







0、论文信息
Conference: WWW ’22, April 25–29, 2022
Author: Yue He1∗, Zimu Wang1∗, Peng Cui1†, Hao Zou1, Yafeng Zhang2, Qiang Cui2, Yong Jiang1
Link: 论文PDF下载地址
Code: 代码下载地址
【目的】解决推荐系统中训练集和测试集之间数据分布不一致(OOD)问题。
【挑战】1. 对于用户不喜欢的物品的分布是否发生偏移是未知的;2. 新用户和新物品。
【方法】通过学习不变的用户偏好,进行负采样并构建稳定的推荐系统框架——CausPref。
【结果】对真实数据集重新构造,使得训练集和测试集之间存在OOD问题。通过实验验证了 CausPref 方法的有效性、鲁棒性和可解释性。
1、背景介绍
传统的推荐算法都有一个共同的目标:拟合历史交互数据,但这需要满足一个前提假设:训练集和测试集的数据是独立同分布的(I.I.D.)。但本文认为大多数推荐系统中的数据是会随时间发生偏移的。
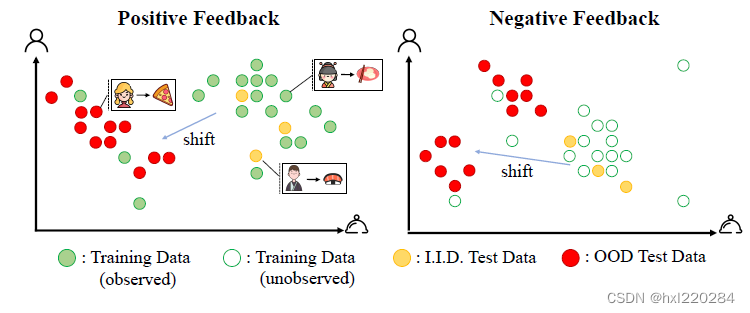
本文认为推荐系统数据中的偏移可分为两类:1)自然偏移;2)人为偏移。
1)自然偏移
举个例子,中国人喜欢吃中式早餐,欧洲、美洲人喜欢吃西式早餐。训练集中大多是中国人-中式早餐的数据,而测试集却主要预测欧洲人-西式早餐,这种就是自然偏移。

2)人为偏移
现阶段,推荐系统中数据的人为偏移问题是研究比较多的一个方向,常见的人为偏移有:选择偏差、位置偏差、流行度偏差、曝光偏差、公平性。举个流行度偏差的例子,假设系统中只有“流行音乐”和“民谣”两种物品,一开始有70%的流行音乐被交互过,30%的民谣被交互过。将这批交互数据放入推荐系统中训练,之后向用户推荐一批物品,有80%的概率流行音乐被推荐,民谣只有20%的被推荐机会。由于推荐系统是一个循环系统,周而复始会导致流行的物品越流行,而不流行(不论质量高低与否)的物品都会被很少推荐,这就会造成流行度偏移。

2、方法
由于数据中存在各种偏差,有些偏差是可以人为观测到并消除的,但有些偏差是未知的。本文就是要设计一个稳定的推荐框架,来解决上述所有偏差问题。
2.1 泛化的理论思考
首先文章提出了一个分布外隐式推荐的问题,也就是说用户和物品的联合概率分布不相等:
P
(
U
,
V
)
≠
P
∗
(
U
,
V
)
P(U,V)\neq P^*(U,V)
P(U,V)=P∗(U,V) 。

另外提出了一个不变性假设:即使用户和物品的联合概率分布随环境发生变化,用户物品的交互机制是不会随环境发生变化的,也就是说用户对给定物品的喜好是不会随环境变化的,中国人喜欢吃中式早餐,那他就一直喜欢吃中式早餐。
【个人认为,这个假设是比较强的,但文章后面的分析都基于此。】

