







本次使用到的知识
- Python selenium模块
- 百度通用文字识别SDK的调用,api自己去申请,每天最多50次免费调用,文档地址:http://ai.baidu.com/docs#/OCR-API/top,用阿里和腾讯的也可以。
- Python 类的使用
- Python 图片二值化
- Python base64模块
- Python IO
发现问题
上一个博客写的是使用selenium爬取携程网酒店的评论信息,虽然加了一定的休眠,但是好像爬久了还是被携程发现了,等到再次想爬取时必须要先验证,先看一下是携程的验证方法吧

首先进去要做的就是先将滑块滑到最右边
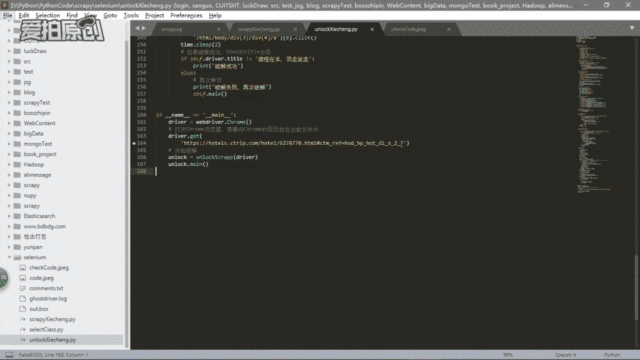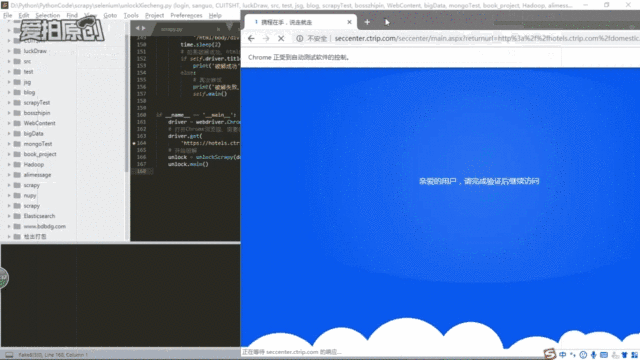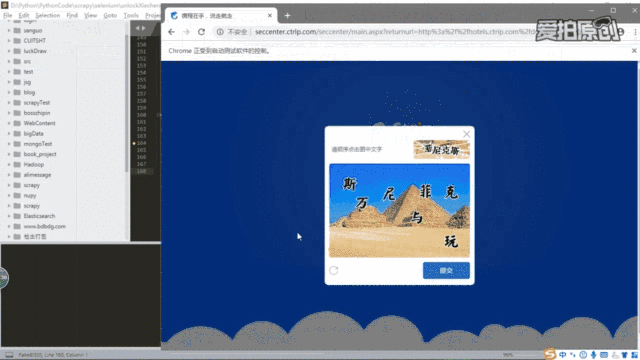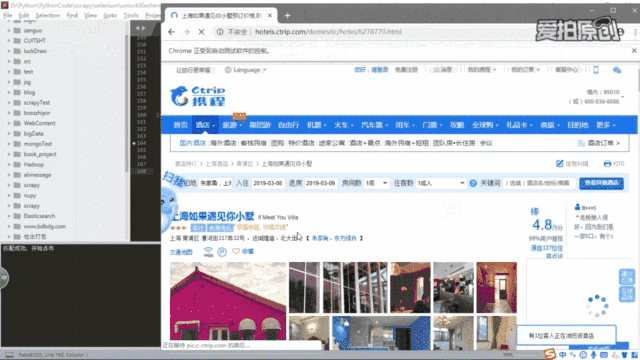
之后出现的就是这种验证

