






本实验包含以下内容:
对提供的数据集——心脏病数据集——中的红色问号进行缺失值填充,最少选择两种缺失值填充方法,并根据另一张表中实际数据分析填充效果。
数据集下载:
代码如下:
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.impute import KNNImputer
import matplotlib.pyplot as plt
import pytab as pt
# from sklearn.preprocessing import Imputer # 高版本不存在 Impute,使用 SimpleImputer
data1 = pd.read_excel("实验4-心脏病数据.xlsx", header=None) # 读取csv文件,并存入data1,不带标签
data2 = pd.read_excel("实验4-心脏病数据 - 有缺失.xlsx", header=None) # 读取csv文件,并存入data2,不带标签
pd.set_option('expand_frame_repr', False) # 打印输出 dataframe 时不隐藏部分列
pd.set_option('display.max_rows', None) # 打印输出 dataframe 时不隐藏部分行
np.set_printoptions(threshold=float('inf')) # 输出不省略
np.set_printoptions(suppress=True, precision=3,linewidth=500) # 输出不用科学计数法,保留3位小数,500个字符再换行
# 修改列标签
name = ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach',
'exang', 'oldpeak', 'slope', 'ca', 'thal', 'target']
data1.columns = name # 修改列标签
data2.columns = name
# labels 删除的列标签,axis=1 删除列,inplace=True 改变原数据
data1.drop(labels=['ca', 'thal'], axis=1, inplace=True)
data2.drop(labels=['ca', 'thal'], axis=1, inplace=True)
data3 = data2.replace('?', np.NaN) # 将中文?替换为空值。
data1 = np.array(data1) # data1转为矩阵
data2 = np.array(data2) # data2转为矩阵
# 均值填充==========================================================
# missing_values缺失值是什么,strategy='mean'该列的缺失值由该列的均值填充
mean = SimpleImputer(missing_values=np.NaN, strategy='mean')
mean_data = mean.fit_transform(data3) # 填充data3
# knn填充(最近邻)==========================================================
# missing_values缺失值是什么,n_neighbors=1最近相近的1个数据的均值填充这里是1个类似热卡填充
knn = KNNImputer(missing_values=np.NaN, n_neighbors=1) # 邻居样本求平均数
knn_data = knn.fit_transform(data3) # 填充data3
c = 0
# 计算填充与原数值的相关系数===================================================
corr_mean = np.round(np.corrcoef(data1.T, mean_data.T), 4)
corr_knn = np.round(np.corrcoef(data1.T, knn_data.T), 4)
# 输出原数值和填充值
for i in range(len(data2)):
c = 0
for j in range(len(data2[0])):
if data2[i][j] == '?':
c = 1
if c:
print('实际数值:', data1[i])
print('均值填充:', mean_data[i])
print('热卡填充:', knn_data[i])
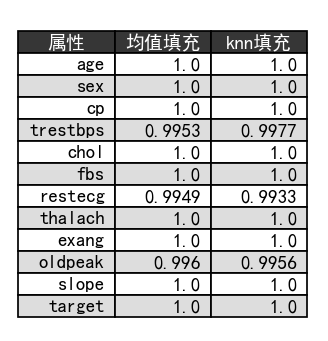
chart = {'属性': ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach',
'exang', 'oldpeak', 'slope', 'target'], '均值填充': [], 'knn填充': []} # 字典,用于绘制表格
for i in range(len(chart['属性'])):
chart['均值填充'].append(corr_mean[i][i + 12])
chart['knn填充'].append(corr_knn[i][i + 12])
# 下面这里用于正确显示中文,不要换位置
font = {'family': 'SimHei', # 黑体
'weight': 'bold', # 粗体
'size': '16'} # 大小 16
plt.rc('font', **font)
plt.rc('axes', unicode_minus=False)
# 绘制表格
pt.table(
data=chart,
th_type='dark',
table_type='striped'
)
pt.show()
结果示例:
C:\Users\86135\AppData\Local\Programs\Python\Python39\python.exe C:/Users/86135/PycharmProjects/pythonProject/1/003.py
实际数值: [ 57. 1. 4. 140. 192. 0. 0. 148. 0. 0.4 2. 0. ]
均值填充: [ 57. 1. 4. 131.673 192. 0. 0. 148. 0. 0.4 2. 0. ]
热卡填充: [ 57. 1. 4. 130. 192. 0. 0. 148. 0. 0.4 2. 0. ]
实际数值: [ 56. 0. 2. 140. 294. 0. 2. 153. 0. 1.3 2. 0. ]
均值填充: [ 56. 0. 2. 140. 294. 0. 0.987 153. 0. 1.3 2. 0. ]
热卡填充: [ 56. 0. 2. 140. 294. 0. 2. 153. 0. 1.3 2. 0. ]
实际数值: [ 64. 1. 1. 110. 211. 0. 2. 144. 1. 1.8 2. 0. ]
均值填充: [ 64. 1. 1. 131.673 211. 0. 2. 144. 1. 1.8 2. 0. ]
热卡填充: [ 64. 1. 1. 128. 211. 0. 2. 144. 1. 1.8 2. 0. ]
实际数值: [ 60. 1. 4. 130. 206. 0. 2. 132. 1. 2.4 2. 4. ]
均值填充: [ 60. 1. 4. 130. 206. 0. 2. 132. 1. 1.037 2. 4. ]
热卡填充: [ 60. 1. 4. 130. 206. 0. 2. 132. 1. 2. 2. 4.]
实际数值: [ 50. 0. 3. 120. 219. 0. 0. 158. 0. 1.6 2. 0. ]
均值填充: [ 50. 0. 3. 120. 219. 0. 0.987 158. 0. 1.037 2. 0. ]
热卡填充: [ 50. 0. 3. 120. 219. 0. 0. 158. 0. 0.2 2. 0. ]
实际数值: [ 57. 1. 4. 150. 276. 0. 2. 112. 1. 0.6 2. 1. ]
均值填充: [ 57. 1. 4. 131.673 276. 0. 2. 112. 1. 0.6 2. 1. ]
热卡填充: [ 57. 1. 4. 150. 276. 0. 2. 112. 1. 0.6 2. 1. ]
实际数值: [ 65. 0. 4. 150. 225. 0. 2. 114. 0. 1. 2. 4.]
均值填充: [ 65. 0. 4. 150. 225. 0. 0.987 114. 0. 1. 2. 4. ]
热卡填充: [ 65. 0. 4. 150. 225. 0. 0. 114. 0. 1. 2. 4.]
实际数值: [ 61. 0. 4. 130. 330. 0. 2. 169. 0. 0. 1. 1.]
均值填充: [ 61. 0. 4. 130. 330. 0. 2. 169. 0. 1.037 1. 1. ]
热卡填充: [ 61. 0. 4. 130. 330. 0. 2. 169. 0. 1.2 1. 1. ]















 5703
5703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









