







AlexNet论文解读以Pytorch实现
日志:
2022.6.19:补充代码部分
作者是:加拿大多伦多大学 的 Alex Krizhevsky(第一作者)
下面给出论文
《ImageNet Classification with Deep ConvolutionalNeural Networks》
一、AlexNet背景
1、ILSVRC
在讨论AlexNet之前,首先要知道一个著名的竞赛,即ILSVRC(ImageNet Large Scale Visual Recognition Challenge)大规模图像识别挑战赛,是李飞飞等人于2010年创办的图像识别挑战赛,自2010年已经举办了8届。也是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一。
比赛项目涵盖:图像分类(lassification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。
竞赛中脱颖而出大量经典模型: alexnet, vgg, googlenet, resnet, densenet等
实际上ILSVRC数据集不等同于ImageNet数据集,而是从中挑选出来的。大规模的数据集为AlexNet成功大下了基础。

下面是ILSVRC的网址链接
ILSVRC网址
2、GPU
Alexnet的成功除了得益于大规模的数据集还得意于强大的计算资源即GPU
二、AlexNet研究成果及意义
1、研究成果
AlexNet在ILSVRC-2012以超出第二名10.9个百分点夺冠。下表是错误率
| Model | Top-1(val) | Top-5(val) | Top-5(test) | 注 |
|---|---|---|---|---|
| SIFT+FVs[7] | - | - | 26.2% | ILSVRC 2012分类任务第二名的结果 |
| 1 CNN | 40.7% | 18.2% | - | 训练一个AlexNet的结果 |
| 5 CNNs | 38.1% | 16.4% | 16.4% | 训练五个AlexNet取平均值结果 |
| 1 CNN* | 39.0% | 16.6% | - | 最后一个池化层后额外添加第六个卷积层并使用ImageNet 2011 (秋) 数据集预训练 |
| 7 CNNs* | 36.7% | 15.4% | 15.3% | 两个预训练微调,与5CNNs取平均值 |
2、研究意义
2012年之前分类任务大都采用机器学习方法即特征提取->特征筛选->输入分类机器。
2012年之后采用深度学习方法,即将特征工程与分类集于一体。
由此拉开了卷积神经网络统治计算机视觉的序幕,加速了计算机视觉应用的落地。
三、AlexNet网络结构
1、网络结构层的具体操作
下面是论文中作者的网络结构图

首先我们要知道AlexNet网络的一些基础:
1、由5层卷积层和3层全连接层网络构成。
2、由于算力限制,作者分两个GPU进行训练(图中上下代表两个GPU,第1层和第3层与前面所有信息进行连接,不过以现在的GPU算力用一块GPU也可以)
3、LRN(之后介绍)在第1个和第2个卷积层之后出现,不过之后有论文提出LRN所起的效果不明显,pytorch中将其去掉了。
4、pooling:第1、2、5个卷积层之后出现
5、ReLU:所有层都采用
6、Dropout:在前两层全连接层中使用
第一层操作:
conv1->ReLU->Pool->LRN
关于论文中作者输入图像大小是224*224说法上有一定问题,根据公式在没有padding的情况下,计算(224-11)/4+1=54与论文原图中的55不一致,若不加入padding输入大小应该为227 * 227,pytorch中导入的模型AlexNet网络将padding设置为了2.
第二层操作:
conv2->ReLU->Pool->LRN
第三层操作:
conv3->ReLU
这里实现了特征层的交互
第四层操作:
conv4->ReLU
第五层操作:
conv5->ReLU->Pool
第六层操作:
Dropout->Linear->ReLu
第七层操作:
Dropout->Linear->ReLu
第八层操作:
Linear
下面这张图是每层的尺寸计算,以及参数量大小,关于相关的一些计算之前的基础文章很详细的讲解了,这里不再过度强调。

2、具体操作
(1)激活函数
激活函数在我的这篇文章中提到过
卷积神经网络的深入理解-基础篇(卷积,激活,池化,误差反传)
论文中作者提到了两种饱和的激活函数sigmoid激活函数和tanh激活函数




