







PCA是一种降维的方法,用于将样本从较高的N维投影到较低的K维,PCA认为最好的K维空间是将样本点转换为K维后,每一维的样本方差都很大,方差较大保证了样本点在K维空间构成的超平面上的投影能尽可能的分开。
那么如何能找到符合条件的K维空间了?下面以将样本投影到某一维上为例:
首先对所有的样本进行中心化,即将样本减去他们的均值,
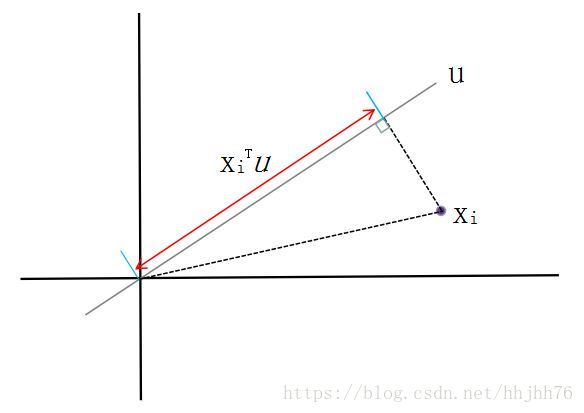
上图中 X i X_{i} Xi为其中一个样本点,将 X i X_{i} Xi投影到 u ( ∣ ∣ u ∣ ∣ = 1 ) u(||u||=1) u(∣∣u∣∣=1)上
由于样本点已经进行中心化,所以其每一维特征均值都是0,因此投影到 u u u上的样本点的均值仍然是0。最佳的 u u u要使得投影后的样本点方差最大,方差可以用下面式子计算:
1 m ∑ i = 1 m ( X i T u ) 2 = 1 m ∑ i = 1 m u T X i ⋅ X i T u = u T ⋅ ( 1 m ∑ i = 1 m X i ⋅ X i T ) ⋅ u \frac{1}{m}\sum_{i=1}^m(X_{i}^{T}u)^2=\frac{1}{m}\sum_{i=1}^mu^{T}X_{i}\cdot X_{i}^{T}u=u^{T}\cdot(\frac{1}{m}\sum_{i=1}^{m}X_{i}\cdot X_{i}^{T})\cdot u m1∑i=1m(XiTu)2=m1∑i=1muTXi⋅XiTu=uT⋅(m1∑i=1mXi⋅XiT)⋅u
令
λ
=
1
m
∑
i
=
1
m
(
X
i
T
u
)
2
\lambda=\frac{1}{m}\sum_{i=1}^{m}(X_{i}^{T}u)^2
λ=m1∑i=1m(XiTu)2 ,
∑
=
1
m
∑
i
=
1
m
X
i
⋅
X
i
T
\sum=\frac{1}{m}\sum_{i=1}^{m}X_{i}\cdot X_{i}^{T}
∑=m1∑i=1mXi⋅XiT (X的协方差矩阵为
1
m
−
1
∑
i
=
1
m
X
i
⋅
X
i
T
\frac{1}{m-1}\sum_{i=1}^{m}X_{i}\cdot X_{i}^{T}
m−11∑i=1mXi⋅XiT)
则:
λ
=
u
T
∑
u
\lambda =u^{T}\sum u
λ=uT∑u
⟹
\Longrightarrow
⟹
λ
u
=
u
λ
=
u
⋅
u
T
∑
u
=
∑
u
\lambda u=u\lambda=u\cdot u^{T}\sum u=\sum u
λu=uλ=u⋅uT∑u=∑u
⟹
\Longrightarrow
⟹
λ
u
=
∑
u
\lambda u=\sum u
λu=∑u
λ \lambda λ是 ∑ \sum ∑的特征值, u u u是特征向量。最佳投影直线是特征值 λ \lambda λ最大时对应的特征向量,其次是 λ \lambda λ第二大对应的特征向量,以此类推。
所以PCA算法如下:
输入:样本集
D
=
{
X
1
,
X
2
,
.
.
.
,
X
i
,
.
.
.
,
X
m
}
,
低
维
空
间
维
数
K
D=\{X_{1},X_{2},...,X_{i},...,X_{m}\},低维空间维数K
D={X1,X2,...,Xi,...,Xm},低维空间维数K
过程:1.对所有样本进行中心化:
X
i
⟵
X
i
−
1
m
∑
i
=
1
m
X
i
X_{i}\longleftarrow X_{i}-\frac{1}{m}\sum_{i=1}^{m}X_{i}
Xi⟵Xi−m1∑i=1mXi
2.计算样本的协方差矩阵
X
X
T
XX^T
XXT
3.对协方差矩阵
X
X
T
XX^{T}
XXT做特征值分解
4.取最大的K个特征值所对应的特征向量
W
1
,
W
2
,
.
.
.
,
W
k
W_{1},W_{2},...,W_{k}
W1,W2,...,Wk
输出:投影矩阵
W
∗
=
(
W
1
,
W
2
,
.
.
.
,
W
k
)
W^{*}=(W_{1},W_{2},...,W_{k})
W∗=(W1,W2,...,Wk)
将原数据与投影矩阵相乘即得到降维后的数据
由于数据进行了中心化,且协方差矩阵是对称的,所以
W
i
W_{i}
Wi是标准正交基向量,
∣
W
i
∣
=
1
,
W
i
T
W
j
=
0
|W_{i}|=1,W_{i}^{T}W_{j}=0
∣Wi∣=1,WiTWj=0
参考书籍:《机器学习》














 3052
3052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









