






计学习理论已经发展了几十年了,最近二十年的感觉是它的繁荣期。我在这一块耗费的时间也多了点,虽然只是草草入门了解,但亦觉得受益良多。
虽然提及统计学习理论的文章多会搭上神经网络的弱点,但是神经网络虽然存在理论上的梯度下降的固有缺陷,可应用起来的效果倒很不错的说。从一个方面来讲,统计学习在可行性的极限上与神经网络没啥区别,跟傅立叶变换这个基础关系很紧密。另外,统计学习理论对于小样本学习的情况比较关注,毕竟现实中样本经常是不够的,所以可以说它的理论成果比较坚实点。
反问题(由结果推原因)很多情况下是病态的,得到的结果跟样本的关系很大,可能样本有一点小小的偏差,那么结果就差的很远,或许这正是过拟合成为问题的理论来源。在此情况下,对样本的处理过程中需要用到正则化理论(通俗讲就是得到近似解)。一说最小二乘法相信你就能很好联系起来了。
对于正则化应用,除了应用样本的数据,后面通常会加上一个惩罚因子,来对拟合进行调节,以期综合性的筛选出最优化的解。在分类问题上的表现就是结构风险最小化(相对经验风险最小化),通常会控制函数的复杂性,因为复杂性通常和过拟合相联系,为了推广性,通常简单性与光滑性是我们所期望的。
后面的内容主要发生在希尔伯特空间。
这个空间所定义的内积空间是对欧氏空间的推广,在其中的元素是函数时(成为一个函数空间),最有意义,不然退回到欧式空间得了,再提一下,里面的元素具有线性性质,加法与标量乘法。
Riesz representation theorem:
在希尔伯特空间(H)中存在一个元素y,使得其对偶空间(构成元素是连续线性泛函)的元素可以表示成这样的形式,h = <x, y>, x是H中的任意一个元素,且可唯一表示成这种形式。对偶空间中的值是实数。我想这个定理是如此的重要,在函数分析领域,你可以把y看作空间的标准正交基的傅立叶级数形式,就不难理解了。
评估泛函的连续性和有界是等同的,所以里斯表示定理说的就是RKHS的问题。
RKHS(再生核希尔伯特空间)的定义,|Ft [f ]| = |f (t)| <= M * ||f ||,对于空间中任意的f。其实这里的M也是代表那个核函数的模,这里可以看作是|Ft [f ]| = <k, f> <= ||K||*||f||,这个式子是柯西-施瓦兹不等式(Cauchy–Schwarz inequality).
核函数可能在现在的应用文章中广泛出现,由其所牵扯出来的便是再生核希尔伯特空间(RKHS).核的再生性的意义其实是由其可以再造出一个它对应的希尔伯特空间,我曾纳闷核具有再生性(reproducing property),纠结于这特性作用与其本身有什么意义,现在回过头来看自己好傻,或许翻译再制造特性不会让人那么迷惑,可见有老师点拨会少消耗些精力与时间。
希尔伯特空间的理论上世纪初就有了,为无穷维线性方程组和量子力学而设,又不是为模式分类而创造,怎么扯上关系的。当做线性回归的时候来解判别函数的时候,通过转换把权向量可写成训练点的线性组合,可发现来自训练例子的信息由训练点对之间的内积给出,这意味着只需要训练点之间的内积(这里的训练点当然或者多是经过高维变换的点)。
核函数该出场了:
核是一个连续函数k,这个函数对于所有的X中的x,z,满足k(x,z) = <f(x), f(z)>,其中f是从X到(内积)特征空间F的一个映射 f: x --> f(x) 属于F。
这意味着可以计算两个点在特征空间的投影之间的内积,而不用显式地求出它们的坐标,标量值,我们喜欢。其实核函数并不是特意为此理论而造,名字当然来自于更早的起名者,来自于积分方程。
同时RKHS的空间范数||f||可以用来来度量假设空间的复杂度,RKHS 是在正则化理论和统计学习理论之间建立联系的基本工具。
接下来从mercer theorem来入手,把一些东西讲一讲。
Mercer theorem里的积分算子
![]()
这里的k是一个连续的对称函数,且积分算子Tk:L2(x)-> L2(x)。
因为积分算子是线性的,那么我们就可以谈论它的特征值与特征函数,下面的图片展示的就是积分算子的特征值与特征函数,当然这是对于特征值与特征向量的推广,且下面的e(.)表示的是标准正交特征函数(非零度量空间必有基,有基便必有正交基,这些标准正交特征函数就是作为空间的标准正交基存在)。
![]()
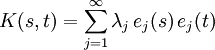
积分算子可以写成这样的一种形式
![]() ,几个式子用的符号不一致,请大家海涵海涵,不容易呀。f 的傅里叶级数代入积分算子,式子一分解,特征值就出现在右边,点明一下免得看着突兀。
,几个式子用的符号不一致,请大家海涵海涵,不容易呀。f 的傅里叶级数代入积分算子,式子一分解,特征值就出现在右边,点明一下免得看着突兀。
上面的K(s,t)式子可看作是函数k<s,.>在t点的傅立叶级数。对于许多核K,正的特征值的个数μ是无限的。对应的的RKHS 在2 L 中是稠密的。这意味着这些假设空间是“大的”,因为它们能够任意好的逼近大量函数类。
我们使用RKHS 的一个原因是因为它能够表示一个非常大的假设集合。
Mercer定理通常用来为有效核构造一个特征空间,且它是根据一个显式的特征向量定义特征空间,而不是用RKHS构造的函数定义特征空间。核可以看作是特征空间的元素内积的形式,与此正定核所对应的函数空间,使用归一化的基。
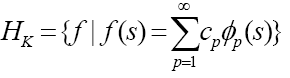 ,
,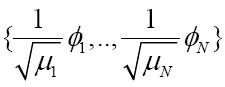
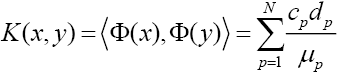
说了这么多,好像没提及模式分类和核函数有啥关系,哈哈,动机来自于感知器模型,通过岭回归的对偶解法,发现特征间的内积包含了所有判断时所要依据的信息。而核函数又有此特性。
还有好多东西可以记,是否还需要追加几章,不确定,还有好多任务没完成。















 5067
5067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









