










知识图谱相当于一张网,是一种大型知识库,一种揭示实体之间关系的语义网络,是事物及其关系的形式化描述,分为通用知识图谱和领域(行业)知识图谱,如DBpedia,OpenKG,Wikidata. 知识图谱为多源、异构、海量、动态数据的表达、组织、管理和利用等提供了一种更为有效的方式,知识图谱促进了理解和处理,使得智能化水平更高,更接近人类认知思维。
大家研究知识图谱,其实主要是关注知识图谱和智能化之间的关系,特别是知识图谱与认知智能的关系。
知识图谱与认知智能的关系:认知的高度决定你创造价值的高度,包括你对世界的认知和世界对你的认知。认知的基础是知识,需要我们从数据中挖掘形成知识,进而提升认知,实现人工智能的认知能力提升,提升业务人员的决策效率。
智能类型主要分为计算智能、感知智能和认知智能,详见图1-1,认知智能具有对信息的获取处理、存储、转化和应用能力。认知智能是产业实现突破的核心手段,协同的基础是认知意图、数据、知识之间的逻辑关系和业务意义,用于辅助分析决策,人工智能的新一代趋势要求利用知识、数据、算法和算力,将符号学知识驱动的AI和数据驱动的AI结合起来,形成强大的认知决策智能,提升人、物和企业的信息博弈能力。
