







睿思是个很好的平台,给西电er在科研之余带来了很多的乐趣,在水睿思的时候就想能不能写个程序自动回复帖子,于是就有了玩转睿思系列博客。睿思自动回帖共包括三部分:
玩转睿思一:模拟浏览器回帖
玩转睿思二:生成回帖信息
玩转睿思三:自动有选择地回帖
本文对使用浏览器回复睿思帖子的过程进行了分析,并模拟浏览器回帖
一.睿思回帖分析
要使用代码模拟浏览器对睿思上的帖子进行回复,就需要对浏览器的回帖过程进行分析:
使用火狐浏览器开发者工具中的查看器对浏览器回帖进行监视,发现睿思回帖就是向服务器发送一个post表单,表单如下:
请求网址:http://rs.xidian.edu.cn/forum.phpmod=post&action=reply&fid=94&tid=982549&extra=&replysubmit=yes&infloat=yes&handlekey=fastpost&inajax=1
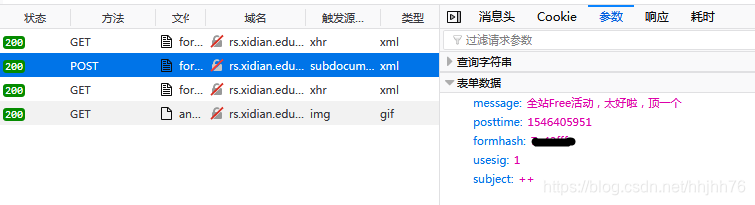
从上面可以看出,回复帖子只要需要6个参数:fid(帖子所属于版区),tid(帖子的id),message(回复内容),posttime(posttime),usesig,subject。
二.获取回帖所需数据
1.回帖参数的获取分析
经过重复实验发现每次usesig,subject的内容是固定的,posttime是发帖时间可以自己生成,只需要找到fid,tid,fromhash,这几个数据都可以在帖子贴面的源码中找到。
<a href="forum.php?mod=forumdisplay&fid=139" hidefocus="true" class="returnlist" title="返回列表"><b>返回列表</b></a>
<link href="http://rs.xidian.edu.cn/forum.php?mod=viewthread&tid=981882" rel="canonical" />
<span class="pipe">|</span><a href="member.php?mod=logging&action=logout&formhash=7e43fffa">退出</a>
fid可以在帖子代码中搜索"fid="得到,其中搜索结果中最后一个是正确的;tid可以在帖子代码中搜索"tid="得到;formhash可以在帖子代码中搜索"formhash="得到。
2.获取回帖参数
<1> 获取网页内容
'''
User-Agent':客户端,这里将客户端伪装成火狐浏览器
cookie:记录客户端的用户信息,可以登录用户后在浏览器中查看
200表示请求成功,返回所有的数据
304表示get的url在之前已经访问过,文档内容没有改变,在浏览器中有数据的缓存,则返回部分数据
'''
def get_html(url,cookie,userAgent):
headers = {'User-Agent':userAgent , 'Cookie':cookie}
r = requests.get(url,headers = headers)
if r.status_code == 200 or r.status_code == 304:
return r.text
else:
print('get html error')
return None
上面为获取帖子页面源码的代码,'User-Agent’和‘cookie’可以在消息请求头中找到。
<2> 获取fid,tid和formhash
def get_info(info_type,htmlText):
if info_type == 'fid':
pattern = 'fid=\w+'
start_index = len('fid=')
elif info_type == 'tid':
pattern = 'tid=\w+'
start_index = len('tid=')
elif info_type == 'formhash':
pattern = 'formhash=\w+'
start_index = len('formhash=')
else:
print("info get error:info_type error")
return None
if info_type == 'fid':
#帖子的返回类内容中有多个fid=,最后一个正确的,前面的不确定
searchObj = re.findall(pattern,htmlText)
else:
searchObj = re.search(pattern,htmlText)
if not searchObj:
print("info get error:{} get error".format(info_type))
return None
else:
if info_type == 'fid':
line = searchObj[-1]
else:
line = htmlText[searchObj.span()[0]:searchObj.span()[1]]
info = line[start_index:]
return info
三.回复帖子
def my_post(message,formhash,fid,tid,cookie,userAgent):
postUrl = 'http://rs.xidian.edu.cn/forum.php?mod=post&action=reply&fid={}&tid={}&extra=&replysubmit=yes&infloat=yes&handlekey=fastpost&inajax=1'.format(fid,tid)
postTime = str(int(time.time()))
usesig = '1'
subject = ''
#回复中不应该包含的词
sensitiveWords = [] #可以使用 python包textfilter来过滤敏感词
for senw in sensitiveWords:
if senw in message:
print('masegge is sensitive:',message)
return None
#睿思要求回复的内容不小于13个字符,这里对回复内容字节长度进行判断,若小于13后面加表情
msAdd = ['{:10_368:}','{:10_395:}','{:10_466:}','{:10_473:}','{:10_462:}']
while len(bytes(message,encoding='utf-8'))<13:
message = message + msAdd[random.randint(0,len(msAdd)-1)]
message = message + ' 祝楼主元旦快乐 '
headers = {'User-Agent':userAgent , 'Cookie':cookie}
data = {'message':message,'posttime':postTime,'formhash':formhash,'usesig':usesig,'subject':subject}
r = requests.post(postUrl,data=data,headers=headers)
if r.status_code == 200 or r.status_code == 304:
return (message,postTime)
else:
print('post error')
return None
将上面的几个函数都放到 AutoReply.py
import requests
import re
import time
from bs4 import BeautifulSoup
def get_html(url,cookie,userAgent):
pass
def get_info(info_type,htmlText):
pass
def my_post(message,formhash,fid,tid,cookie,userAgent):
pass
使用下面代码实现堆tid为982549的帖子进行回复
import AutoReply
cookie = '' #浏览器中可以查看
userAgent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
tid = 982549
url = 'http://rs.xidian.edu.cn/forum.php?mod=viewthread&tid={tid}'.format(tid = tid)
htmlText = AutoReply.get_html(url,cookie,userAgent)
fid = AutoReply.get_info('fid',htmlText)
formhash = AutoReply.get_info('formhash',htmlText)
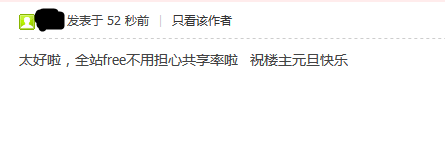
message = '太好啦,全站free不用担心共享率啦'
AutoReply.my_post(message,formhash,fid,tid,cookie,userAgent)
代开睿思tid为982549的帖子,就可以看到回复成功

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