认为饱和的激活函数梯度下降会比较慢,故采用了非饱和的激活函数,以加快梯度下降的速度。



上图是作者用四层网络做的一个实验,在错误率下降到0.25时采用非饱和激活函数ReLU比饱和激活函数tanh快了六倍。
(2)LRN(目前几乎不采用)
全称Local Response Normalization,局部响应标准化,其受启发于侧抑制(lateral inhibition):细胞分化变为不同时,它会对周围细胞产生抑制信号,阻止他们向相同方向分化,最终表现为细胞命运的不同
论文中采用LRN在top-1和top-5的错误率上分别下降了1.4%和1.2%。
公式如下:
b
x
,
y
i
=
a
x
,
y
i
/
(
k
+
α
∑
j
=
m
a
x
(
0
,
i
−
n
/
2
)
m
i
n
(
N
−
1
,
i
+
n
/
2
)
(
a
x
,
y
i
)
2
)
β
b_{x,y}^{i}=a_{x,y}^{i}/(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{i})^2)^{\beta }
bx,yi=ax,yi/(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yi)2)β
看着比较复杂,不过原理相对简单,
先来看下图,
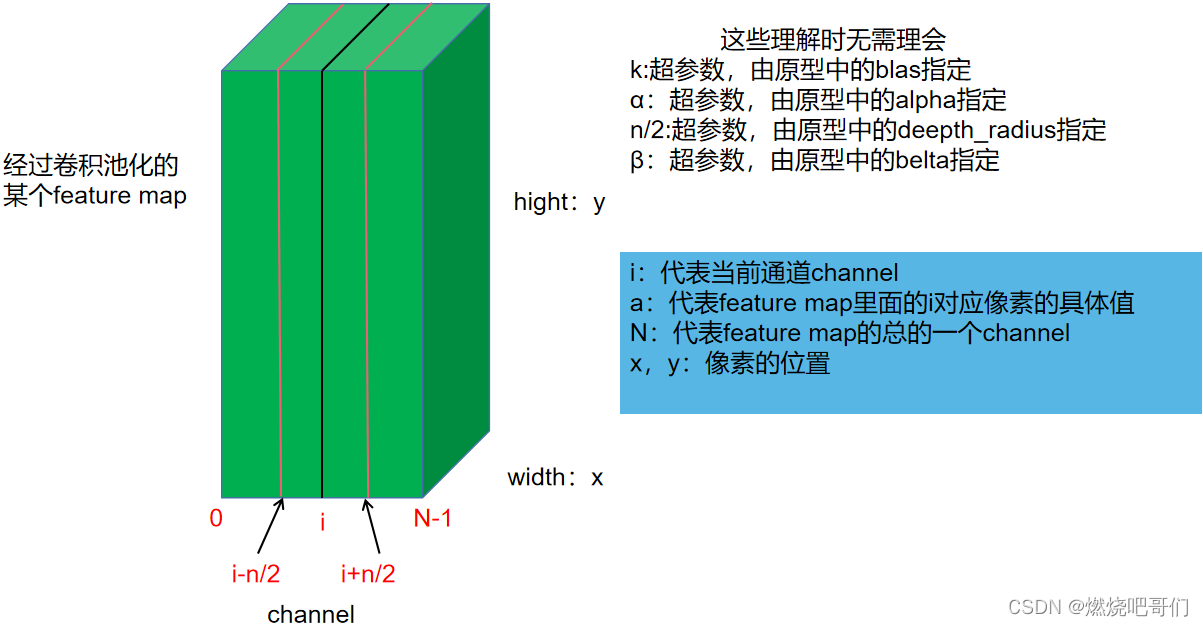
下图中假设当前位置的值为
a
x
,
y
i
a_{x,y}^{i}
ax,yi,那么根据LRN的原理,它必然受
i
i
i这个通道周围通道值得影响,假设
a
x
,
y
i
a_{x,y}^{i}
ax,yi受周围
n
/
2
n/2
n/2个通道的值的影响,那么显然
a
x
,
y
i
a_{x,y}^{i}
ax,yi周围的值越大经过LRN后得到的
b
x
,
y
i
b_{x,y}^{i}
bx,yi的值就应该越小
(
k
+
α
∑
j
=
m
a
x
(
0
,
i
−
n
/
2
)
m
i
n
(
N
−
1
,
i
+
n
/
2
)
(
a
x
,
y
i
)
2
)
β
就代表了周围的值,
(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{i})^2)^{\beta }就代表了周围的值,
(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yi)2)β就代表了周围的值,
a
x
,
y
i
表示原先的值
,
a_{x,y}^{i}表示原先的值,
ax,yi表示原先的值,
b
x
,
y
i
表示经过抑制的值
b_{x,y}^{i}表示经过抑制的值
bx,yi表示经过抑制的值
论文中采用LRN在top-1和top-5的错误率上分别下降了1.4%和1.2%。
(3)pooling(池化)
Overlapping Pooling(带重叠的池化),其实就是设置了步长的一个池化,之前的文章中我也具体介绍过,这里不再细讲。作者所采用的是核大小为3, 步长为2的一个池化,在top-1和 top-5的错误率上分别下降了0.4%和0.3%。
四、AlexNet训练技巧
1、Data Augmentation
论文中采用如下技巧
(1)针对位置
训练阶段:
1、图片统一缩放至256256
2、随机位置裁剪出224224区域(这里改为227*227)
3、随机进行水平翻转
测试阶段:
1、图片统一缩放至256256
2、裁剪出5个224224区域(这里改为227227)
3、均进行水平翻转,共得到10张224224图片(这里改为227*227)
(2)针对颜色
通过PCA方法修改RGB通道的像素值,实现颜色扰动,效果有限,仅在top-1提升1个点(top-1 acc约62.5%),PCA方法比较麻烦,现在使用也比较少。
2、Dropout
这里我在神经网络基础部分也详细介绍过,见下面链接卷积神经网络的深入理解-正则化方法篇
不再细说。随机的停止某些神经元的计算,训练的时候采用,测试的时候停止。
五、实验结果即分析
1、实验结果
| Model | Top-1(val) | Top-5(val) | Top-5(test) | 注 |
|---|---|---|---|---|
| SIFT+FVs[7] | - | - | 26.2% | ILSVRC 2012分类任务第二名的结果 |
| 1 CNN | 40.7% | 18.2% | - | 训练一个AlexNet的结果 |
| 5 CNNs | 38.1% | 16.4% | 16.4% | 训练五个AlexNet取平均值结果 |
| 1 CNN* | 39.0% | 16.6% | - | 最后一个池化层后额外添加第六个卷积层并使用ImageNet 2011 (秋) 数据集预训练 |
| 7 CNNs* | 36.7% | 15.4% | 15.3% | 两个预训练微调,与5CNNs取平均值 |
集成思想
2、卷积核可视化

