







卷积神经网络的深入理解-正则化方法篇
正则化方法(持续补充)
为防止网络模型出现过拟合这种情况,网络训练中引入了正则化方法。
一、显式正则化方法
包含对网络结构、损失函数的修改,模型使用方法的调整
1、模型集成
模型集成包含两部分:
1、训练多个模型进行结果融合;
2、多次使用不同的数据(训练集测试集选择)训练模型进行结果融合。
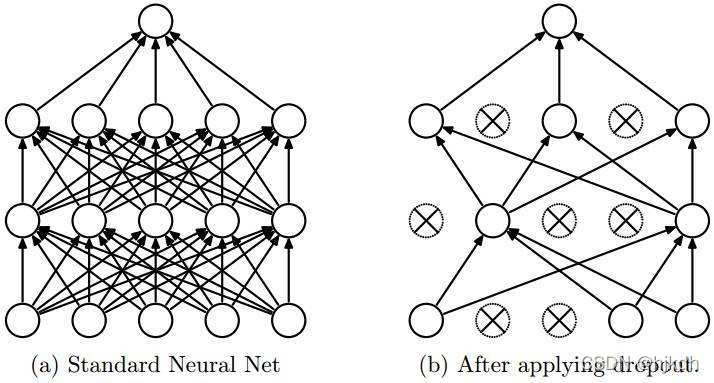
2、Dropout技术(神经元)
训练时按概率p随机丢弃部分节点,测试时不丢弃,输出结果乘以p(乘以p这里不太理解后续看源码时进行补充)左边全连接,右边dropout
3、参数正则化方法
直接更改优化目标即更改损失函数,简单有以下两种
1、L1正则化:

2、L2正则化:
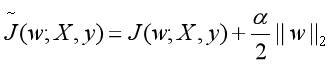
此时损失函数由两项组成,前一项为原来的损失函数,后一项为正则化项,L1与L2不同的是:
L1正则化是指权值向量w中各个元素的绝对值之和
L2正则化是指权值向量w中各个元素的平方和然后再求平方根
α:由用户指定,越大图形离原点越近,越小图形离原点越远。
下面两幅图左边是L1正则化,右边是L2正则化。参数空间(w1,w2)是一个二维平面,黑色的方形和圆形是正则化项记为L,彩色的是J的等值线
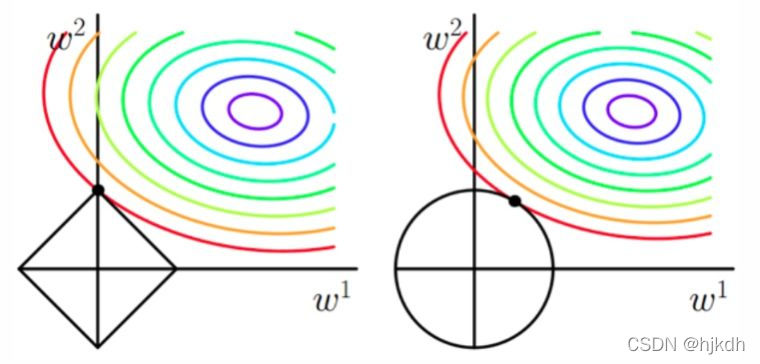
图中左侧,J等值线与L图形相交的地方(0,w)就是最优解,能够想象的是因L有很多突角,J与这些角接触的机率大于其它部分,这些角上许多权值等于0,因此L1正则化可以产生稀疏矩阵,进而可用于特征选择。
图中右侧,L图形相比左侧被磨去了棱角,使得(w1,w2)为(0,0)的概率就小了很多,因此L2不具有稀疏性,只能是类似稀疏性。
二、隐式正则化方法
没有直接对模型进行正则化约束,但间接获取更好的泛化能力。
1、数据标准化,平滑优化目标函数曲面;
2、数据增强,扩大数据集规模;
3、随机梯度下降算法

















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









