










端到端机器学习导航:
【机器学习】python借助pandas加载并显示csv数据文件,并绘制直方图
【机器学习】python使用matplotlib进行二维数据绘图并保存为png图片
【机器学习】python借助pandas及scikit-learn使用三种方法分割训练集及测试集
【机器学习】python借助pandas及matplotlib将输入数据可视化,并计算相关性
【机器学习】python机器学习借助scikit-learn进行数据预处理工作:缺失值填补,文本处理(一)
【机器学习】python机器学习scikit-learn和pandas进行Pipeline处理工作:归一化和标准化及自定义转换器(二)
【机器学习】python机器学习使用scikit-learn评估模型:基于普通抽样及分层抽样的k折交叉验证做模型选择
【机器学习】python机器学习使用scikit-learn对模型进行微调:使用GridSearchCV及RandomizedSearchCV
【机器学习】python机器学习使用scikit-learn对模型进行评估:使用t分布及z分布评估模型误差的95%置信空间
【机器学习】python机器学习使用scikit-learn对模型进行微调:RandomizedSearchCV的分布参数设置
【机器学习】python机器学习使用scikit-learn对模型进行微调:按特征贡献大小保留最重要k个特征的transform
【机器学习】python机器学习使用scikit-learn对模型进行微调:使用RandomizedSearchCV对pipline进行参数选择
数据准备:详见:【机器学习】python借助pandas及scikit-learn使用三种方法分割训练集及测试集
import os
HOUSING_PATH = os.path.join("datasets", "housing")
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing=load_housing_data()
import numpy as np
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
housing = strat_train_set.copy()
用图像找出数据之间的关系:
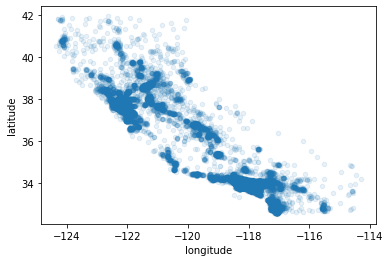
#直观查看任两个变量间的相关关系:其中增加的透明度属性可分辨数据分布的密集程度
housing.plot(kind="scatter", x="longitude", y="latitude",alpha=0.1)
print(type(housing))
import matplotlib.pyplot as plt
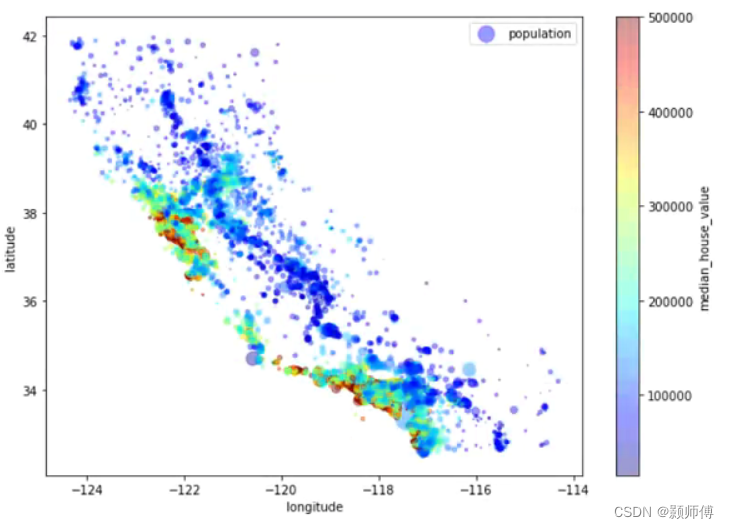
#每个圆的半径大小代表了每个区域的人口数量(选项s),颜色代表价格(选项c)。
#我们使用一个名叫jet的预定义颜色表(选项cmap)来进行可视化,颜色范围从蓝(低)到红(高)
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False)
plt.legend()
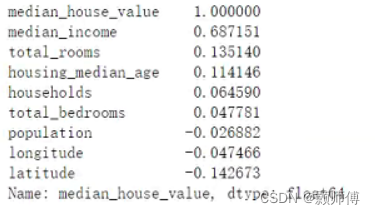
#输出线性相关度矩阵:
corr_matrix = housing.corr()
#找出房屋均价列与其他列的相关性(线性)并降序排序
corr_matrix["median_house_value"].sort_values(ascending=False)
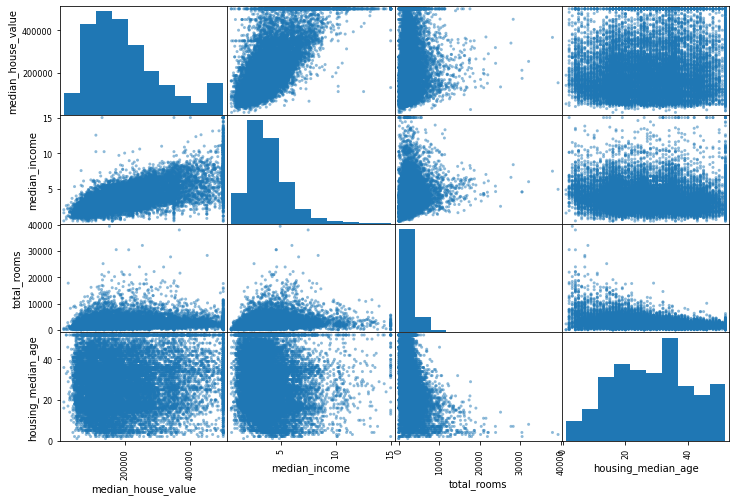
from pandas.plotting import scatter_matrix
#利用pandas一次性画出多图,变量两两间的相对关系
#如房价中位数与收入中位数间线性关系较强,有时为了拟合出较好的线性关系,也可以舍弃部分看起来非线性的数据点
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