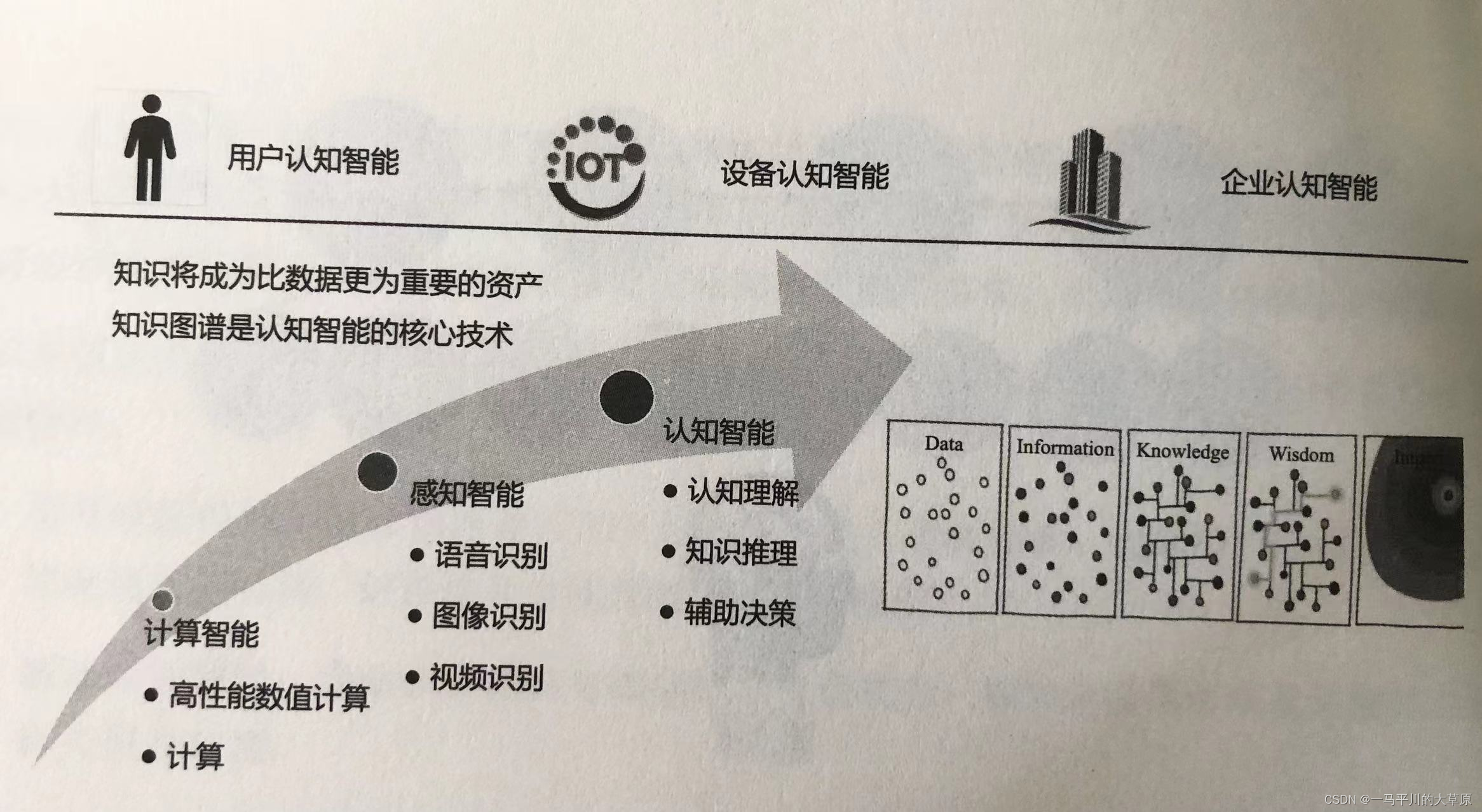
图1-1
通过学习知识图谱构建及应用案例,了解到知识图谱的构建是一项长期发展和优化的过程工程,需要不断的研究探索和应用实践。知识图谱的落地研究有符号学派、统计学派和图网络学派。目前学术界研究较多的图神经网络(GNN)综合了符号和图拓扑结构信息。
知识图谱的发展历程,详见图1-2。

图1-2
知识图谱主要涉及到知识抽取、表示、融合、建模、推理等关键环节的解决与突破,知识图谱的构建过程详见图1-3。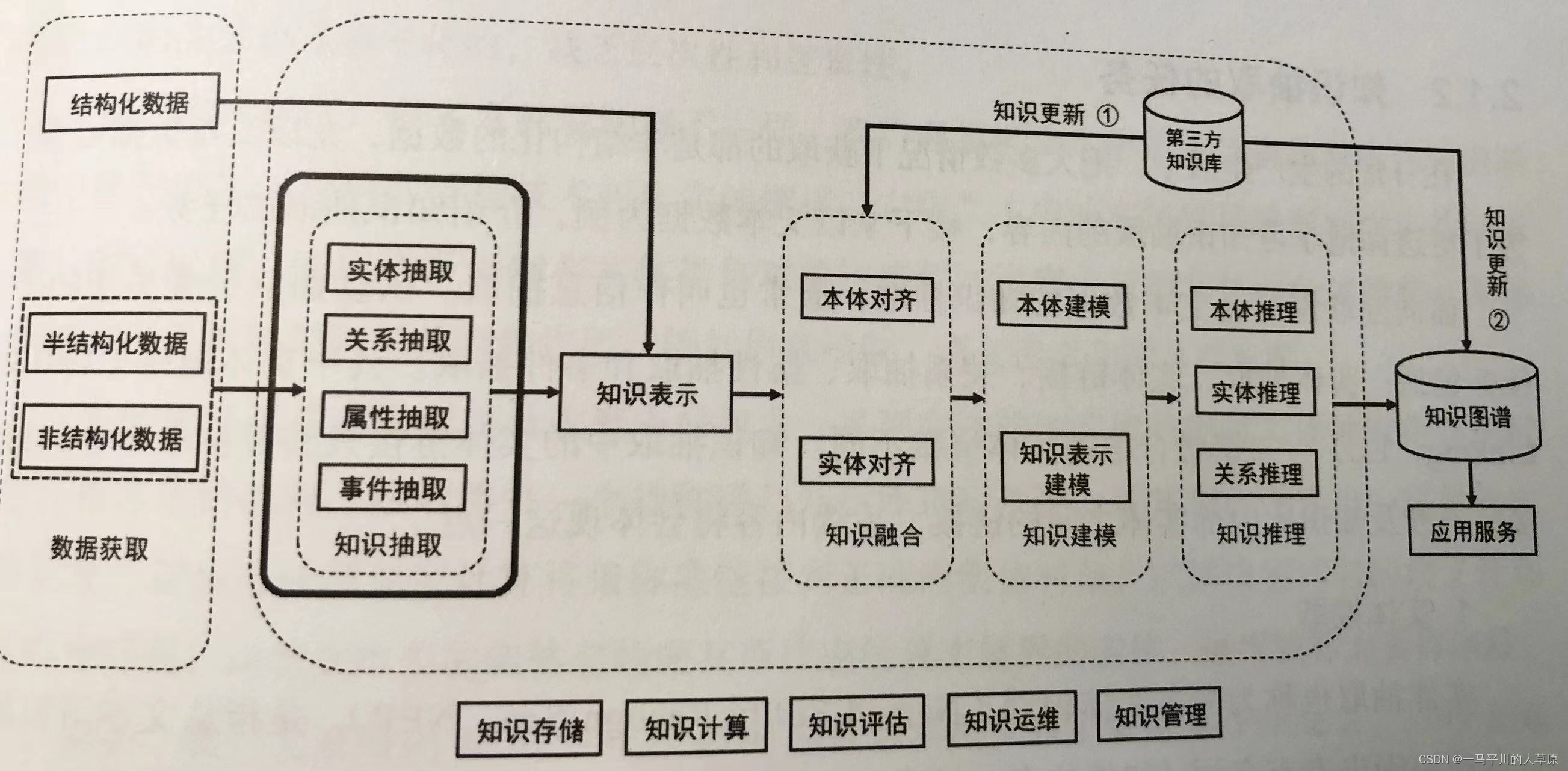
图1-3
一、知识抽取
知识抽取是从结构化、半结构化、非结构化数据中提取实体、关系及属性等知识要素,同时基于语句和语境抽取实体间关系及实体所描述的事件,以便于后续的知识融合。
知识抽取也叫做信息抽取,主要任务有实体抽取、实体链接(包括链接、实体消岐和共指消解)、关系抽取、属性抽取和事件抽取,主要方法有众包法、爬虫法、机器学习法和专家法。
结构化数据的信息抽取见下图