如图所示这个是在输入图像224 * 224(这里改为227 * 227)也就是第一层进行11*11的一个卷积核的可视化,作者发现,训练过程中会出现这种现象,GPU1核学习到了包含频率和方向的特征,而GPU2核学习到了包含颜色的特征。
3、特征的相似性

相似图片第二个全连接层输出的特征向量的欧式距离相近。由此得到启发启发:可以用AlexNet提取高级特征进行图像检索、图像聚类、图像编码,这里其实已经有很多网络采用了这种思想,比如行人重识别。
六、结论
网络层之间是有一定相关性的,移除或是加入一层都会影响网络的性能。作者在论文中提到移除任何中间层都会引起网络损失大约2%的top-1性能。
七、代码实现(含具体讲解)
代码部分主要采用两种实现方式,第一种是调用pytorch中的alexnet网络并加载预训练模型进行实现(不要小看这种方式)。第二种自构建alexnet网络训练模型。
1、采用预训练模型进行
这部分花了我很长时间,有点繁琐,之后应该还会更改完善,那么我们开始吧。
(1)数据集以及处理
给出网盘地址:
链接:https://pan.baidu.com/s/1Pe5QNW-nltrf8qVboi1Yow?pwd=ld61
提取码:ld61
数据集采用猫狗数据集,直接从一个train文件中分割出训练集和验证集,这是train文件中的图片以及图片命名,

