






搜索技术
人工智能求解领域的两大基本课题:知识表示、搜索技术。
人工智能解题程序的三个基本要素:一个综合数据库、一个智能算子、一个解释程序。
盲目搜索
- 指没有有用的知识作为指导的搜索。
- 通常对搜索空间中的状态进行穷举,容易导致组合爆炸。
1. 深度优先搜索(Depth-first Search, DFS)
搜索策略: 总是扩展深度大的结点,直到找到目标结点(问题的解)
算法描述:
1). 用N表示初始结点列表(N待扩展)
2). 如果N为空集,则退出并给出失败信号
3). n取为N的第一个节点,并在N中删除结点n,放入已访问结点列表
4). 如果n为目标结点,则退出并给出成功信号
5). 否则,将n的子结点作为表头(第一个结点)扩展到N中,返回2步
深度优先搜索的特点: 空间复杂度较BFS小,但未必能找到解,即使找到也未必是最优解。
2. 广度优先搜索(Breadth-first Search, BFS)
搜索策略: 总是在某一深度上先搜索所有的结点,之后搜索下一个深度的结点。
算法描述:
1). 用N表示初始结点列表(N待扩展)
2). 如果N为空集,则退出并给出失败信号
3). n取为N的第一个结点,并在N中删除结点n,放入已访问结点列表
4). 如果n为目标结点,则退出并给出成功信号
5). 否则,将n的子结点加到N的末尾,并返回2步
广度优先搜索的特点: 只要问题有解,就一定能在有限步数内找到解并且找到最优解。时间复杂度较DFS低。
广度优先搜索的缺点: 随着深度增加,节点数目呈指数增长,导致组合爆炸。即空间复杂度高。
例子:分油问题,一个8L和一个6L的空瓶子。没有测量仪,最后要在8L瓶子里得到4L油。可以进行如下操作:从油壶里将8L瓶子倒满;从油壶里将6L瓶子倒满;将8L瓶子倒空到油壶;将6L瓶子倒空到油壶;两个瓶子互相倒空或倒满。
那:广度优先搜索树如下:
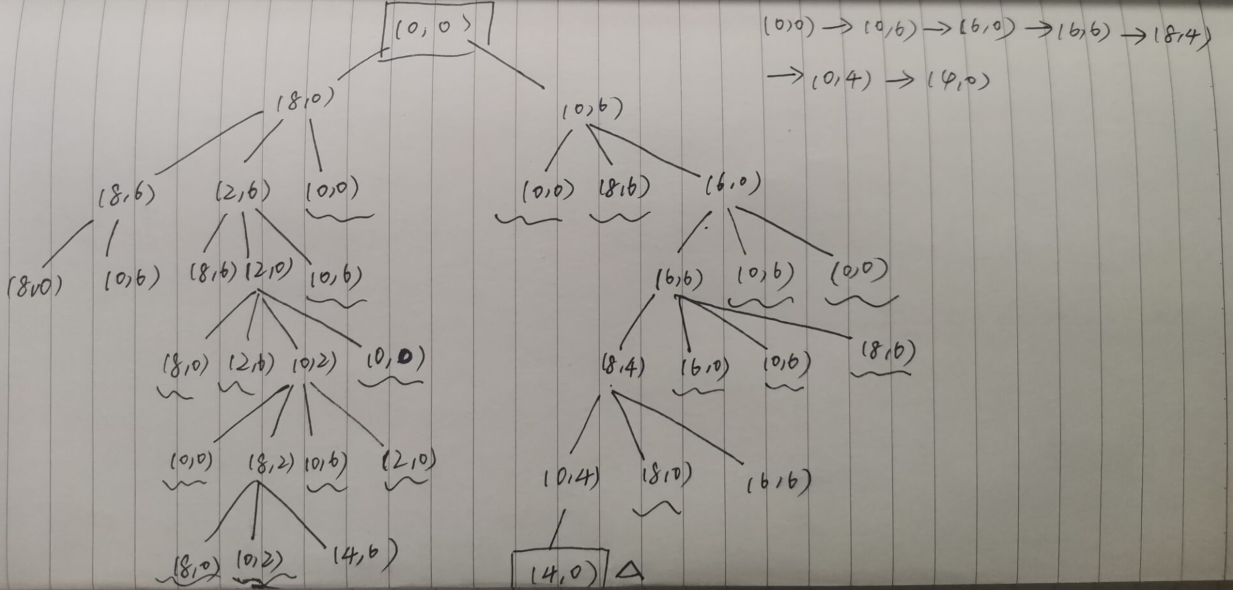
深度优先搜索树如下:

3. 迭代加深搜索(iterative deepening, IDDFS)
搜索策略: 在固定深度上,重复深度优先搜索,若把所有可能全部遍历完还没找到目标解,就增加深度,从头开始再重复深度优先搜索,直到找到目标节点。
例子:对于如下一棵树:
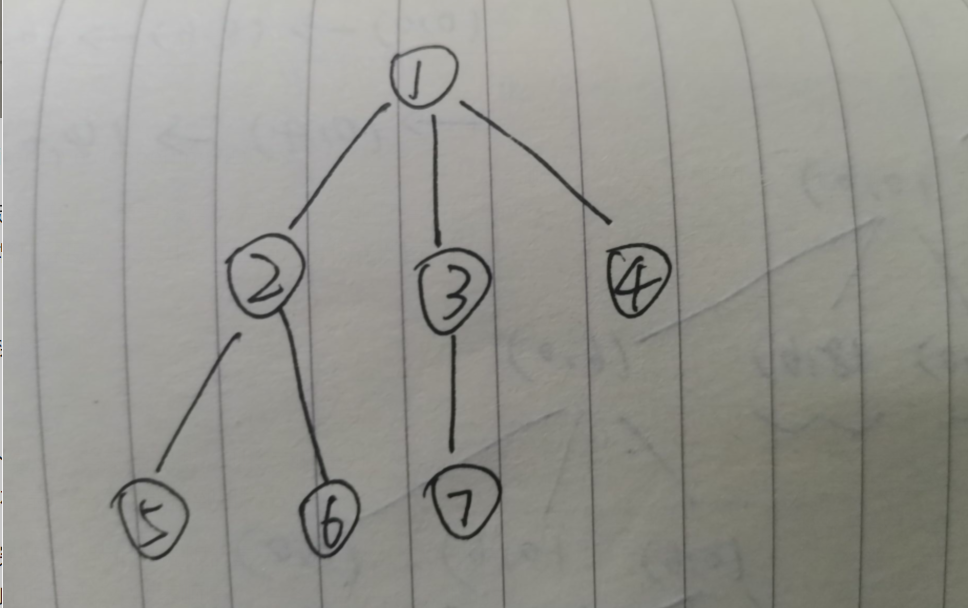
若我们想找到4这个结点,若采用深搜,则搜索顺序为:1—>2—>5—>6—>3—>7—>4。也就是在最后一次才能找到目标节点。
但是若采用迭代加深搜索,我们首先限制最大深度max_d=1,只有根节点,没找到。max_d++,此时等于2,搜索顺序:1—>2—>3—>4。此时就已经找到目标节点,就不用再往下搜索了。
迭代加深搜索的优点:空间复杂度与DFS相同,比BFS小得多。若有解,则一定找到最优解,因为深度最小。
其标志性结构:
while(!dfs(maxdep)){
max_d++;
}
也就是说,如果搜索树特别深,但是我们又能确定目标节点所在深度比较小时,就可以使用IDDFS。
启发式搜索
- 利用度量作为指南的搜索。
1. 最佳优先搜索(Best-first Search)
搜索策略: 按照度量进行排序,按该顺序对相应结点进行扩展。
其实就是用小顶堆或者大顶堆实现的BFS。c++用优先队列priority_queue。
启发式搜索的重要度量:评价函数 f(n)。 我们用f(n)表示从初始结点S经结点n到达某一目标t的最佳路径的代价f*(n)的估计。
f(n)由两部分组成:
- 从S到n的最佳代价g*(n)的估计g(n)
- 从n到t的最佳代价h*(n)的估计h(n)
- 即f(n) = g(n) + h(n)作为f(n) = g*(n) + h*(n)的估计
启发式搜索基本原理:按评价函数计算出它的最佳代价估计值,从当前估计值的最小状态开始继续搜索,这就是以结点的代价估计值为标准的最佳优先搜索。
2. 启发式图搜索(包括A算法)
例子:九宫格重排问题。要求从左边的初始状态转移到右边的目标状态。

-
若采用广度优先搜索:初始取g(n)=d(n),h(n)=0;其中d(n)为结点n的深度。为了加快搜索进程,目标结点一旦生成就立即放在open表中。需要生成47个结点。
-
若采用深度优先搜索:其它同上。最少只需要6个结点 ,多则可达100多个结点。
-
若采用A算法:①初始取g(n)=d(n),h(n)=w(n);其中w(n)表示以目标为基准,结点n的状态中不在位将牌的个数。由于从结点n转换成目标结点至少需要w(n)步,所以对任意n,恒有w(n) ≤h*(n)。需生成14个结点。 如图:

②取g(n)=d(n),h(n)=p(n),其中p(n)表示结点n的每一将牌与其目标位置之间的距离总和。易见, w(n) ≤p(n) ≤ h*(n) 。p(n)比w(n)更具启发能力,只需要生成12个结点便可以完成搜索。如图:

以上搜索技术的改进
- 前面的搜索都是从初始状态出发,一步步搜索到目标状态,称为数据驱动或向前搜索。
- 若从目标状态出发搜索到初始状态,则称为目标驱动或向后搜索。
- 向前和向后搜索结合,从初始和目标状态同时出发的搜索称为双向搜索。
- 如果搜索的对象是问题,搜索的原则是把一个复杂问题化成一组简单的子问题的“与”,“或”,则称为问题空间搜索。
- 如果有两方博弈,每一方在向目标(取胜)前进的同时力图阻止对方接近目标,则称为博弈搜索。
优化搜索技术
1. 爬山搜索
搜索策略: 最佳优先搜索的变形——不保存搜索过的所有结点,而只保存当前遇到的那些最佳结点。
算法步骤:
1). 取n为初始结点
2). 如果n的估计值大于其所有子结点的值,则返回n并退出
3). 否则,取n为其具有最大值的子结点,返回2步
这是面向最大值而设计的,若面对的是求最小值的优化问题,只要把步骤中的“大于”改成“小于”, “最大”改成“最小”。
爬山搜索特点:具有通用性和灵活性;但得到的解是局部最优解,不能保证是全局最优解,容易陷入局部最优。
2. 梯度下降搜索
针对目标函数是具有连续可微性质的爬山搜索方法。常见于神经网络学习算法中。
3. 博弈搜索
极大极小搜索:每个结点边上数字为该节点得分, 也即该结点的静态估价函数f(n)。
1.从根节点层开始依次标MAX、MIN、MAX……层一直标到叶子节点层。
2.从叶子结点开始从左向右、从下往上取值。MIN层要选择不利于MAX局面的点,即选择其子节点中(即在 MAX 层上)最小值;MAX层要选择不利于MIN局面的点,即选择其子节点中(即在 MIN 层上)最大值。















 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









