







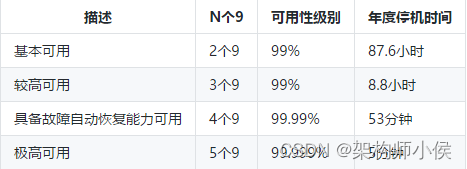
服务稳定是一个特别大的话题,一般我们用SLA描述服务的质量
SLA一般有99.9 ,99.99,就是我们常说的三个9,四个9
有两个纬度衡量
时间纬度
请求纬度
请求的成功率计算方式:SL A= 成功请求/(成功请求+请求失败)
我们可以任选一个纬度进行衡量
解决方案
预案演练
任何系统离不开人工的测试,演练,充分的预案演练可以避免大多数问题,如果人工监控无法覆盖到的,就可以采取下面的工具监控告警。
比较实际的方法就是
1、每天人工去访问系统的核心功能
2、演示之前做好排练和实时人工监控
3、定期做全功能测试
监控告警
资源监控
对CPU、内存等信息进行实时监控
使用K8s官方工具Kubnates 的 node-exporter、Prometheus 插件做服务器资源监控和告警
服务监控
使用Spring boot Admin 做微服务之间的服务状态监控
使用zipkin 做微服务链路跟踪监控
主动接口监控
使用猫头鹰做静态代码 安全扫描
使用啄木鸟做动态接口 安全扫描
定期使用 使用MeterSphere 做动态接口 性能扫描
缺点是并非是实时监控,无法体现出系统接口真实请求情况
被动接口监控
我们可以在微服务网关处加监控,对每次请求累加,并记录状态,最后使用公式计算
请求的成功率计算方式:SL A= 成功请求/(成功请求+请求失败)
缺点是,没访问到的接口如果出故障了无法感知
以上监控方式需要一起使用,才能达到一个比较全面的监控告警效果。
监控纬度
服务监控主要有三个纬度:主流metric 、trace、logging框架
日志监控:
Elastic,在上面基于指标监控的部分已经提到了它,其实由于采集数据的 Beats 下有一款 FileBeat 专门采集日志文件,然后把采集的日志存储到 ElasticSearch,接下来用 Kibana 进行分析展示
也就是常说的ELK
链路监控:
追踪系统,也有人叫调用链系统,做应用性能监控(APM)这块是必不可少的。
一次服务调用,中间经过了哪些环节,一次服务调用过程中各个环节的耗时
指标监控:
CPU 使用率、系统负载;如果你想知道应用在某段时间内的 HTTP 请求访问量; MySQL 的连接数、QPS等
高可用架构
服务高可用
微服务本身就是一种高可用的架构
1、服务治理、Hystrix做资源隔离以及熔断和服务降级
2、服务冗余(集群)
3、数据主从复制/分片
4、削峰限流
5、负载均衡
系统容灾
主要系统和备份的次要系统部署在不同地区,出现故障可以切换
服务发布
灰度发布:先发布10%,没问题再全部发布
到滚动发布:每次10%逐步发布
到蓝绿发布:节点集群,ingress切换请求流量
















 1561
1561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