如下代码将数据集进行分割并存放于txt文件中,用于之后进行读取训练
import os
import random
# 用于产生txt文件,相当于dataset操作
def Data_division(data_path,save_txt_train_path,save_txt_eval_path):
lists = os.listdir(data_path)
for list in lists:
if list in ['train']:
datalist = []
datadir = os.path.join(os.path.abspath(data_path),list)
data = os.listdir(datadir)
for n in data:
if n.startswith('cat'):
datalist.append(os.path.join(datadir,n) + "\t" + str(0) + "\n")
elif n.startswith('dog'):
datalist.append(os.path.join(datadir,n) + "\t" + str(1) + "\n")
random.shuffle(datalist)
print("总数据集的个数:", len(datalist))
# 划分训练集验证集
train_list = []
eval_list = []
for i in range(int(len(datalist) * 0.9)):
train_list.append(datalist[i])
for i in range(int(len(datalist) * 0.9), len(datalist)):
eval_list.append(datalist[i])
print("训练数据个数:", len(train_list))
print("验证数据个数:", len(eval_list))
# 将数据路径存放于txt文件里
with open(save_txt_train_path, 'w', encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
f.close()
with open(save_txt_eval_path, 'w', encoding='UTF-8') as f:
for eval_img in eval_list:
f.write(eval_img)
f.close()
# 说明:这里将train中的猫狗图片分为训练集和测试集
if __name__ == '__main__':
Data_division('../data','../data/train.txt','../data/eval.txt')
txt文件保存格式如下:前者路径,后者类别

