







在入手了python之后,确实被它简单的特性和上手容易度震惊过。不过python和c语言什么的又确实存在很大的差别,习惯了c语言,使用python的时候多少还是有些不习惯。
入手python一周左右了,为了熟悉和深化对python的理解,就把几种经典的排序算法拿来练手,顺便强化一下自己的基础知识。开始写了,才发现自己写出来的代码问题还真不少,排序的结果总是有各种问题,看来真的是很久没有用这些算法写过东西了,都忘了一些细节的东西了,汗哪。。。
废话不多说,开始练手吧。
排序前需要给定一个数据集,这个用随机数生成就好:
经典算法之冒泡排序(Bubble sort):
经典算法之直接插入排序(Insert sort):
经典算法之希尔排序(Shell sort):
希尔排序的名称源于它的发明者Donald Shell,该算法是冲破二次时间屏障的第一批算法之一,不过,直到它最初被发现的若干年后才被证明了它的亚二次时间界。它通过比较相距一定间隔的元素来工作;各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
经典算法之归并排序(Merge sort):
归并排序算法中,在合并两个已排序的表时,通常的做法是新建一个大小等于它们之和的新表,用于存储这两个表合并的结果,然后把把合并后的表在拷贝回这两个连续的表中。另外一个做法,也可以不分配新的空间存储结果,而是使用插入排序的思想进行合并。
使用分配空间合并的方式,时间复杂度为O(nlogn),使用插入合并的方式,时间复杂度为O(n^2),这里采用python列表的插入和删除机制,比c语言中数组整体往后挪动的插入方式(见注释部分)要高效不少。
经典算法之堆排序:
堆排序的思路是建立在大根堆和小根堆的基础上,具体步骤可以参见网上解释以及上面的源码。
经典算法之快速排序:
在这里,快速排序算法在选择参考值的时候,采用了中值选取的方式,即从区间的第一个,最后一个和最中间的元素,这三个中选择一个中间大小的作为参考值,把这个元素挪动至第一个位置。这个算法可以有效消除快速排序中的最坏时间复杂度。
写出了算法,总要有个东西来验证,写一个单独的部分来执行这些算法,输出个算法花费的时间值,并将他们的执行结果输出至文件中,用于检验执行结果是否正确。
这是某次执行的结果:
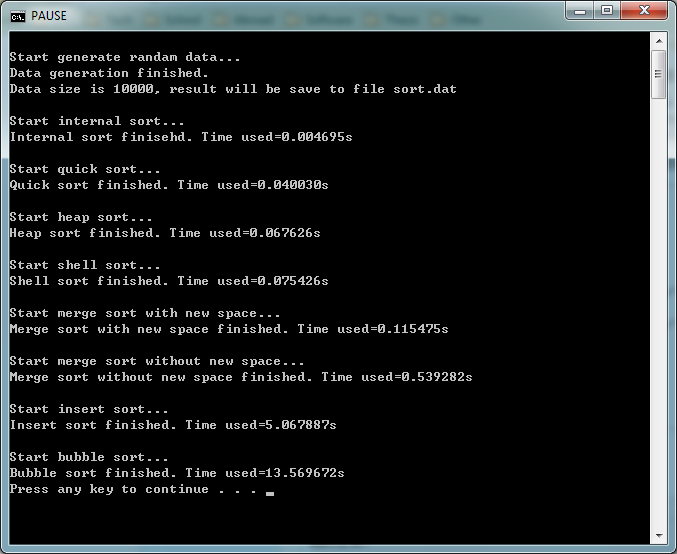
输出结果被保存在当前目录的sort.dat文件中,用记事本打开即可看到。
(看看人家python内置的timSort排序算法,根本就不是一个数量级的,真牛,好快呀。。。)
这就是输出文件的内容显示:
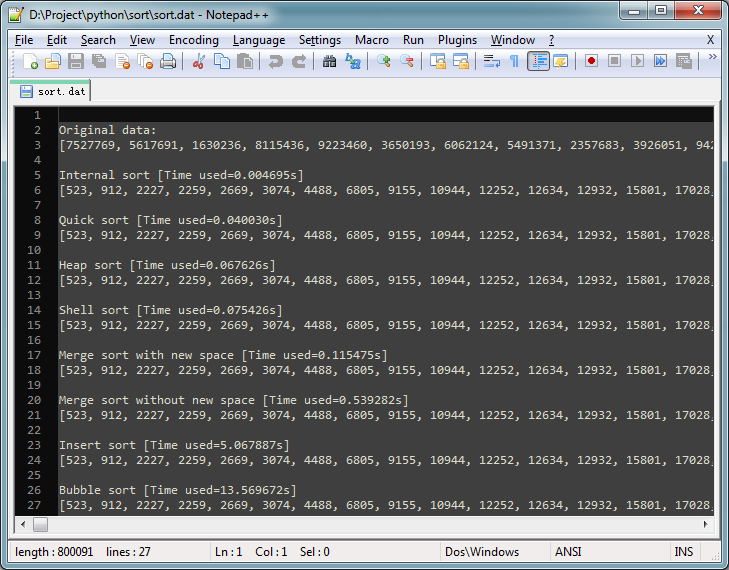















 8750
8750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









