







数据集介绍

from sklearn import datasets
diabetes = datasets.load_diabetes()
pd.DataFrame(diabetes.target).head()

pd.DataFrame(diabetes.data).head()
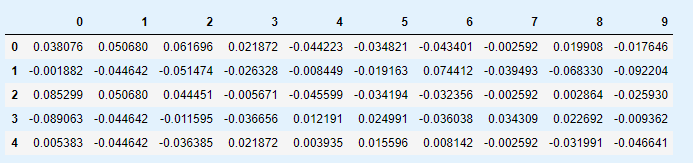
diabetes.feature_names

print(diabetes.DESCR)

数据调整

0 载入库&加载数据
import numpy as np
import pandas as pd
from sklearn.linear_model import Lasso, Ridge, ElasticNet
#导入数据
df = pd.read_csv('Regression/Regression8/diabetes.csv')
features = list(df.columns)
features.remove('y')
labels = ['y']
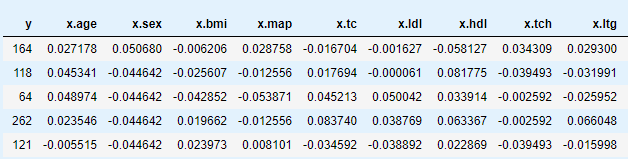
df.sample(n=5)
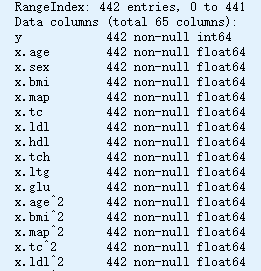
df.info()
1 用lasso求解
lamb = 0.5 #参数
lasso_reg = Lasso(alpha=lamb)
#对10个原始自变量做回归
lasso_reg.fit(df[features[1:11]], df[labels])
print('截距\n', lasso_reg.intercept_)
print('自变量系数\n', lasso_reg.coef_)

- 仅4个变量
不为0 - 稀疏性非常强
- 变量筛选效果好
2 岭回归
lamb = 0.1 #参数
Ridge_reg = Ridge(alpha=lamb)
Ridge_reg.fit(df[features[1:11]], df[labels])
print('截距\n', Ridge_reg.intercept_)
print('自变量系数\n', Ridge_reg.coef_)

- 全部为
非0项 - 只具有压缩功能
- 不具有变量选择功能
3 引入全部特征
lamb = 0.1
lasso_reg2 = Lasso(alpha=lamb)
lasso_reg2.fit(df[features], df[labels])
print('截距\n', lasso_reg2.intercept_)
print('自变量系数\n', lasso_reg2.coef_)

非0元个数210元个数43- 大部分变量系数为0
- 一次项
非0元较多 - 二次项
非0元较少
4 弹性网络方法
lamb=0.1
ElasticNet_reg = ElasticNet(alpha=lamb, l1_ratio=0.95)
ElasticNet_reg.fit(df[features], df[labels])
print('截距\n', ElasticNet_reg.intercept_)
print('自变量系数\n', ElasticNet_reg.coef_.T)

非0元个数380元个数26非0元素个数较为折中
5 超参数选择

from sklearn.linear_model import LassoCV,RidgeCV,ElasticNetCV
lasso_reg = LassoCV(cv=20).fit(df[features], df[labels])
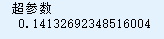
print('超参数\n', lasso_reg.alpha_)
















 2282
2282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