(2)dataset
这一步我们要将txt文件中的数据读取出来并进行数据增强,返回为分离的数据和标签。这里详细说明一下transform这一部分。将上面训练,测试的数据增广操作再写一遍
| 训练阶段 | 测试阶段 |
|---|---|
| 图片统一缩放至256*256 | 图片统一缩放至256*256 |
| 随机位置裁剪出224x224区域 | 裁剪出5个224x224区域,进行水平翻转得到10张224*224图片 |
| 随机进行水平翻转 |
这里我为什么改为224x224,而非上面的227x227呢,这是由于pytorch内置的网络更改了部分网络层中的padding,使得网络输入与论文中的输入一致。
| 训练阶段 | 测试阶段 |
|---|---|
| transforms.Resize((256,256)) | transforms.Resize((256, 256)) |
| transforms.CenterCrop(256) | |
| transforms.RandomCrop(224) | transforms.TenCrop(224, vertical_flip=False) |
| transforms.RandomHorizontalFlip(p=0.5) | |
| transforms.ToTensor() | transforms.ToTensor() |
| transforms.Normalize() | transforms.Normalize() |
| torch.stack() |
我们主要来看一下测试阶段的TenCrop操作,它的作用见我的这篇博客神经网络数据增强transforms的相关操作(持续更新),主要作用是裁剪图片中心和四个角并做翻转得到10张图片,操作后会出现这样一个问题,我们希望对图片处理后得到的是一张(b,c,h,w),但是经过TenCrop处理后得到的却是这样一个list[(b,c,h,w),(b,c,h,w)…(b,c,h,w)],因此需要用到torch.stack()这个操作扩展一维变成(b,10,c,h,w),
如下为代码部分:
# -*- coding: utf-8 -*-
import torch
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
class CatDogDataset(Dataset):
def __init__(self,txt_path,img_size,is_train=True):
self.imgs_info = self.Separate_data(txt_path)
self.img_size = img_size
self.is_train = is_train
self.train_transform = transforms.Compose([
transforms.Resize((256)),
transforms.CenterCrop(256),
transforms.RandomCrop(img_size),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
self.val_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
# transforms.Lambda()函数自行定义transform操作
transforms.Lambda(lambda crops: torch.stack([transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])(transforms.ToTensor()(crop)) for crop in crops])),
])
# 分离数据和标签[路径,标签]
def Separate_data(self,txt_path):
with open(txt_path,'r',encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split('\t'), imgs_info))
return imgs_info
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img = Image.open(img_path).convert('RGB')
if self.is_train:
image_datasets = self.train_transform(img)
else:
image_datasets = self.val_transform(img)
label = int(label)
return image_datasets,label
def __len__(self):
return len(self.imgs_info)
类中函数不太理解的看我这篇博客
卷积神经网络构建的python基础-详细理解(Pytorch)
最终的返回值如下:
| train | val |
|---|---|
| (图片(b,c,h,w),标签) | (图片(b,10,c,h,w),标签) |
图片维数不一样?先接着往下看,后面告知怎么处理。
(3)dataset封装
train_loader = DataLoader(dataset=train_datasets, batch_size=batch_size, shuffle=True, num_workers=0)
val_loader = DataLoader(dataset=val_datasets, batch_size = batch_size, num_workers=0)
(4)预训练模型搭建
数据准备好后我们就要开始搭建网络了,这一部分由于是调用pytorch内置的网络,因此比较简单,分为以下几步
(1)下载好AlexNet预训练模型,
(2)搭建网络,更改网络层(pytoch中alexnet网络所分类别是1000类,我们这里只分2类)
如下搭建网络代码:
import torchvision.models as models
alexnet_model = models.alexnet() # 网络
alexnet_model.load_state_dict(torch.load(path_state_dict)) #导入参数
下面是更改网络层代码
num_ftrs = alexnet_model.classifier._modules["6"].in_features
alexnet_model.classifier._modules["6"] = nn.Linear(num_ftrs, n_class)
实际上是将最后一层的全连接层输出只能1000改为2,即:
Linear(in_features=4096, out_features=1000, bias=True)
变为:
Linear(in_features=4096, out_features=2, bias=True)
判断GPU是否可用
if torch.cuda.is_available():
device = 'cuda'
else:
device = 'cpu'
alexnet_model.to(device)
(5)损失函数、优化器、学习率
这一部分重点主要是优化器,我们需要阻碍一下除全连接层外的所有参数更新。见如下代码,注意代码中的参数并没有完全冻结,想要完全冻结的可以将学习率置为0.
# 损失函数、优化器、学习率
criterion = nn.CrossEntropyLoss()
# 冻结卷积层
# flag = 0
flag = 1
if flag:
fc_params_id = list(map(id, alexnet_model.classifier.parameters())) # 返回的是parameters的内存地址
base_params = filter(lambda p: id(p) not in fc_params_id, alexnet_model.parameters()) # 除全连接层外的所有参数都冻结
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 并未完全冻结,只是默认momentum为0(相当于梯度下降),同时将学习率设置的很小,参数跟新微小
{'params': alexnet_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(alexnet_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
# 设置学习率下降策略
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 根据epoch调整学习率
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,patience=5) # 根据测试指标调整学习率
(6)训练及验证
这里不再详细讲解,大体在我的这篇博客卷积神经网络实战——表情识别(Pytorch)超详细理解,含Pyqt5的可操作界面。这里我主要解答一下
(2)dataset最后的那个问题
主要是在这一步的处理上
data = data.view(-1,c,h,w)
outputs = model(data) # torch.Size([240, 2])
outputs_avg = outputs.view(bs,ncrops,-1).mean(1)
# torch.Size([24, 10, 2]) torch.Size([24, 2])
将(b, 10,c,h,w)变为(b*10,c,h,w)相当于将batch扩大了10倍,输入网络得到预测概率(240, 2)进行分离(24, 10, 2)取平均(24,2)即可解决这一问题。
outputs_avg = outputs.view(bs,ncrops,-1).mean(1)
def train(train_loader,model,criterion,optimizer,device,train_len,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.train()
for i ,(data,target) in enumerate(train_loader): # enumerate:列举
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
