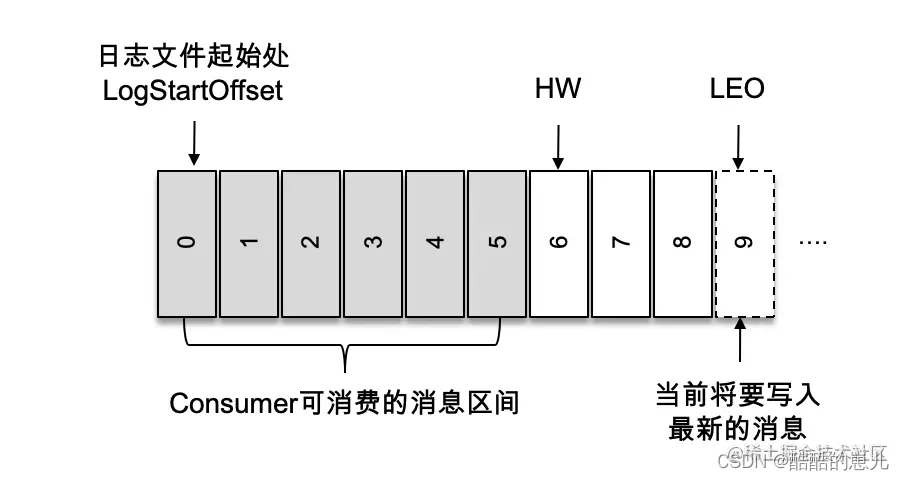
HW(High WaterMark):高水位,标志了一个特殊的offset,消费者只能获取到这个之前的消息。
LEO(Log End Offset):当前日志下下一条待写的offset
下图中HW为6 消费者只能获取到0-5的消息,队尾的offset为8。
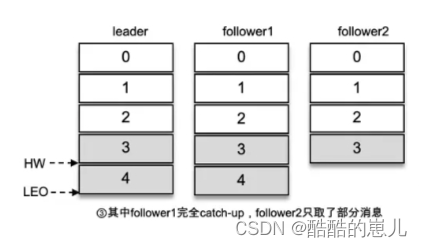
如下图所示,如果follower1已经和leader同步了,但follower2还没有同步,此时HW要选择小的,也就是3,LEO为4。
5、Kafka应用实战
(1)为什么分区数只能增加不能减少?
考虑几个方面,减少分区的流程和代价,减少分区的效益。
实现此功能需要考虑的因素很多,比如删除的分区中的消息该如何处理? 如果随着分区一起消失则消息的可靠性得不到保障;如果需要保留则又需要考虑如何保留。直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于 Spark、Flink 这类需要消息时间戳(事件时间)的组件将会受到影响; 如果分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、 事务性问题,以及分区和副本的状态机切换问题都是不得不面对的。
所以要去减少分区还不如重新创建一个分区数小的主题。
(2)为什么消费者端不采用推送的形式?
生产者将消息推送到中间件,中间件为什么不推送给消费者,而是让消费者自己pull?
因为一下子都推送给消费者,消费者可能处理不过来,就像秒杀系统一样。所以让消费者自己去pull,能处理多少就pull多少。
那这样不会造成消息积压吗?
一般像秒杀系统都是短暂的,不会长期处于这种状态,可以等到恢复正常的时候再慢慢处理这些积压。
那万一因为bug导致消息积压了太久怎么办呢?
可以采用临时扩容的方案来处理:
- 先修复consumer消费者的问题,以确保其恢复消费速度,然后将现有consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先10倍的queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
(3)分区数怎么设定?

partition 表示 topic 的分区号,如果在消息(ProducerRecord)中指定了这个属性,就会将这条发送到topic 的指定分区。如果消息中未指定 key,那么会以轮训的方式分发。如果指定了 key,那么会对 key进行哈希(MurmurHash2 算法)来计算分区号。
基于key的分区计算要多加注意,如果多数消息算出来的key都是一样的,就会有大量任务被分配到同一个分区,可能会造成消息积压。
分区数不是越多越好,如果分区数一昧的增多的话,会让Kafka的启动和关闭的耗时加长,如果一个broker节点宕机,其上的leader节点的所有副本都变的不可用,需要重新选出新的leader节点,并将所有的副本leader节点都修改为新的leader节点,耗时增加。
(4)如何保证消息的幂等性?
幂等处理重复消息,简单来说,就是搞个本地表,利用主键或者唯一性索引,每次处理业务,先校验一下就好啦。或者设置版本号,发送的时候截获消息插入版本号,获取的时候截获消息查看版本号,来保证不重复处理,又或者用redis缓存下业务标记,每次看下是否处理过了。
(5)Kafka批量处理提高性能
而Kafka 采用了批量处理:生产者聚合了一批消息,然后再做 2 次 rpc 将消息存入 broker,这原本是需要很多次的 rpc 才能完成的操作。假设需要发送 1000 条消息,每条消息大小 1KB,那么传统的消息中间件需要 2000 次 rpc,而 Kafka 可能会把这 1000 条消息包装成 1 个 1MB 的消息,采用 2 次 rpc 就完成了任务。
参考文章链接:
下篇文章介绍一下Git的原理。














 2169
2169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









