










记录一些好的用法:
1.pytorch权重初始化代码,该代码放入nn.Module的初始化网络里。
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
2.生成带层名的网络的便捷方法
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3,
stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入darknet模块,res_unit
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
3.GPU tensor与CPUtensor之间的转换:
CPU张量 ----> GPU张量, 使用data.cuda()
GPU张量 ----> CPU张量 使用data.cpu()
4.将参数放入字典,由类内字典直接加载:
“将参数写在类内,由字典进行加载,方便参数修改”
_defaults = {
"sets": {0.5, 1, 1.5, 2},
"units": [3, 7, 3],
"chnl_sets": {0.5: [24, 48, 96, 192, 1024],
1: [24, 116, 232, 464, 1024],
1.5: [24, 176, 352, 704, 1024],
2: [24, 244, 488, 976, 2048]}
}
def __init__(self, scale, num_cls):
super(ShuffleNet_v2, self).__init__()
self.__dict__.update(self._defaults)
5.torch.tensor更改维度后保持连续性:
.permute(0, 1, 3, 4, 2).contiguous()
6.len(tensor)实际上取的是tensor的dim0的维度;如果dim0刚好为batchsize,可以用for循环遍历每个batchsize的具体内容。
7.两tensor,如a:size(1,2,4)及b:size(3,2,4),经过cat((a,b),0)后只有被cat的维度size改变为两者相加值,为:size(4,2,4)
8.torch.max的用法,,指定dim后,返回指定dim的最大值。同时返回的还有最大值所在dim的下标序号。keepdim=False,默认输出结果降低一个维度,如果True,则输出结果 不降维,只是将其余非max值从返回结果中去除掉。
(max, max_indices) = torch.max(input, dim, keepdim=False)
import torch
a = torch.tensor([[1, 5, 62, 54], [2, 6, 2, 6], [2, 65, 2, 6]])
print(a.shape)
print(‘a:’, a,
‘\n\ntorch.max(a):’, torch.max(a,dim=1),
‘\n\ntorch.max(a, 0):’, torch.max(a, dim=0)
)
输出值为:
a: tensor([[ 1, 5, 62, 54],
[ 2, 6, 2, 6],
[ 2, 65, 2, 6]])
torch.max(a): torch.return_types.max(
values=tensor([62, 6, 65]),
indices=tensor([2, 1, 1]))
torch.max(a, 0): torch.return_types.max(
values=tensor([ 2, 65, 62, 54]),
indices=tensor([1, 2, 0, 0]))
当原始数组为3维时,对原始数组使用torch.max,并指定dim=0时,则后两维数组为2维tensor,为
2维tensor的逐元素大小比较。
size(2,3,1),不keepdim时:
dim=0,返回size(3,1)
dim=1,返回size(2,1)
dim=2,返回size(2,3)
keepdim时:
空缺维度补1:
dim=0,返回size(1,3,1)
dim=1,返回size(2,1,1)
dim=2,返回size(2,3,1)
注:dim=1,相当于对(1)找最大值,然后0维个最大值相拼。这种情况很少见。
9.tensor直接比较返回mask:
k=torch.FloatTensor([x for x in range(12)]).reshape(3,2,2)
# #测试:
m=(k>10)
print(m)
输出结果:
tensor([[[False, False],
[False, False]],
[[False, False],
[False, False]],
[[False, False],
[False, True]]])
接着可以将mask对原始数组k使用,返回筛选结果:
print(k[m])
返回的是一维数组:
tensor([11.])
注意,使用mask操作会破坏最外围结构,如果最外层是batchsize,应先用for循环脱去最外维,对里面剩下的维度进行处理,保留处理结果与batchsize之间的关系。
10.
使用unique能产生集合,对类别置信度进行去重
x = torch.tensor([4,0,1,2,1,2,3])
print(x)
out = torch.unique(x) 返回结果默认升序排序
print(out)#将处理结果打印出来
#结果如下:
#tensor([0, 1, 2, 3, 4])
out = torch.unique(x,return_counts=True) #返回每个独立元素的个数
print(out)
#输出结果如下
#(tensor([0, 1, 2, 3, 4]), tensor([1, 2, 2, 1, 1]))
11.unsqueeze函数:快速在指定维度增加1维
k=torch.FloatTensor([x for x in range(12)]).reshape(3,2,2)
print(k.shape)
k=k.unsqueeze(1)
print(k.shape)
输出:
torch.Size([3, 2, 2])
torch.Size([3, 1, 2, 2])
12.torchvision自带nms:
import torch
a=torch.Tensor([[1,1,2,2],[1,1,3.100001,3],[1,1,3.1,3]])
b=torch.Tensor([0.9,0.98,0.980005])
from torchvision.ops import nms
#3个参数为box数组,格式[[x1,y1,x2,y2]],得分tensor[],及阈值,大于该阈值会被舍弃
ccc=nms(a,b,0.4)
print(ccc)
print(a[ccc])
输出结果为:
tensor([2, 0])
tensor([[1.0000, 1.0000, 3.1000, 3.0000],
[1.0000, 1.0000, 2.0000, 2.0000]])
需要注意的是tensor索引:
a的size为(3,4)
a[0,2]为第一维取0,第二维取第3个元素,自动从左向右进行索引,结果为[2].