需要根据顺序点击图中的文字。
分析问题
下面我们一个一个的讲怎么破解携程的反爬验证
(1)滑动滑块
这一点相对来说破解的方法比较简单,直接使用selenium模块将滑块滑动到最右端,首先复制滑块的class名称:cpt-img-double-right-outer,然后使用selenium的find_elements_by_class_name获取到滑块元素:
scrollElement = driver.find_elements_by_class_name('cpt-img-double-right-outer')[0]之后使用ActionChains类的click_and_hold方法按住滑块:
ActionChains(driver).click_and_hold(on_element=scrollElement).perform()然后分为三次将滑块移动到最右端:
#第一次滑动
ActionChains(driver).move_to_element_with_offset(to_element=scrollElement, xoffset=30, yoffset=10).perform()
#第二次滑动
ActionChains(driver).move_to_element_with_offset(to_element=scrollElement, xoffset=100, yoffset=20).perform()
#第三次滑动
ActionChains(driver).move_to_element_with_offset(to_element=scrollElement, xoffset=200, yoffset=50).perform()之后滑块验证就被破解了:
(2)按顺序点击文字
这一块相对来说是整个破解最麻烦的一步,但是也不是没有办法,首先需要分析一下人工验证的步骤:
- 认出上面小图中的文字
- 认出下面大图中的文字,并知道每个字的位置
- 根据上面小图中文字按顺序依次点击下面大图中的文字
- 点击提交按钮
- 验证成功
那么问题来了,使用代码怎么完成上面的步骤呢?一个一个来:
识别上面小图中的文字
下载保存小图==》图片二值化,方便识别,因为原图很乱==》调用百度通用文字识别,识别小图中的文字
识别下面大图中的文字,并获取到文字的位置
下载保存大图==》图片二值化,方便识别==》调用百度通用文字识别,识别大图中的文字,并获取到每个字的位置信息
根据上面小图中文字按顺序依次点击下面大图中的文字
根据获取到的小图中的文字+下面大图中文字的位置==》获取到待点击的文字的位置==》调用selenium点击验证
点击提交按钮
点击正确之后使用selenium点击提交按钮,识别成功,不成功则再次验证
代码实现
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
import base64
from PIL import Image
from aip import AipOcr
# 破解携程反爬验证
class unlockScrapy(object):
def __init__(self, driver):
super(unlockScrapy, self).__init__()
# selenium驱动
self.driver = driver
self.WAPPID = '百度文字识别appid'
self.WAPPKEY = '百度文字识别appkey'
self.WSECRETKEY = '百度文字识别secretkey'
# 百度文字识别sdk客户端
self.WCLIENT = AipOcr(self.WAPPID, self.WAPPKEY, self.WSECRETKEY)
# 按顺序点击图片中的文字
def clickWords(self, wordsPosInfo):
# 获取到大图的element
imgElement = self.driver.find_element_by_xpath(
"/html/body/div[3]/div[3]/img")
# 根据上图文字在下图中的顺序依次点击下图中的文字
for info in wordsPosInfo:
ActionChains(self.driver).move_to_element_with_offset(
to_element=imgElement, xoffset=info['location']['left'] + 20,
yoffset=info['location']['top'] + 20).click().perform()
time.sleep(1)
# 下载上面的小图和下面的大图
def downloadImg(self):
# 小图的src
codeSrc = self.driver.find_element_by_xpath(
"/html/body/div[3]/div[1]/img").get_attribute("src")
# 大图的src
checkSrc = self.driver.find_element_by_xpath(
"/html/body/div[3]/div[3]/img").get_attribute("src")
# 保存下载
fh = open("code.jpeg", "wb")
# 由于其src是base64编码的,因此需要以base64编码形式写入
fh.write(base64.b64decode(codeSrc.split(',')[1]))
fh.close()
fh = open("checkCode.jpeg", "wb")
fh.write(base64.b64decode(checkSrc.split(',')[1]))
fh.close()
# 图片二值化,便于识别其中的文字
def chageImgLight(self):
im = Image.open("code.jpeg")
im1 = im.point(lambda p: p * 4)
im1.save("code.jpeg")
im = Image.open("checkCode.jpeg")
im1 = im.point(lambda p: p * 4)
im1.save("checkCode.jpeg")
# 破解滑动
def unlockScroll(self):
# 滑块element
scrollElement = self.driver.find_elements_by_class_name(
'cpt-img-double-right-outer')[0]
ActionChains(self.driver).click_and_hold(
on_element=scrollElement).perform()
ActionChains(self.driver).move_to_element_with_offset(
to_element=scrollElement, xoffset=30, yoffset=10).perform()
ActionChains(self.driver).move_to_element_with_offset(
to_element=scrollElement, xoffset=100, yoffset=20).perform()
ActionChains(self.driver).move_to_element_with_offset(
to_element=scrollElement, xoffset=200, yoffset=50).perform()
# 读取图片文件
def getFile(self, filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别上面小图中的文字
def iTow(self):
try:
op = {'language_type': 'CHN_ENG', 'detect_direction': 'true'}
res = self.WCLIENT.basicAccurate(
self.getFile('code.jpeg'), options=op)
words = ''
for item in res['words_result']:
if item['words'].endswith('。'):
words = words + item['words'] + '\r\n'
else:
words = words + item['words']
return words
except:
return 'error'
# 识别下面大图中文字的坐标
def getPos(self, words):
try:
op = {'language_type': 'CHN_ENG', 'recognize_granularity': 'small'}
res = self.WCLIENT.accurate(
self.getFile('checkCode.jpeg'), options=op)
# 所有文字的位置信息
allPosInfo = []
# 需要的文字的位置信息
needPosInfo = []
for item in res['words_result']:
allPosInfo.extend(item['chars'])
# 筛选出需要的文字的位置信息
for word in words:
for item in allPosInfo:
if word == item['char']:
needPosInfo.append(item)
return needPosInfo
except Exception as e:
print(e)
def main(self):
# 破解滑块
self.unlockScroll()
time.sleep(2)
# 下载图片
self.downloadImg()
time.sleep(2)
# 图像二值化,方便识别
self.chageImgLight()
# 识别小图文字
text = self.iTow()
# 获取大图的文字位置信息
posInfo = self.getPos(list(text))
# 由于小图或大图文字识别可能不准确,因此这里设置识别出的文字少于4个则重新识别
while len(posInfo) != 4 or len(text) != 4:
# 点击重新获取图片,再次识别
self.driver.find_elements_by_xpath(
'/html/body/div[3]/div[4]/div/a')[0].click()
time.sleep(2)
self.downloadImg()
time.sleep(2)
text = self.iTow()
posInfo = self.getPos(list(text))
time.sleep(3)
print('匹配成功,开始点击')
# 点击下面大图中的文字
self.clickWords(posInfo)
# 点击提交按钮
self.driver.find_elements_by_xpath(
'/html/body/div[3]/div[4]/a')[0].click()
time.sleep(2)
# 如果破解成功,html的title会变
if self.driver.title != '携程在手,说走就走':
print('破解成功')
else:
# 再次尝试
print('破解失败,再次破解')
self.main()
def unlock():
driver = webdriver.Chrome()
# 打开Chrome浏览器,需要将Chrome的驱动放在当前文件夹
driver.get(
'https://hotels.ctrip.com/hotel/6278770.html#ctm_ref=hod_hp_hot_dl_n_2_7')
# 开始破解
unlock = unlockScrapy(driver)
unlock.main()
if __name__ == '__main__':
unlock()
程序执行后会打开Chrome浏览器,然后就会开始破解携程的验证,破解过程如下:















 2109
2109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