半结构化数据的信息抽取主要通过编写数据清洗、标注和解析评估来实现,主要通过XPath对表格、列表和网页进行解析实现信息抽取。
非结构化数据的信息抽取主要通过隐马尔可夫模型(HMM)、条件随机场(CRF)、长短时记忆(LSTM)等实现实体抽取。关系抽取主要有基于触发词、基于依存句法分析的模板抽取方法,基于监督学习方法和基于弱监督学习方法的抽取。
二、知识表示
知识表示是如何用合适的方式来表示各种知识要素,相当于将知识符号化的过程,以便计算机能够理解,主要有基于符号,基于向量的知识表示。
基于符号表示法主要有早期的一阶谓词逻辑表示、产生式规则表示、语义网络表示、框架表示法,语义网表示法有RDF、RDFS、OWL方法。
基于向量的表示法主要有TransE、TransH、TransR、TransD、TransSparse,组合模型,三元组的神经网络模型等
三、知识融合
知识融合是通过冲突检测、真值发现等技术进行消除冲突,进行关联与合并的过程,主要有概念层的本体对齐和数据层的实体对齐。本体对齐明确一个统一的知识体系。通过融合形成高质量的知识图谱。知识融合任务的执行流程详见下图。
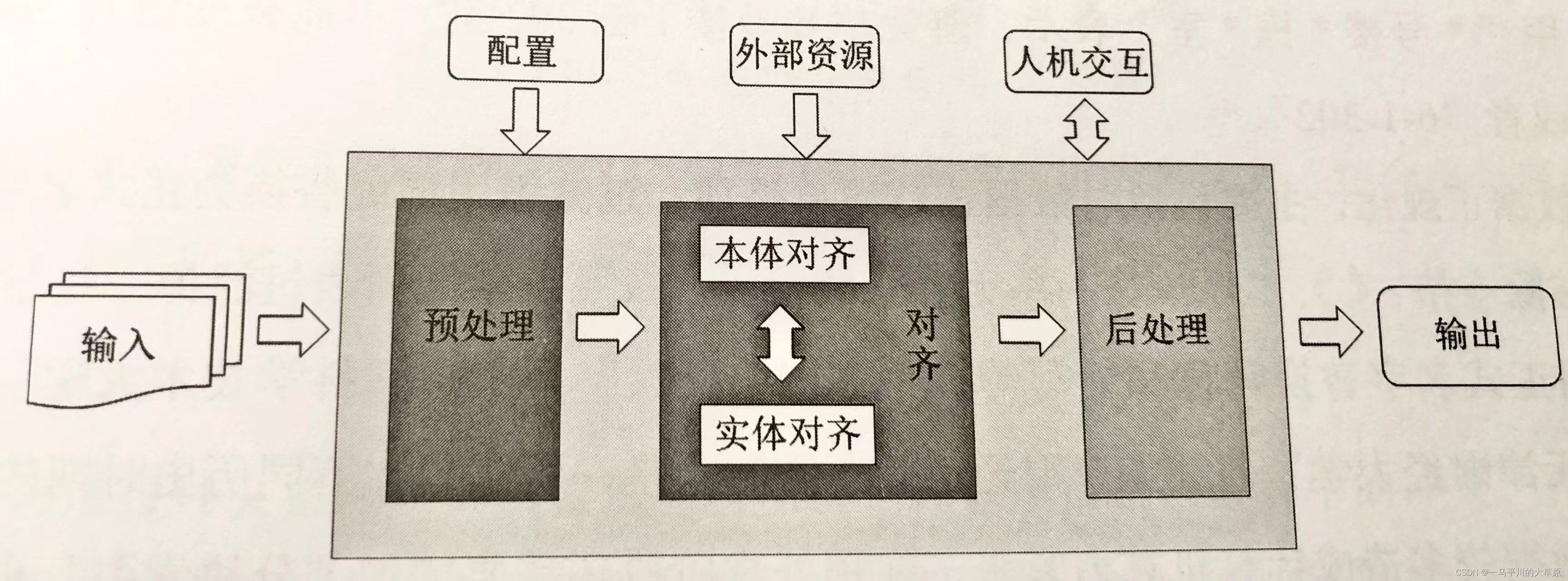
本地对齐方法有基于字符串比较、基于路径结构和基于实例方法。
实体对齐方法有属性相似度(文本字符串、聚合相似度和向量相似度)和实体相似度(聚合、聚类和嵌入式知识表示)
四、知识建模
知识建模是建立知识图谱的数据模式,是构建知识图谱规范的过程,相当于通过知识建模,使得知识更加组织有序、层次分类和简洁关联。
知识建模:Top-Down和Down-Top,前者是从泛化到专精化,后者是从专精化--抽象--泛化。知识建模主要包括两个任务或步骤,本体建模和知识表示建模,本体建模建立概念层的层次结构,达到人类可理解的程度,知识表示建模建立知识图谱数据层的模型,得到图谱数据模型,使得计算机可理解这些数据之间的关系。
知识建模方法有手工建模方法、半自动建模和数据驱动的本体自动建模。
手工建模方法:包括明确本体及任务、模型复用、列出本体涉及领域中的元素、明确分类体系、定义类的属性和关系、定义属性的约束条件和创建实例等七个步骤,详见下图。
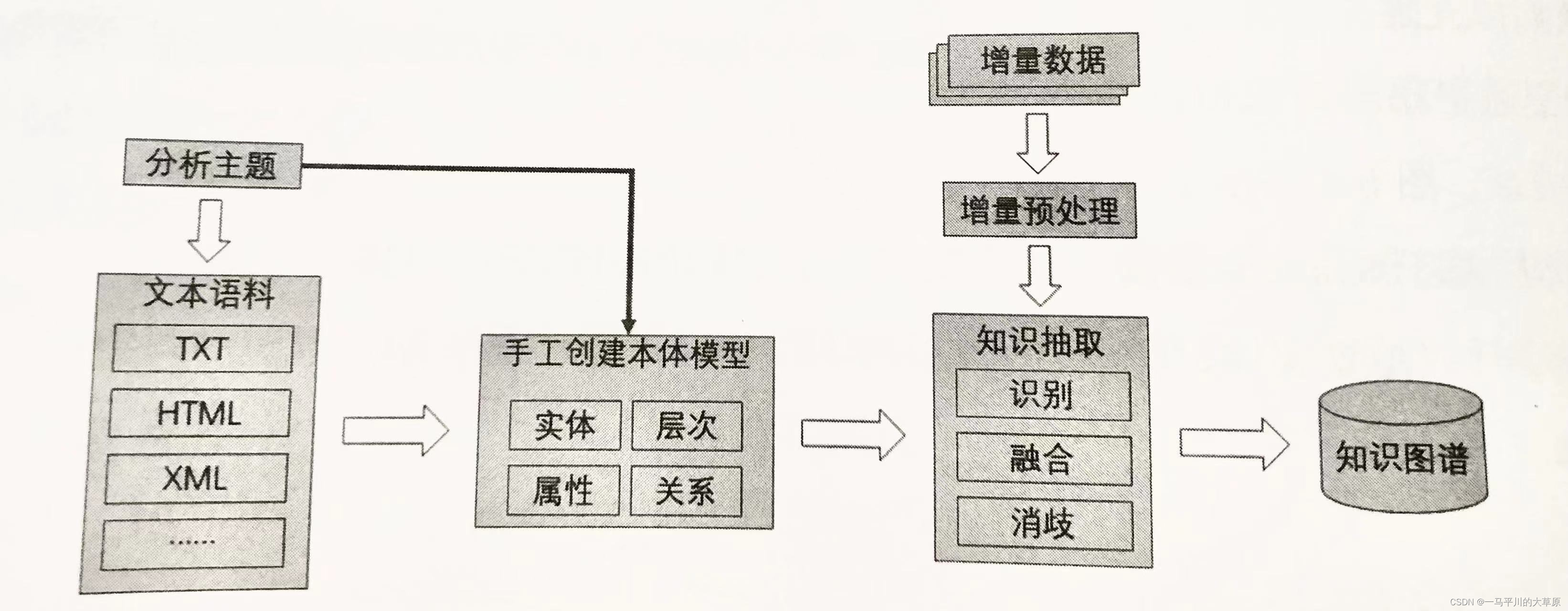
