






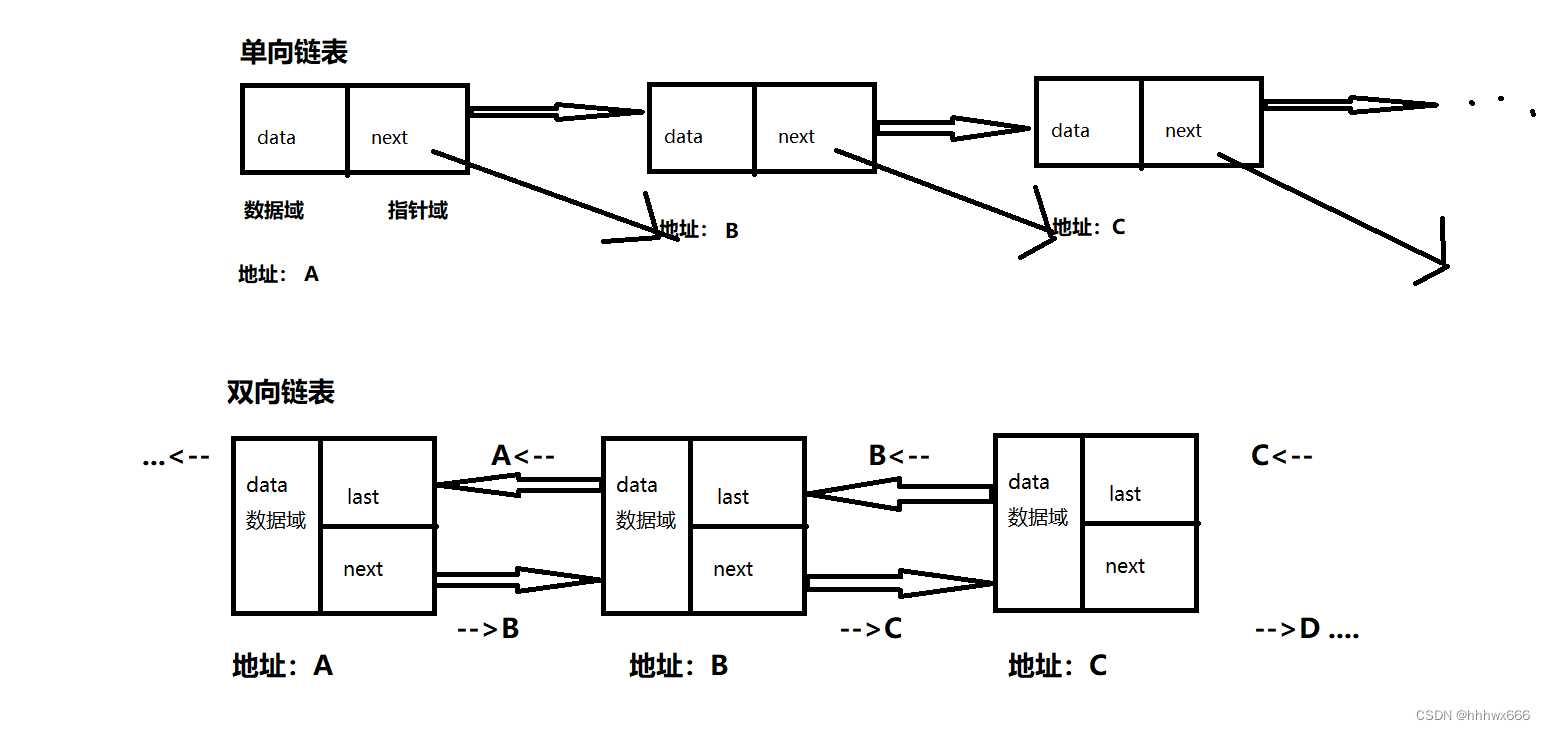
一.链表概念
链表(Linked list)概念:
节点 - 数据域(具体信息) ,指针域(前后结点地址)
* 链表是一种常见的基础数据结构,也属于线性表
* 常见有 单向链表,双向链表,循环链表,动态链表
特点:
动态存储,非连续空间(非线性,非顺序的物理结构),
内存不连续,依靠指针域链接
插入删除的时间复杂度为O(1)
查找的时间复杂度为O(n)
二.单向链表
顾名思义,只有一个方向的链表 也就是 从头结点依次向后指向最后一个尾结点
//为了存储 数据与地址,这里使用结构体存储多种不同类型信息
struct Link_list
{
//数据域(data)
int NUM;
string Name;
//指针域
Link_list* next;
};
//当然也可以使用 typedef 简化结构体名称
typedef Link_list LB;
//这里需要注意 这里使用 typedef 在定义Link_list 结构体之后,所以在结构体中 指针域那块不能使用简化后的
//遍历链表的函数
template<class T>
void Traversal(T * flag)
{
T* item = flag->next;
while (true)
{
cout << "NUM: " << item->NUM<<endl;
if (item->next == NULL) break;
item = item->next;
}
}
//EG1 单向链表
void EG1()
{
//顾名思义,只有一个方向的链表 也就是 从头结点依次向后指向最后一个尾结点
// 首先,创建一个头结点 它只包含指向下一个结点的地址 只起到索引整串链表作用 也方便对所有结点进行删减排序
LB Head_1;
//当然,这也可以直接设置为一个指向下一个结点的指针 更省空间
//然后创建第一个 存储信息的结点
LB A;
A.NUM = 1;
A.Name = "A";
// 然后 将头结点地址指向第一个结点,就可以实现单向连接
Head_1.next = &A;
//后面链接也是如此
LB B, C, D;
B.NUM = 2;
C.NUM = 3;
D.NUM = 4;
//
A.next = &B;
B.next = &C;
C.next = &D;
D.next = NULL; //D是最后一个结点,所以就指向空,后续以此作为链表结束标志 遍历链表
Traversal(&Head_1);
}