outputs = model(data)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
num_corrects += torch.sum(preds==target).item()
num_loss = num_loss + loss.item()
train_loss = num_loss / (train_len//batch_size+1) # 每一个epoch的训练损失
train_acc = num_corrects / train_len # 每一个epoch的训练正确率
return train_loss,train_acc
def eval(val_loader,model,criterion,device,val_len,batch_size):
num_loss = 0.0
num_corrects = 0.0
model.eval() # 将模型转化到验证模式
with torch.no_grad(): # # 模型的参数都不会进行更新(把模型的参数固定下来)
for i ,(data,target) in enumerate(val_loader):
data = data.to(device) # torch.Size([24, 10, 3, 224, 224])
# 由于TenCrop操作会使得数据变成5维,而输入网络的数据格式要求是4维
bs,ncrops,c,h,w = data.size() # 24 10 3 224 224
data = data.view(-1,c,h,w) # 240 3 224 224
target = target.to(device)
outputs = model(data) # torch.Size([240, 2])
outputs_avg = outputs.view(bs,ncrops,-1).mean(1) # torch.Size([24, 10, 2]) torch.Size([24, 2])
_, preds = torch.max(outputs_avg.data, 1)
loss = criterion(outputs_avg, target)
num_corrects += torch.sum(preds == target).item()
num_loss = num_loss + loss.item()
val_loss = num_loss / (val_len//batch_size+1) # 每一个epoch的训练损失
val_acc = num_corrects / val_len # 每一个epoch的训练正确率
return val_loss,val_acc
训练和验证
from tensorboardX import SummaryWriter
import time
writer = SummaryWriter() # 用于生成可视化的图
best_acc = 0.0
for epoch in range(num_epoch):
start = time.time()
train_loss, train_acc = train(train_loader, alexnet_model, criterion, optimizer, device, train_len, batch_size)
scheduler.step() # 更新学习率
val_loss, val_acc = eval(val_loader, alexnet_model, criterion, device, val_len, batch_size)
# 保存最好的模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(alexnet_model.state_dict(), './best.pth')
writer.add_scalar('trainloss', train_loss, epoch)
writer.add_scalar('trainacc', train_acc, epoch)
writer.add_scalar('valloss', val_loss, epoch)
writer.add_scalar('valacc', val_acc, epoch)
end = time.time()
print('[{}/{}]: train_loss:{:.3f}, train_acc:{:.3f},eval_loss:{:.3f}, eval_acc:{:.3f}, time:{:.3f}'.format(
epoch + 1, num_epoch, train_loss, train_acc, val_loss, val_acc, end - start))
writer.close()
训练损失准确率的图就不贴了给一个网址训练测试准确率,损失函数图像,时间原因,这里我只训练了10轮。
(7)预训练模型识别
这里需要两个文件,一个json文件,一个txt文件。下面给出网盘链接:https://pan.baidu.com/s/1Q5t7dI0fg_yDgvrYZ8kuLg?pwd=p29g
提取码:p29g
如下预测代码:,
# -*- coding: utf-8 -*-
import os
# os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
import time
import json
import torch.nn as nn
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # 去掉文件名,返回目录
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def img_transform(img_rgb, transform=None): # 对图片进行transform操作
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def load_class_names(p_clsnames, p_clsnames_cn): # 加载标签名
with open(p_clsnames, "r") as f:
class_names = json.load(f) # 从json文件中读取数据
with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象
class_names_cn = f.readlines()
return class_names, class_names_cn
def get_model(path_state_dict, vis_model=False):
"""
创建模型,加载参数
:param path_state_dict:
:return:
"""
model = models.alexnet()
pretrained_state_dict = torch.load(path_state_dict)
model.load_state_dict(pretrained_state_dict)
model.eval()
if vis_model:
from torchsummary import summary
summary(model, input_size=(3, 224, 224), device="cpu")
model.to(device)
return model
def process_img(path_img):
# hard code
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# path --> img
img_rgb = Image.open(path_img).convert('RGB')
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # chw --> bchw
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
if __name__ == "__main__":
# config
path_state_dict = os.path.join(BASE_DIR, "..", "data", "alexnet-owt-4df8aa71.pth")
path_img = os.path.join(BASE_DIR, "..", "data", "Golden Retriever from baidu.jpg")
# path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "data", "imagenet_classnames.txt")
# load class names
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
# 1/5 load img
img_tensor, img_rgb = process_img(path_img)
# 2/5 load model
alexnet_model = get_model(path_state_dict, True)
# 3/5 inference tensor --> vector
with torch.no_grad():
time_tic = time.time()
outputs = alexnet_model(img_tensor)
time_toc = time.time()
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1)
print(pred_int)
_, top5_idx = torch.topk(outputs.data, 5, dim=1)
pred_idx = int(pred_int.cpu().numpy())
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx]
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming:{:.2f}s".format(time_toc - time_tic))
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()
结果:top1-5是指概率最大的前五个预测类别

