







常用预处理方法
1、零均值
零均值是数据预处理最为常用的方法。即将每一维原始数据减去这一维数据的均值,将结果替代原始的数据。预处理的结果是每一维数据的均值是0。
X -= np.mean(X,axis = 0)
2、归一化(normalization)
归一化就是将原始数据归一到相同的尺度,有两种归一化的方法:
1)先对每一维数据进行零均值,然后除以每一维数据的标准差。
X -= np.mean(X,axis = 0)
X /= np.std(X,axis = 0)
2)将不同维度的数据归一到相同的数值区间,如(-1, 1),(0, 255)。这种归一化仅仅当不同维的数据特征具有相同的重要性时采用,对于图片不需要采用这种归一化,因为图片像素的范围已经是归一化的了(0~255之间)。

3、PCA和白化
PCA作用:数据降维,加速机器学习进程。
步骤:
1)将数据进行零均值化。
2)计算数据的协方差矩阵得到数据不同维度之间的相关性。
X -= np.mean(X, axis = 0) # zero-center the data (important)
cov = np.dot(X.T, X) / X.shape[0] # get the data covariance matrix
注:实际上上面两步就是计算协方差的过程,即下式的代码实现:
Cov(Xi, Xj) = E{[Xi - E(Xi)][Xj - E(Xj)]}
得到的协方差矩阵如下图所示,其中对角线上的元素和等于那个向量自身的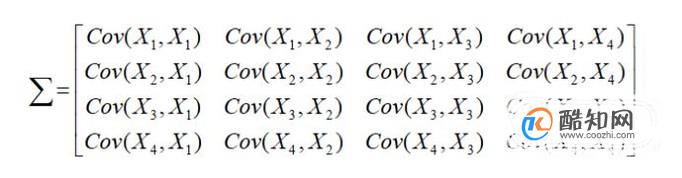
方差。如果协方差(元素)为正值,表明这两个特征之间的关系为正相关,如果为负值则为负相关,如果为0,则为不相关。协方差是对称并且半正定的。协方差矩阵经过变换可以得到一个完全不相关的矩阵,即主成分分析。
半正定矩阵定义:设A是n阶方阵,如果对任何非零向量X,都有X’AX≥0,其中X‘'表示X的转置,就称A为半正定矩阵。
正定矩阵:半正定矩阵中的X’AX≥0改为X’AX>0,即为正定矩阵。
3)对协方差矩阵进行奇异值分解(SVD分解),得到,U,Σ,V矩阵。
U,Σ,V = np.linalg.svd(cov)
注:其中,U和V均为单位正交阵,U为左奇异矩阵,,V成为右奇异矩阵,Σ仅在主对角线上有值,成为奇异值。奇异值分解主要用于数据压缩。
奇异值可以看做一个矩阵的代表值,或者说奇异值能够代表这个矩阵的信息,调用库函数进行奇异值分解得到的奇异值是按照从大到小排列的,奇异值越大时,它代表的信息越多,因此当我们取若干个最大的奇异值时,就可以基本还原出数据本身。

4)数据去相关。将零均值后的数据投影到特征向量上,选取前面几个特征向量来减少数据维度,这就是PCA降维。
Xrot = np.dot(X, U) # decorrelate the data,直接去相关性,或者进行下面的数据降维。
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced becomes [N x 100] ,PCA降维
注:U矩阵的列为特征向量,这些列都是相互正交的,故可看为基向量。这种投影相当于将数据X翻转、投影到新的基向量轴上。此时我们再计算Xrot的协方差矩阵时,会发现它是一个对角阵,说明不同维度之间不在相关。调用库函数计算的U的各列是跟Σ的奇异值(由大到小排列)一一对应的,故U中前面的列就是主方向,可以提取前面的列减少数据的维度。
白化
上述过程为PCA降维过程。所谓白化,只是比PCA更为高级的一个算法。白化分为PCA白化和ZCA白化。
白化作用:降低输入数据的冗余性,具体来说白化的目的:使得 1)特征之间具有弱相关性。2)所有特征具有相同的方差。
PCA白化步骤:
1)PCA处理求出特征向量,不降维。
2)把数据X映射到新的特征空间,实现去相关性。
3)对去相关的数据进行方差归一化(即除以方差)。
ZCA白化:在PCA白化的结果再变回原来的坐标系下的坐标。
注:PCA和白化在CNN中基本不会用到。
数据预处理参考链接:https://blog.csdn.net/coder_gray/article/details/79677921
协方差矩阵参考链接:http://www.coozhi.com/muyingjiaoyu/xuexijiaoliu/22246.html
奇异值分解参考链接:https://www.cnblogs.com/endlesscoding/p/10033527.html
白化参考链接:https://blog.csdn.net/liuweiyuxiang/article/details/88133096














 1799
1799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