三.循环链表
所谓循环,就是单向链表头尾相连,形成闭环,也就是 尾部结点的指针域 存储 头结点的地址
//EG2 循环链表
void EG2()
{
//所谓循环,就是单向链表头尾相连,形成闭环,也就是 尾部结点的指针域 存储 头结点的地址
//简单修改一下EG1即可
LB Head_1;
Head_1.NUM = 0;
LB A;
A.NUM = 1;
Head_1.next = &A;
//
LB B, C, D;
B.NUM = 2;
C.NUM = 3;
D.NUM = 4;
//
A.next = &B;
B.next = &C;
C.next = &D;
//D.next = NULL; --> D.next= & Head_1;
D.next = &Head_1;
//这里遍历函数就是死循环喽,所以这里用for循环展示6个结点
//循环链表其实也没有首尾部之分了,随便从哪里开始都可以遍历完整条链表
//这里就从A开始吧
LB* item = &A;
for (int i = 0; i < 6; i++)
{
cout << "NUM: " << item->NUM << endl;
item = item->next;
}
}
四.双向链表
双向链表
双向就是 可以 由前指向后 也可以 由后指向前,向前或向后检索链表结点
因此相比单向链表,它的地址域就得有 两个指针 存储这个结点 前面和后面 的结点地址
而根据 头结点和尾结点 存储的地址不同,又可以设计双向普通链表,也就是有头有尾,头以前指向空,尾以后指向空;
或者 头以前指向尾结点地址,尾结点后指向头结点地址 形成双向循环链表
struct SLB
{
string Name;
//地址域
SLB* Last;
SLB* next;
};
void EG3()
{
SLB A, B, C, D;
A.Name = "懒羊羊";
A.next = &B;
A.Last = &D;
//
B.Name = "GG-Bone";
B.Last = &A;
B.next = &C;
//
C.Name = "喜羊羊";
C.Last = &B;
C.next = &D;
//
D.Name = "灰太狼";
D.Last = &C;
D.next = &A;
cout << "Name :" << C.Name << endl << C.next->Name << endl << C.Last->Name << endl << C.Last->Last->Name << endl << C.Last->Last->Last->Name<<endl;
}
五.链表的增添,排序
因为链表并非固定的连续的存储空间,每个结点依靠指针域链接,故只需要更改相应结点指针域的指向,便可以实现链表的增删,排序操作
六.动态链表
上面的案例都是提前设定好的结点,实现的都是静态链表;不能体现链表的灵便,同时只有尝试过任意位置增删结点,或者重新排序,才能体验到链表与数组的区别;下面首先展现一种动态链表的实现案例
#include<iostream>
#include<string>
using namespace std;
struct XXB
{
string Name;
int NUM;
XXB* next;
} ;
int main01()
{
//添加头链表,方便找寻整串链表
XXB head;
//这个OLD用来作为当前输入的载体
XXB* OLDBOX =new XXB;
//第一个链表
head.next = OLDBOX;
//用来执行循环条件
int key = 1;
while (key)
{
//这个NEWBOX是进行下一个链表的接受
XXB* NEWBOX = new XXB;
NEWBOX->next = NULL;
int num;
string name;
cout << "Please cin num " << endl;
cin >> num;
cout << "Please cin name" << endl;
cin >> name;
OLDBOX->NUM = num;
OLDBOX->Name = name;
//从当前接收链表 OLDBOX 指向新链表 NEWBOX
OLDBOX->next = NEWBOX;
//将 新链表地址 赋值给 接收信息的OLD链表
OLDBOX = NEWBOX;
cout << "是否继续输入(0/1)" << endl;
cin >> key;
}
//用 item 接收 链表地址,在循环中进行输出
XXB * item=head.next;
do
{
cout << "Name :" << item->Name<<endl;
cout << "Num :" << item->NUM<<endl;
//指向下一个链表
item = item->next;
} while (item->next);
//退出条件为 下一个链表为空,即末链表
return 01;
}














 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









