









端到端机器学习导航:
【机器学习】python借助pandas加载并显示csv数据文件,并绘制直方图
【机器学习】python使用matplotlib进行二维数据绘图并保存为png图片
【机器学习】python借助pandas及scikit-learn使用三种方法分割训练集及测试集
【机器学习】python借助pandas及matplotlib将输入数据可视化,并计算相关性
【机器学习】python机器学习借助scikit-learn进行数据预处理工作:缺失值填补,文本处理(一)
【机器学习】python机器学习scikit-learn和pandas进行Pipeline处理工作:归一化和标准化及自定义转换器(二)
【机器学习】python机器学习使用scikit-learn评估模型:基于普通抽样及分层抽样的k折交叉验证做模型选择
【机器学习】python机器学习使用scikit-learn对模型进行微调:使用GridSearchCV及RandomizedSearchCV
【机器学习】python机器学习使用scikit-learn对模型进行评估:使用t分布及z分布评估模型误差的95%置信空间
【机器学习】python机器学习使用scikit-learn对模型进行微调:RandomizedSearchCV的分布参数设置
【机器学习】python机器学习使用scikit-learn对模型进行微调:按特征贡献大小保留最重要k个特征的transform
【机器学习】python机器学习使用scikit-learn对模型进行微调:使用RandomizedSearchCV对pipline进行参数选择
一、数字预处理工作,分为处理数字缺失值及处理文本两部分
(1)面对数字缺失值,有如下三种方法处理:
1.放弃这些相应的区域。
housing.dropna(subset=["total_bedrooms"])
2.放弃整个属性。
median = housing["total_bedrooms"].median()
3.将缺失的值设置为某个值(0、平均数或者中位数等)。
housing["total_bedrooms"].fillna(median, inplace=True)
提示:pandas中的参数axis指定要遍历的是所有index还是遍历所有列做操作。
axis=0、axis=index,指的是遍历每个index、行号,即在纵向上遍历每列,所以做sum()、mean()等运算时,是对每列数据做操作,而drop(index, axis=0),传入的参数指定了某一行号,所以会在纵向上遍历每列,去掉行号对应位置的数据。
axis=1、axis=columns,指的是遍历每个columns、列名,即在横向上遍历每行,所以做sum()、mean()等运算时,是对每行数据做操作,而drop(col, axis=1),传入的参数指定了某一列名,所以会在横向上遍历每行,去掉列名对应位置的数据。
故:
#housing.isnull()逐一判断哪些值null,any(axis=1)判断哪些行存在nan
#any () 函数检查索引中的任何元素是否为true。
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows
得到了缺失值所在行,形成了新的pd
下面使用sklearn中的SimpleImputer函数,自动处理缺失值:
#去掉带文字的指定列
housing_num = housing.drop("ocean_proximity", axis=1)
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
imputer.fit(housing_num)
#此时转换为一个ndarray
X = imputer.transform(housing_num)
或者可用直接调用:
X=imputer.fit_transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
最后查看填补后的缺失值
housing_tr.loc[sample_incomplete_rows.index.values]
输出:

imputer函数参数详解:

二、处理文本和分类属性
主要是将用于分类的文本转化为数字:
housing_cat = housing[["ocean_proximity"]]
from sklearn.preprocessing import OneHotEncoder
#预处理模块拿到独热向量:
cat_encoder = OneHotEncoder()
#输出结果为稀疏矩阵
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
#也可使用housing_cat_1hot.toarray()转换为普通矩阵
#由此打印出最终类别
cat_encoder.categories_
输出结果:
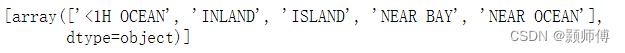

















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











