







简单来说,深度模型的输入只能数字类型,现实中的数据则不尽相同,如性别,年龄,商品价格等。
例如:
可以将性别作为特征,男性设置为0,女性设置为1;
也可以将年龄和性别组合后作为一个特征,大于18岁的男为3,小于18岁的女为4。
数字代表模型输入的特征值。
因此,特征抽取就是将这些具体的原始数据通过规则转化为模型可识别的数字(或数组)的过程。本文重点介绍特征分类、特征抽取的过程、特征抽取实现方法、在线特征服务架构。
特征分类
dense/sparse特征
- dense特征,直接作为模型输入
- spase特征,一般通过转为embedding作为模型输入
user/item/context/combo/sequence特征
- user特征,在线服务单次请求只有一个user,user特征一般是(1,N)大小的。user行为是实时变化的,一般user特征是实时获取的。
- item特征,item特征和商品(物料)数相关,单词请求对M个item预测,item特征的维度是(M,N)维度。item变化一般没那么实时,一般item属性是增量更新的。
- context特征,是随着输入而变化的Item特征。
- combo特征,是多个特征交叉产生的特征,可以是item与item交叉,也可以是user和item交叉。
- sequence特征,分为user序列和item序列。如user序列输入可以是一个用户感兴趣的item集合上的行为。item序列则可以是与该item相关的user集合的行为。
特征抽取
-
Tensorflow特征抽取整体上分为四大类方法:Bucketing(按照边界点分段)、Crossing(不同特征交叉)、Hashing(哈希分桶)、Embedding
-
阿里RTP特征生成 是和TF类似的思路实现。
-
自定义特征抽取:
特征抽取的结果只要符合模型输入的数值型要求,就可以任意定义特征抽取实现。
TF和RTP的特征抽取实现比较有通用型,算法同学几乎不用开发特征抽取逻辑,只需要专注特征构建、选择和模型设计即可。