半自动建模:详见下图所示

本体自动建模:数据驱动的本体自动建模包括实体并列关系计算、实体上下位关系抽取、本体生成等,详见下图所示。
五、知识推理
察己则可以知人,察今则可以知古,通过丰富扩展知识库,更好的支持智能检索 、推荐和知识问答等,丰富挖掘隐含的知识,知识推理其实是知识图谱建设的终极目标,通过推理可以弥补数据不足的情况,完成实体预测、关系预测、属性预测和路径预测等。将知识库中的关系和属性等信息补全,也是知识库工程化的重要工作。主要有基于逻辑规则、基于知识表示学习和基于图的推理和混合推理。
逻辑规则主要有一阶谓词逻辑、描述逻辑、概率图逻辑和路径规则逻辑。
知识表示学习推理主要有基于张量分解模型、基于转移的表示逻辑
六、知识存储
知识也是一种数据,也需要存储,知识存储方法主要有基于RDFS、基于NoSQL和基于分布式存储。
基于RDFS:三列表存储、水平表、属性表、全索引表。
基于NoSQL:列式存储、文档存储和图存储
基于分布式:RDFPeers、YARS2、4Store
利用Apache Jena存储数据,可参考SPARQL查询和JENA存储
利用TDB和Fuseki存储和管理三元组,可以通过SPARQL进行查询,进入目录运行fuseki-server.bat
利用Neo4j存储数据:实现了从json抽取数据到neo4j,从mysql 抽取数据到neo4j。
七、知识计算
知识计算也叫做知识应用,相当于通过知识统计、图挖掘、知识推理等方法与传统应用的结合,提供知识补全、知识纠错,来提高知识完备性扩大知识覆盖面,通过简洁的自然语言形式自动地回答用户提出的问题,实现知识图谱的各类应用。
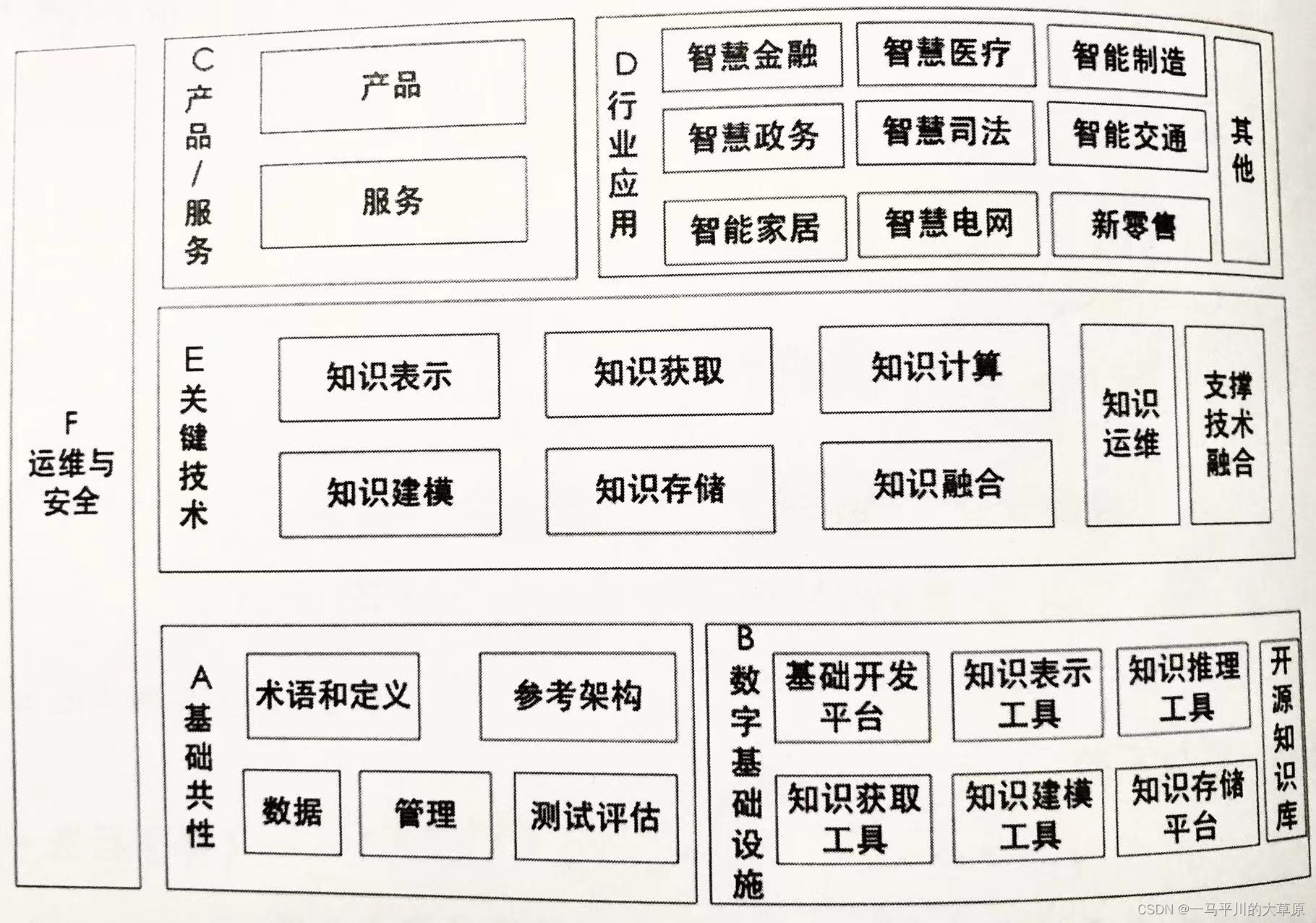
八、知识图谱平台
知识图谱如果想得到规范化建设并得到有效应用,就需要建立知识图谱平台,有些也叫做知识服务平台,逐步解决构建周期长、难度大,复用低等难题,实现知识图谱的一站式平台服务、集成的基础能力和行业场景的解决方案。目前开源的有AiMind知识图谱平台。
知识图谱标准体系结构图详见下图。
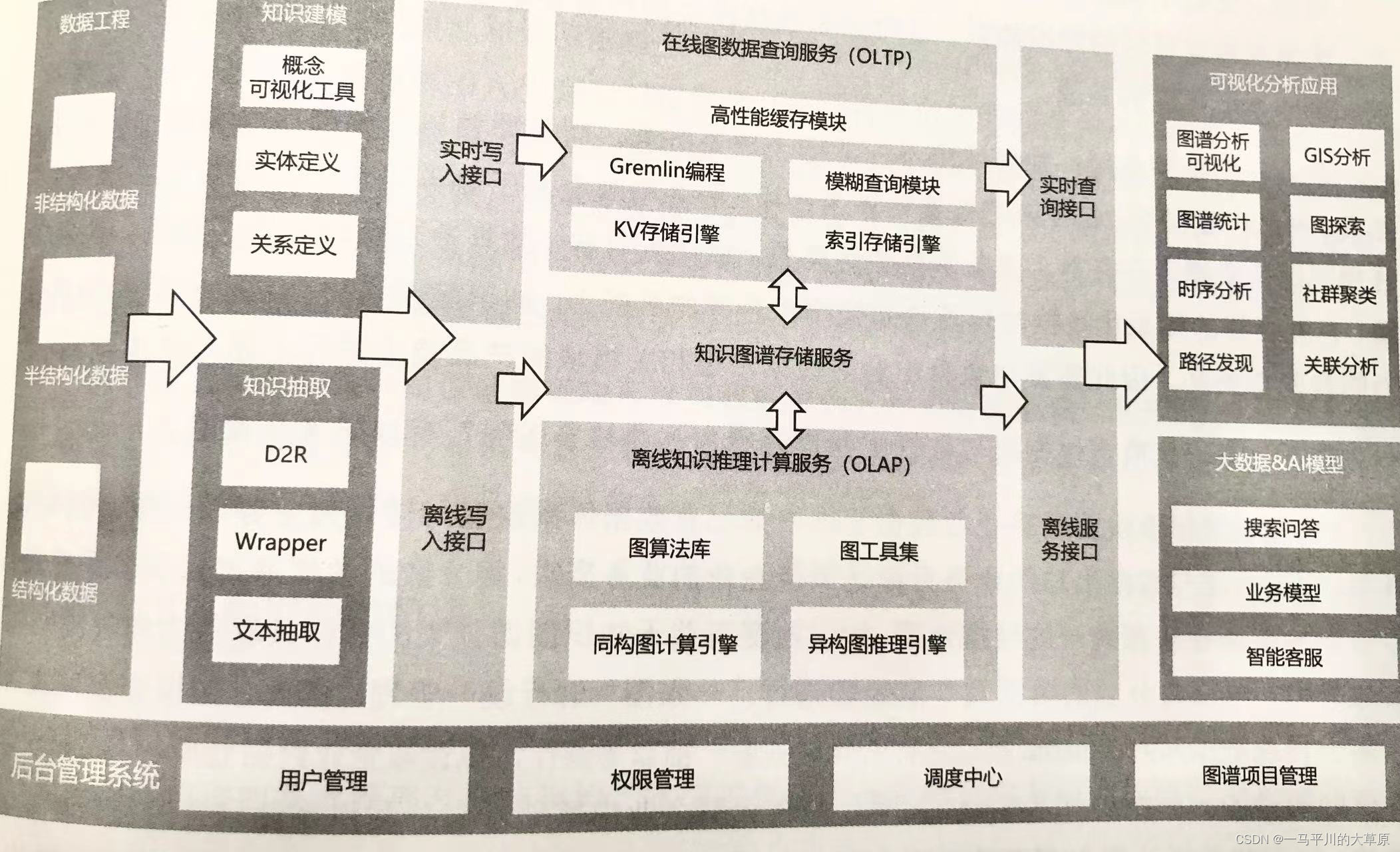
知识图谱管理平台实现将多个数据和知识的所有方、开发方和应用方的需求与认知对齐,形成从认知、建设到服务的一体化、平台化服务产品,平台架构详见下图。
九、知识图谱的应用场景
1.智能搜索
传统的搜索:关键词--网页的匹配关系,没有真正理解用户查询内容本质,即语义理解。
基于图谱的搜索:通过用户提交的问句,首先要对其进行语义理解,不局限于字面本身,准确把握用户真实意图,然后通过对实体、关系和用户的理解,分析交互行为,进行知识检索获取准确答案,图谱更深入、广泛和完备,并且有完整的知识体系,是一种长尾搜索。
2.推荐系统
图谱引入事物的语义信息,提升推荐的相关性、多样性和可解释性。
3.知识问答
引入了文本语义深层次的分析处理,实现深层次的逻辑推理,结合问句语义解析、语义表示技术,并结合知识推理和深度学习算法,使得问答更加智能、更为准确可靠。避免偏差。
4.推理决策
利用知识融合与推理技术,发现潜在规律和关联,利用图谱强大的关系连接能力,将信息整合为一体,从一点穿透到信息潜在的关联部分,比如多跳问题等。比如反欺诈、风险评估等应用。
















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