由于
P
(
Y
∣
U
,
V
)
P(Y|U,V)
P(Y∣U,V) 是不变的,那后面将对该式子进行重点分析。首先基于贝叶斯定理该式可分解为:
P
(
Y
=
1
∣
U
,
V
)
=
P
(
U
,
V
∣
Y
=
1
)
⋅
P
(
Y
=
1
)
P
(
U
,
V
∣
Y
=
1
)
⋅
P
(
Y
=
1
)
+
P
(
U
,
V
∣
Y
=
0
)
⋅
P
(
Y
=
0
)
P(Y=1|U,V)=\frac{P(U,V|Y=1)\cdot P(Y=1)}{P(U,V|Y=1)\cdot P(Y=1)+P(U,V|Y=0)\cdot P(Y=0)}
P(Y=1∣U,V)=P(U,V∣Y=1)⋅P(Y=1)+P(U,V∣Y=0)⋅P(Y=0)P(U,V∣Y=1)⋅P(Y=1) 。
将该式上下同除:
P
(
U
∣
Y
=
1
)
⋅
P
(
Y
=
1
)
P(U|Y=1)\cdot P(Y=1)
P(U∣Y=1)⋅P(Y=1) ,得:
P
(
Y
=
1
∣
U
,
V
)
=
P
(
V
∣
U
,
Y
=
1
)
P
(
V
∣
U
,
Y
=
1
)
+
P
(
V
∣
U
,
Y
=
0
)
⋅
P
(
U
∣
Y
=
0
)
⋅
P
(
Y
=
0
)
P
(
U
∣
Y
=
1
)
⋅
P
(
Y
=
1
)
P(Y=1|U,V)=\frac{P(V|U,Y=1)}{P(V|U,Y=1)+\frac{P(V|U,Y=0)\cdot P(U|Y=0)\cdot P(Y=0)}{P(U|Y=1)\cdot P(Y=1)}}
P(Y=1∣U,V)=P(V∣U,Y=1)+P(U∣Y=1)⋅P(Y=1)P(V∣U,Y=0)⋅P(U∣Y=0)⋅P(Y=0)P(V∣U,Y=1)
为了化简上式,本文提出了第二个假设:假设用户的喜好不会随环境发生变化,并且用户不喜欢物品的分布可以由喜欢物品的分布决定。
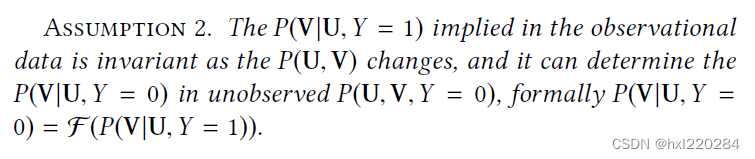
基于假设2,上式可化简为:
P ( Y = 1 ∣ U , V ) = P ( V ∣ U , Y = 1 ) P ( V ∣ U , Y = 1 ) + C ⋅ F ( P ( V ∣ U , Y = 1 ) ) ( 1 ) P(Y=1|U,V)=\frac{P(V|U,Y=1)}{P(V|U,Y=1)+\mathcal{C}\cdot \mathcal{F}(P(V|U,Y=1))} \quad (1) P(Y=1∣U,V)=P(V∣U,Y=1)+C⋅F(P(V∣U,Y=1))P(V∣U,Y=1)(1)
其中
C
=
P
(
Y
=
0
)
P
(
Y
=
1
)
\mathcal{C}=\frac{P(Y=0)}{P(Y=1)}
C=P(Y=1)P(Y=0) ,并且
P
(
U
∣
Y
=
0
)
P(U|Y=0)
P(U∣Y=0) 的分布是由
P
(
U
∣
Y
=
1
)
P(U|Y=1)
P(U∣Y=1) 决定的。
【个人对于
P
(
U
∣
Y
=
0
)
=
P
(
U
∣
Y
=
1
)
P(U|Y=0)=P(U|Y=1)
P(U∣Y=0)=P(U∣Y=1) 还是存在疑惑,文中对这两个概率公式的描述并不多,最后呈现的结果就是这两个概率公式约掉了。个人人为可能是用户的分布不受整体的喜好影响??】
基于公式(1),可以指导我们构建稳定的推荐系统:
- 从观测数据中估计不变的用户偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1) ;
- 从正采样和负采样中估计目标 P ( Y = 1 ∣ U , V ) P(Y=1|U,V) P(Y=1∣U,V) ,负采样是基于不变的用户偏好和设计的策略得到的。
2.2 算法:不变偏好学习
这里我们借助因果图来学习用户偏好的不变性,要学习推荐场景下的因果图,需要满足两个限制:

