







-------------------------------------------欢迎查看字符编码【专栏】------------------------------------------------------------------
汉字编码之GBK编码【点击】 判断汉字正则表达式更严谨方法【点击】
记事本输入“联通”俩字,关闭再打开乱码 【点击】 iPhone emoji问题牵出的Unicode代理区的思考【点击】
Unicdoe【真正的完整码表】对照表【点击】 开源工程ZipArchive,压缩中文文件名乱码问题【点击】
base64加密,解密,encode,decode,编码详解+实现【点击】
网络传输文本,urlEncode和urldecode的iOS实现【点击】 字符编码的奥秘utf-8, Unicode【点击】
--------------------------------------------------------------------------------------------------------------------------------------------------
一、通常做法
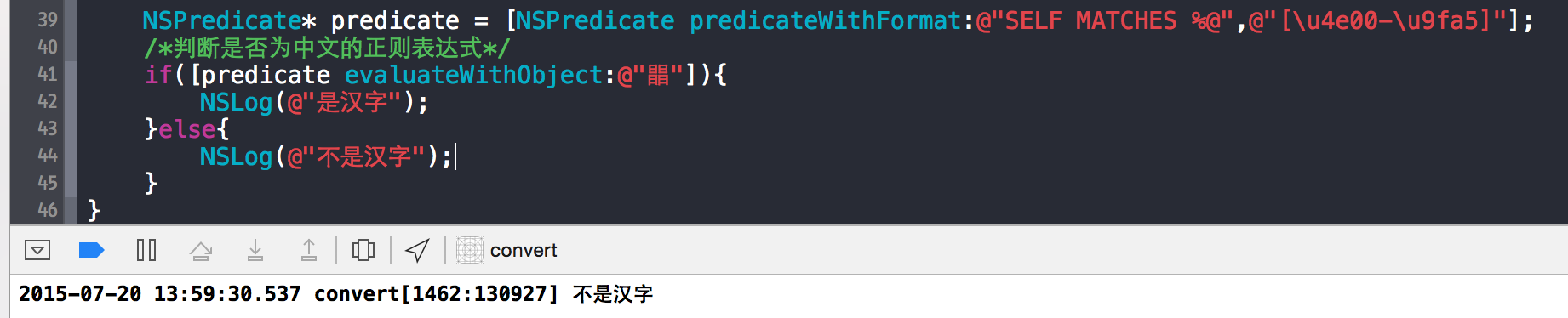
正如网上流传的,判断中文的正则表达式,绝大部分是这么写的(OC语言):
NSPredicate* predicate = [NSPredicate predicateWithFormat:@"SELF MATCHES %@",@"[\u4e00-\u9fa5]"];
/*判断是否为中文的正则表达式*/
if([predicate evaluateWithObject:name]){
//是中文
}else{
//不是中文
}然而上面的正则表达式,逻辑上讲并不严谨:比如一些生僻字的Unicode不在0x4e00-0x9FA5之间<点击查看Unicode总编码>,那么它不能正确识别出来:比如一些四叠字:
另外还有一些偏旁部首,有时候也会作为一个字出现。但是偏旁部首的Unicode同样不在0x4e00-0x9FA5之间,下面分别举例偏旁部首,叠字:
举几个例:

下载unicode和utf-8的转换工具,下载
如四个日的汉字,运行结果确“不是汉字”
二、原因
(假设你已经了解unicode的编码规则,和编码实现(utf-8);如果不了解, 查看 字符编码的奥秘utf-8, Unicode)中国71226个汉字,分别分布在Unicode第0个平面,常用27973个,第2个平面43253个。而[\u4e00-\u9fa5]只是代表了大约20901个汉字,剩余的汉字都在第2个平面(这部分可能是生僻字,很少使用)。
换句话说:流行的正则只能检测少部分汉字,却可以检测绝大部分常用汉字。
三、更严谨的做法
所以,在进行正则表达式的时候需要把第二平面的汉字囊括进去。
更严谨的正则表达式应该是这样的:
//注意这是伪代码,不能执行,很遗憾目前正则表达式不支持四个字节unicode的表示。
为什么是[\uDB40DC00-\uDB7FDFFF]:这里需要说名一下utf-16代理区:根据unicode的规则,第0平面是直接utf-8表示,第1到第16平面是通过代理区表示的。 查看这里由iPhone emoji问题牵出的UTF-16编码,UTF-8编码探究——了解utf-8编码和代理区的概念。

















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