可以从网上下载其他图片试试。
(8)pyqt5可视化界面识别(预训练模型)
这里我并没有使用训练的那个猫狗识别模型,当然也可以使用。
import os
from PyQt5.QtWidgets import (QGridLayout, QPushButton, QLabel)
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
import sys
from PyQt5.QtCore import Qt
# 预测脚本
import torch
import torchvision.transforms as transforms
from PIL import Image
import torchvision.models as models
import numpy as np
import json
path_state_dict = os.path.join("data", "alexnet-owt-4df8aa71.pth")
path_classnames = os.path.join("data", "imagenet1000.json")
def predict(img):
# 数据
data_tranform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
img = data_tranform(img) # 数据预处理
img = torch.unsqueeze(img, dim=0) # 数据维数扩充,前面一维为batch
# 网络模型
device = torch.device('cpu')
model = models.alexnet()
model.load_state_dict(torch.load(path_state_dict))
model.eval()
model.to(device)
# 标签读取
with open(path_classnames, "r") as f:
class_names = json.load(f) # 从json文件中读取数据
# 输入网络输出结果
with torch.no_grad():
outputs = model(img)
outputs = torch.squeeze(outputs) # 去除batch
outputs = torch.softmax(outputs, dim=0) # 经过激活函数变为各个标签的概率
pro, preds = torch.max(outputs, 0) # 得到最大概率的标签索引
pro = pro.data.item()
pred = class_names[preds.item()]
return pred,str(pro) # 返回预测结果,和预测概率
class Ui_example(QWidget):
def __init__(self):
super().__init__()
self.window_pale = QPalette() #窗口背景
self.layout = QGridLayout(self)
self.label_image = QLabel(self) #图像显示
self.label_predict_result = QLabel('识别结果', self)
self.label_predict_result_display = QLabel(self)
self.label_predict_acc = QLabel('识别准确率', self)
self.label_predict_acc_display = QLabel(self)
self.button_search_image = QPushButton('选择图片',self)
self.button_run = QPushButton('识别表情',self)
self.setLayout(self.layout)
self.initUi()
def initUi(self):
self.layout.addWidget(self.label_image,1,1,3,2) #,1.5,1,3,2 #图像位置
self.layout.addWidget(self.button_search_image,1,3,1,2) #,1,3,1,2 #"选择图片"按钮位置
self.layout.addWidget(self.button_run,3,3,1,2) #,3,3,1,2 #"识别表情"位置
self.layout.addWidget(self.label_predict_result, 4, 3, 1, 1) # "识别结果"位置
self.layout.addWidget(self.label_predict_result_display, 4, 4, 1, 1) # 识别结果
self.layout.addWidget(self.label_predict_acc, 5, 3, 1, 1) # "识别准确率"位置
self.layout.addWidget(self.label_predict_acc_display, 5, 4, 1, 1) # 识别准确率
self.button_search_image.clicked.connect(self.openimage)
self.button_run.clicked.connect(self.run)
self.setGeometry(500,500,500,500)
self.setWindowTitle('识别')
self.window_pale.setBrush(QPalette.Background, QBrush(QPixmap("./win.jpg"))) # 背景图片
self.setPalette(self.window_pale)
self.show()
def openimage(self):
global fname
imgName, imgType = QFileDialog.getOpenFileName(self, "选择图片", "", "*.jpg;;*.png;;All Files(*)")
jpg = QPixmap(imgName).scaled(self.label_image.width(), self.label_image.height(), Qt.KeepAspectRatio,Qt.SmoothTransformation)
self.label_image.setPixmap(jpg)
fname = imgName
def run(self):
global fname
file_name = str(fname)
img = Image.open(file_name)
pred, pro = predict(img)
self.label_predict_result_display.setText(pred)
self.label_predict_acc_display.setText(pro)
if __name__ == '__main__':
'''
app.exec_()其实就是QApplication的方法,
这个exec_()方法的作用是“进入程序的主循环直到exit()被调用”
'''
app = QApplication(sys.argv)
ex = Ui_example()
sys.exit(app.exec_())
结果:

八、卷积核,特征图可视化
这一部分给出我的这篇博客,上面具体实现了卷积核,特征图可视化。卷积核,特征图可视化
最后有不足之处还望指出,希望可以获得朋友的一个赞















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