a[[0,2]]为取第0维中的第0和第3个元素,为:tensor([[1.0000, 1.0000, 2.0000, 2.0000],[1.0000, 1.0000, 3.1000, 3.0000]])
注意用:输出降维的情况:
a=torch.Tensor([[1,1,2,2],[1,1,3.100001,3],[1,1,3.1,3]])
print(a[:,2])
输出:(第一维全要,每个第二维只取一个元素,然后堆叠在一起,输出一个1维序列)
tensor([2.0000, 3.1000, 3.1000])
如果第二维取两个元素:某种程度上相当于特殊的:,输出维度不变
print(a[:,[2,3]])
输出:
tensor([[2.0000, 2.0000],
[3.1000, 3.0000],
[3.1000, 3.0000]])
13.不规则间隔索引
比如取0维的第0个和第1个元素:
a=torch.rand(10,3,24,24)
a.index_select(0,torch.tensor([0,2])).shape
输出结果:
torch.Size([2, 3, 24, 24])
14.除法的意义:
a
b
\frac{a}{b}
ba
除法的基本意义是被除数被均分,是以b表示a,b作为单位。
有图片1,其size(a1,a1);经缩放后产生图片2,size(b1,b1)
当图片1以图片2为基准时,设有比例因子scale=a1/b1;该比例用法为,已知图1某长度比例求图2中相同的比例,其实是先乘a1得到实际长度,再除以b1,即乘以该比例因子。
15.用多维tensor做tensor的索引的理解及其输出维度:
a[[0, 1], …] 等价 a[0] 和 a[1],相当于索引张量的第一行和第二行元素
Tensor = torch.FloatTensor(range(24)).view(3,2,4)
a = Tensor[1]
print(a.shape)
a = Tensor[[1]]
print(a.shape)
输出:
torch.Size([2, 4])
torch.Size([1, 2, 4])
a = Tensor[[1]]意义为,第一个维度取1,再组合,故保持3维不变。
扩展有:
Tensor = torch.FloatTensor(range(24)).view(3,2,4)
a = Tensor[[[1],[1]]]
print(a.shape)
a = Tensor[1,1]
print(a.shape)
输出为:
torch.Size([1, 4])
torch.Size([4])
a = Tensor[[[1],[1]]]意义为,第一维取1,第二维取1,再组合,故为torch.Size([1, 4])
16.张量的自动求导特性:
梯度(gradient)是一个向量(矢量,有方向),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。损失函数沿梯度相反方向收敛最快(既能最快找到极值点)。
梯度下降法在于求解梯度,并依次迭代地让输入x沿梯度的反方向进行移动,当梯度为0时,标志函数取到了一个极值点。
tenor的自动求导属性:
grad:该Tensor对应的梯度,类型为Tensor,并与Tensor同维度。
grad_fn:指向function对象,即该Tensor经过了什么样的操作,用作反向传播的梯度计算,如果该Tensor由用户自己创建,则该grad_fn为None。
通过requires_grad_使tensor变为需要求导的对象。
17.tensor的上下值截取操作:
a=torch.randint(low=0,high=10,size=(10,1))
print(a)
a=torch.clamp(a,3,9)
print(a)
最终结果的各分量值介于3及9之间。
18.梯度累加,每次梯度下降后不立刻将累计梯度值清0,而是做累加,可以在有限内存的情况下,变相扩大批大小,相关代码如下:
for i,(image, label) in enumerate(train_loader):
pred = model(image)
loss = criterion(pred, label)
#使损失值相应减小
loss = loss / accumulation_steps
loss.backward()
if (i+1) % accumulation_steps == 0:
# optimizer the net
optimizer.step() # update parameters of net
optimizer.zero_grad() # reset gradient
原理公式为:
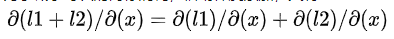
19.用切片的方法保留维度:虽然同样第二维只取一个元素,但是保留了原始维度
k=torch.rand(3,10)
print(k[:,0])
print(k[:,0:1])
输出结果为:
tensor([0.8416, 0.6899, 0.4022])
tensor([[0.8416],
[0.6899],
[0.4022]])
20.重复tensor中的某些维度:
对齐方式是原始tensor和repeat中的元素右对其,原始tensor不够长时,原始tensor最左侧补1,再repeat。
k=torch.FloatTensor([x for x in range(6)]).view(2,3)
print(k)
print(k.repeat(2,1).shape)
k=torch.FloatTensor([x for x in range(6)]).view(2,3)
print(k.repeat(2,1,1).shape)
print(k.repeat(2,1,1))
输出结果为:
tensor([[0., 1., 2.],
[3., 4., 5.]])
torch.Size([4, 3])
torch.Size([2, 2, 3])
tensor([[[0., 1., 2.],
[3., 4., 5.]],
[[0., 1., 2.],
[3., 4., 5.]]])
21.同形索引直接赋值:
k=torch.FloatTensor([x for x in range(12)]).view(2,3,2)
print(k>3)
k[k>3]=0
print(k)
输出结果:
tensor([[[False, False],
[False, False],
[ True, True]],
[[ True, True],
[ True, True],
[ True, True]]])
tensor([[[0., 1.],
[2., 3.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
22.求二值交叉熵函数的使用:
#默认为mean
print(nn.BCELoss()(k,b))
#不做操作时返回原矩阵
print(nn.BCELoss(reduction='none')(k,b))
输出:
tensor(0.8345)
tensor([[0.0166, 1.1610, 0.6610],
[1.4049, 1.7156, 0.0480]])
23.快速产生指定范围的整形tensor
target = torch.empty(2,3, dtype=torch.long).random_(5)
empty生成未初始化的tensor,.random_(5)将tensor中的每个元素限制在0到5,含0不含5

















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