自定义特征没有通用性,几百个模型会产生成千上万的特征。特征抽取类一般需要C++实现,让工程同学帮助实现具体特征抽取类不太现实,让算法同学手写C++多少有点勉为其难。
抽取加速
以上TF和阿里的通用特征抽取实现,因为抽取类是通用的,只需要确定数量的TF算子实现。通过特征配置,可以将每个特征拼接成图中的一个算子,通过TF图执行,自然实现并行加速(最慢的FeatOp和EmbLookupOp是性能瓶颈)。
对于计算慢的特征抽取节点可以通过Fused优化。该方式需要将特征原始字段按列存储(每个item特征算子是对某一个特征在item上抽取)。
如下图所示
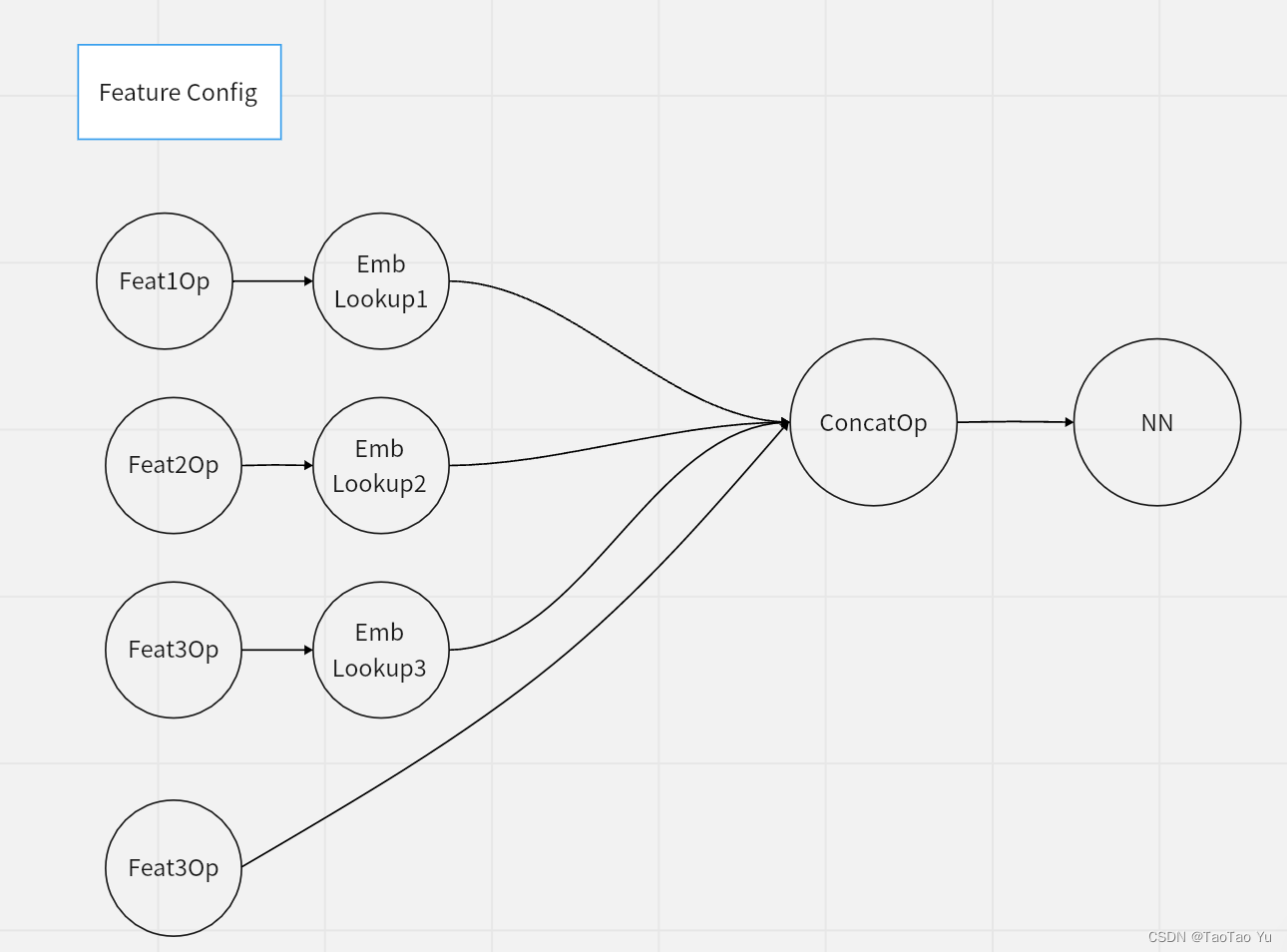
如果不太方便列存,
特征选择
特征重要性选择一般通过AutoML方式实现,是在训练阶段完成。AutoML除了可以进行特征重要性选择,还可以进行模型参数调节。可以参考AutoML综述、
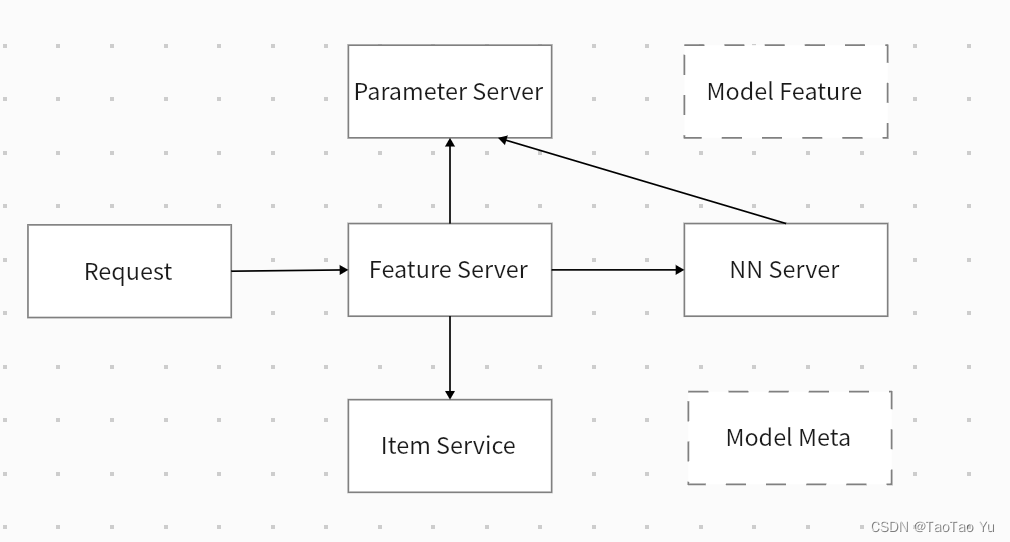
在线服务架构
全图化架构:将特征抽取、embedding查询、infer计算通过tf图拼接,组成分布式服务。

微服务架构:
参考资料
https://blog.51cto.com/u_15567091/5248722
https://blog.csdn.net/qq_19446965/article/details/107744850
https://baijiahao.baidu.com/s?id=1632931170015375330&wfr=spider&for=pc
https://developers.googleblog.com/2017/11/introducing-tensorflow-feature-columns.html

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









