






1. 任务依赖需求描述:
例子:
一个作业分为如下子任务:
任务1,任务2,任务3,任务4
执行的顺序为,任务1---》任务2,任务3---》任务4
其中任务2,任务3可以并行执行,我们用下图描述:
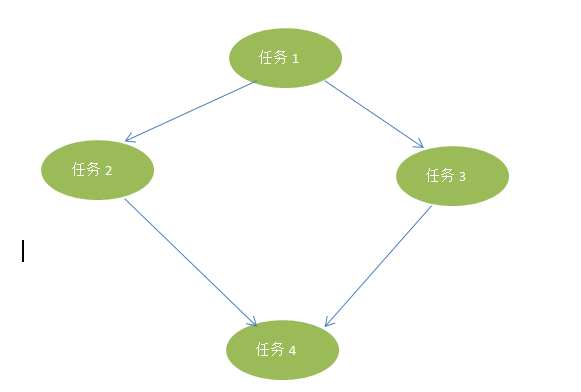
这是一个图形结构,我们预设,任务的起始点永远都是一个根节点,不管你业务如何,遵从这个设计是没有难度的,以后的流程,可以并行,也可以串行,任何一个阶段,都能支持并行和串行,因此,我们的子任务关系构成的数据结构为一个图。
2. 任务调度简单流程
- 首先定义一个job代表一次业务的调度,job维护了任务1到任务4之间的关系。
- 找到job的根节点任务1,先执行任务1,因为是根节点,没有父类,因此没有先决条件,任务被调度时,即可执行。
- 执行完根节点之后,看该节点是否有子节点,没有则不继续,有则并行执行所有子节点的任务。
- 此时任务2和任务3会被并行调用,我们假设调用指令先到任务2,任务2发现有1个父节点,且调用指令中表示父节点已经执行完成,那么就开始执行任务2的调度,同理任务3也是同样的逻辑。
- 任务2和任务3执行完成之后,会先后或者同时调用任务4,我们这里为了避免同时并发造成的困扰,任务被调用这个方法要设置成同步,那么假设任务2先调用任务4,此时我们在内存中记录任务2已完成,并且任务4发现自己的2个父节点中,任务3的指令并没有来到,因此,此次调度跳过,等待任务3指令的到来。
- 当任务3的指令到来,我们根据jobid,找到之前暂停的job,此时发现任务2,3都执行完成,那么开始执行任务4,本次业务调度完成。
3. 数据结构java类描述
//jobConfig 及其子任务的依赖关系描述
public class JobConfig {
private Long id; //id
private TaskConfig task; //子任务根节点
private String corn; //corn表达式
}
// TaskConfig 描述子任务之间的依赖关系
public class TaskConfig {
Long id;
String name; //任务名称
private Long jobId; //jobid
private String target; //目标任务
List<TaskConfig> parent; //父节点
List<TaskConfig> child; //子节点
}
//job类,描述每次任务调度的job
public class Job {
Long id;
JobConfig jobConfig; //所属job_config
int status; //执行状态
}
//task类,描述每次任务调度的task
public class Task {
Long id;
TaskConfig taskConfig; //所属task_config
Job job; //所属job
int status; //执行状态
//父task
List<Task> parentList;
}
4. 表结构描述
我们需要定义一些表来描述作业子任务之间的静态关系
和执行时的任务状态动态关系
/*
job_config表
用来描述job及其子任务的静态关系
*/
create table job_config(
id,
root_task_id --任务根节点
corn --corn表达式
);
/*
task_config表,描述job下的子任务之间的静态依赖关系
属于job_config表的子表
*/
create table task_config(
id, --id
name, --任务名称
parent_id --父节点,多个用逗号隔开
child_id --子节点,多个用逗号隔开
job_id --所属的job_id
target --目标任务
)
/*
job执行状态表
*/
create table job(
id,
job_config_id, -- 所属job_config
status, -- 执行状态
);
/*
task 执行状态表
job 的子表
*/
create table task(
id,
task_config_id, -- 所属task_config
job_id, -- 所属job
status, -- 执行状态
);
5. 伪代码描述job执行流程
捞取所有job_config表记录,根据corn去触发定时任务
事先构造job_config及其子任务之间的关系,从数据库中根据job_id捞取出
所有的task_config,然后根据其child,parent等构造一个关系对象
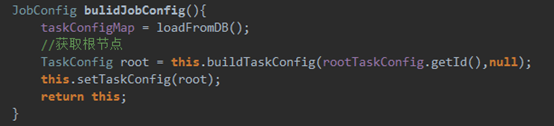
JobConfig jobConfig = buildJobConfig();
Job job =buildJob(); //包含持久化job
job.setJobConfig(jobConfig);
job.execute();
job.execute()方法详细代码:
//执行任务
public void execute(){
//构造task树,描述task及其子task的关系
//并持久化到数据库中
Task root = buildRootTask();
root.execute();
}
//task.execute 方法
public void execute(){
String target = taskConfig.getTarget();
//是否能执行,要判断先决条件,如果父节点未全部执行完,则跳过此次执行
if(this.canRun()){
boolean success = callTargetTask(target);
if(success){
//更新状态为成功
this.updateStatusToSuccess();
}else{
//更新状态为失败
this.updateStatusToFailed();
}
}
if(childList.size()>0){
//递归执行子任务
for(Task task : childList){
task.execute();
}
}
}
private boolean canRun(){
for(Task task : parentList){
if(!task.isFinished()){
return false;
}
}
return true;
}
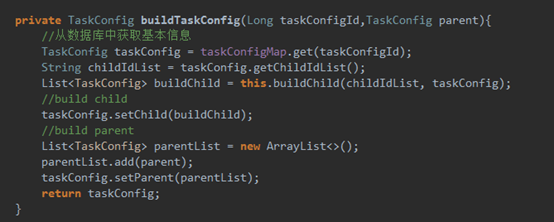
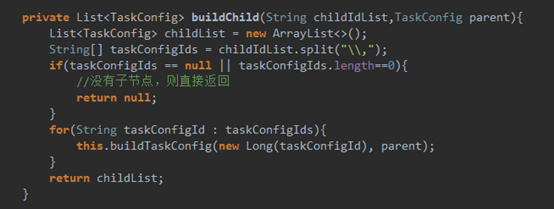
Buildjobconfig代码:
6.任务失败重试设计
待续
分布式任务系统
任务调度系统,和任务执行系统应该分开部署
任务执行系统可以部署多台。调度系统也可以部署多台。
任务调度系统在callTargetTask的时候,用远程调用的形式,这样可以尽可能的提高并发的性能
和系统稳定性。














 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









