







Author:baiyucraft
BLog: baiyucraft’s Home
原文:《动手学深度学习》
1.pandas
pytorch主要是对数据进行操作,那肯定得有软件读取文件中的数据然后对数据进行预处理得到我们想要操作的tensor,这就需要用到pandas了
2.创建和读入数据集
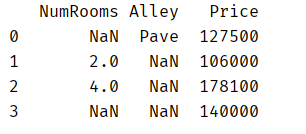
一般处理的数据都是csv(逗号分隔值)文件,首先,我们先创建一个人工数据集,该数据集有四行三列,其中房间数量NumRooms、巷子类型Alley、房屋价格Price:
import os
import pandas as pd
# 创建数据
os.makedirs(os.path.join('data'), exist_ok=True)
data_file = os.path.join('data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 读取数据 房间数量NumRooms、巷子类型Alley、房屋价格Price
data = pd.read_csv(data_file)
print(data)
运行结果:
3.处理缺失值
在上文的代码中我们可以看到该数据集是有缺失值的,NaN代表的就是缺失值,为了处理缺失的数据,典型的做法有差值和删除。一般我们考虑差值。
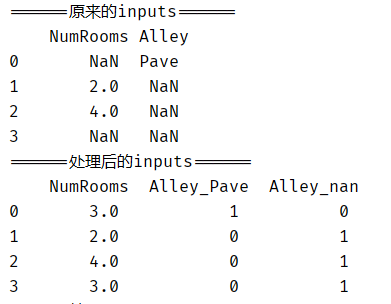
通过位置索引iloc,我们将data分成 inputs和outputs,其中前者为data的前两列,而后者为data的最后一列。
对于inputs中缺少的的数值NumRooms项,我们用同一列的均值替换 NaN项。
对于inputs中的Alley,因为是类别值,我们将NaN视为一个类别。由于Alley只接受两种类型的类别值Pave和NaN,pandas 可以自动将此列转换为两列Alley_Pave和Alley_nan。类型为Pave的行会将Alley_Pave = 1, Alley_nan = 0;反之Alley_Pave = 0, Alley_nan = 1。
# 处理缺失值
# 分为inputs和outputs
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
print('======原来的inputs======\n', inputs)
# 将数值类NaN取该列数据均值
inputs = inputs.fillna(inputs.mean())
# 将类型类NaN划分为0/1
inputs = pd.get_dummies(inputs, dummy_na=True)
print('======处理的inputs======\n', inputs)
执行结果:
4.转换为tensor
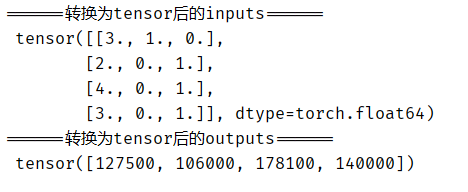
现在inputs和outputs都是数值类型,它们可以转换为张量格式:
# 转换为tensor
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print('======转换为tensor后的inputs======\n', X)
print('======转换为tensor后的outputs======\n', y)
执行结果:















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