第一个限制是只有从用户特征到物品特征的路径,第二个限制是物品特征不能作为根节点,必须有其他用户/物品特征节点指向它。值得注意的是,这里的节点和以往推荐系统因果图的节点定义不用,以往的节点都是定义为一个用户/物品,而这里的节点是定义为用户/物品的某个特征。并且这两个限制并没有理论的证明,更多是一种启发式的限制,目的就是减小因果图的搜索空间。
基于以上两个限制,下面来学习用户偏好的因果结构:
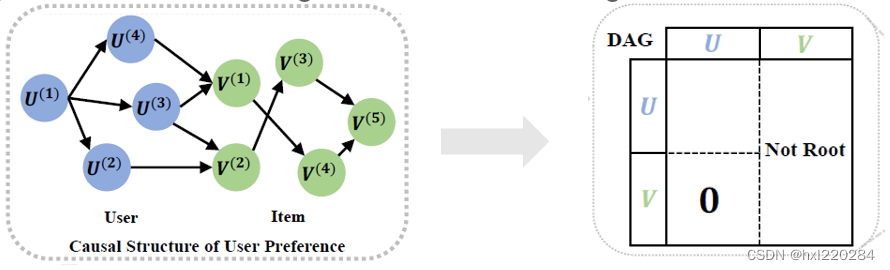
这里的因果图是等价于右边的连接矩阵的。限制一对应的是连接矩阵左下方值全为0,因为没有物品特征指向用户特征的路径;限制二对应的是连接矩阵右边每一列中的元素不全为0。
下面就正式利用神经网络来学习这个因果图,并学得用户的兴趣。
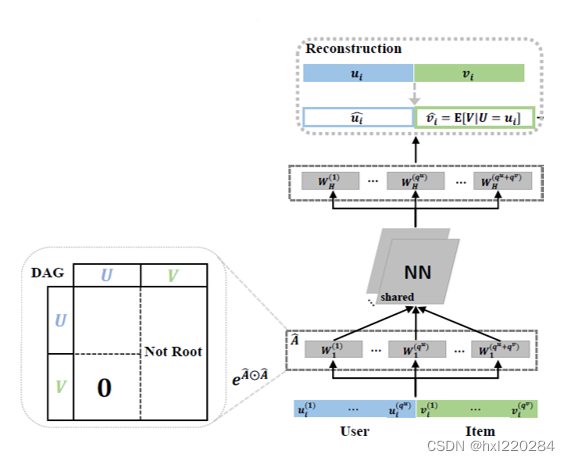
在这之前文中给出了一个引理,虽然看起来很复杂,但主要是为了说明文中学得的因果图是接近真实因果图的,也就是说我们可以通过学习这样一个因果图来学得不变的用户偏好。
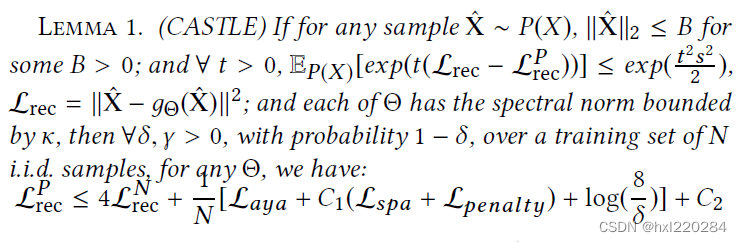
第一步是进行可微分的因果发现,与传统的利用条件独立性等直接给出因果图不同,这里的因果图是通过神经网络训练出来的。
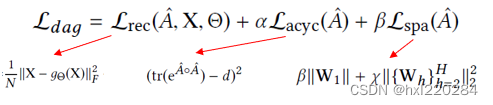
其中第一项
L
r
e
c
\mathcal{L}_{rec}
Lrec 是主要要学习的,其中
g
Θ
(
X
)
g_{\Theta}(X)
gΘ(X) 是重构后的向量,是可以学到不变的用户偏好的,这里需要保证原始向量
X
X
X 和重构后的向量
g
Θ
(
X
)
g_{\Theta}(X)
gΘ(X) 尽量接近,不要有太多信息损失;第二项
L
a
c
y
c
\mathcal{L}_{acyc}
Lacyc 是为了保证学出来的图是无环的;第三项
L
s
p
a
\mathcal{L}_{spa}
Lspa 是为了保证矩阵的稀疏;最后一项就是常规的L2正则项,保证模型的泛化性。
第二步是要学习推荐系统中的因果发现,也就是在前面的基础上,加上对两个限制的学习:
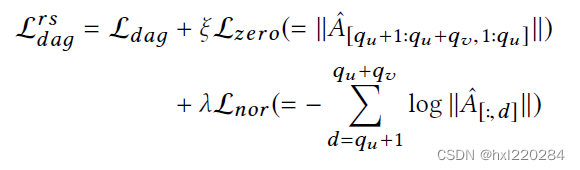
其中 L z e r o \mathcal{L}_{zero} Lzero 是对限制一的学习, L n o r \mathcal{L}_{nor} Lnor 是对限制二的学习。
2.3 协同因果过滤
通过网络1我们学习到了不变的用户偏好,下面通过网络2来学习用户对物品的点击概率。
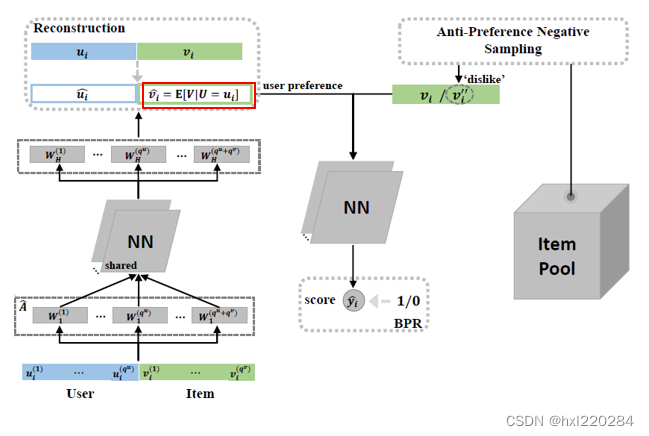
首先通过设计的负采样策略,采样用户不喜欢的物品。传统的负采样都是从用户未交互过的物品中采样一个物品作为负采样的结果,但我们都知道,在隐式反馈中用户未交互过的物品未必是用户不喜欢的,可能只是该物品未曝光给用户但用户是喜欢的。本文提出了APS的算法,通过学习到的用户偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1) 来找到用户最不喜欢的物品:

APS算法其实很简单,先通过网络1计算出用户偏好的期望
E
(
V
∣
U
=
u
i
,
Y
=
1
)
E(V|U=u_i,Y=1)
E(V∣U=ui,Y=1) ,然后从物品池中随机选取
K
K
K 个物品,分别计算用户偏好和这
K
K
K 个物品的相似度,选出相似度最小的物品
v
i
′
′
v_i^{''}
vi′′ 作为负采样的物品。
负采样结束后,我们得到一个三元组
(
g
Θ
(
u
i
)
,
v
i
,
v
i
′
′
)
(g_{\Theta}(u_i), v_i, v_i^{''})
(gΘ(ui),vi,vi′′) ,利用NeuMF模型和BPR损失函数来训练。
结合两个网络,得到最终版的损失函数:
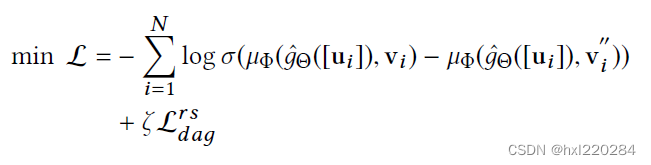
到这里方法就全部介绍完了,下面介绍实验部分。
3、实验
3.1 实验设置
本文的实验是在真实数据集的基础上进行了人为的构造,使得训练集和测试集存在OOD问题。具体构造的OOD问题有以下5种:

对比方法如下,主要对比的是NeuMF方法,Linear表示的是MF(内积形式)模型,non-Linear表示的是NeurMF(向量连接后输入到神经网络中)模型:

3.2 实验:公开的 Customer-To-Customer 数据集

从图中可以得到两个结论:
Inductive learning (User Degree Bias和Item Degree Bias)是比较难学习的。需要从训练集中学习到一般的信息。(Transductive learning 训练集中含有测试集中的信息。)
CausPref & CausPref-Linear 方法的推荐性能是最优的。
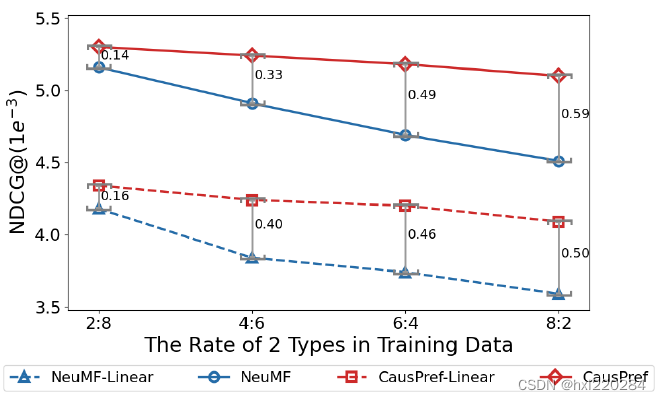
上图是在测试集上用户二元特征比例为2:8,训练集上用户二元特征比例从2:8一直变换到8:2,这个过程也是OOD问题越严重的过程。由上图会发现OOD问题越明显,CausPref方法的性能优势越显著。验证了CausPref方法更加鲁棒和稳定。
3.3 实验:大规模 Business-To-Customer 电子商务数据集
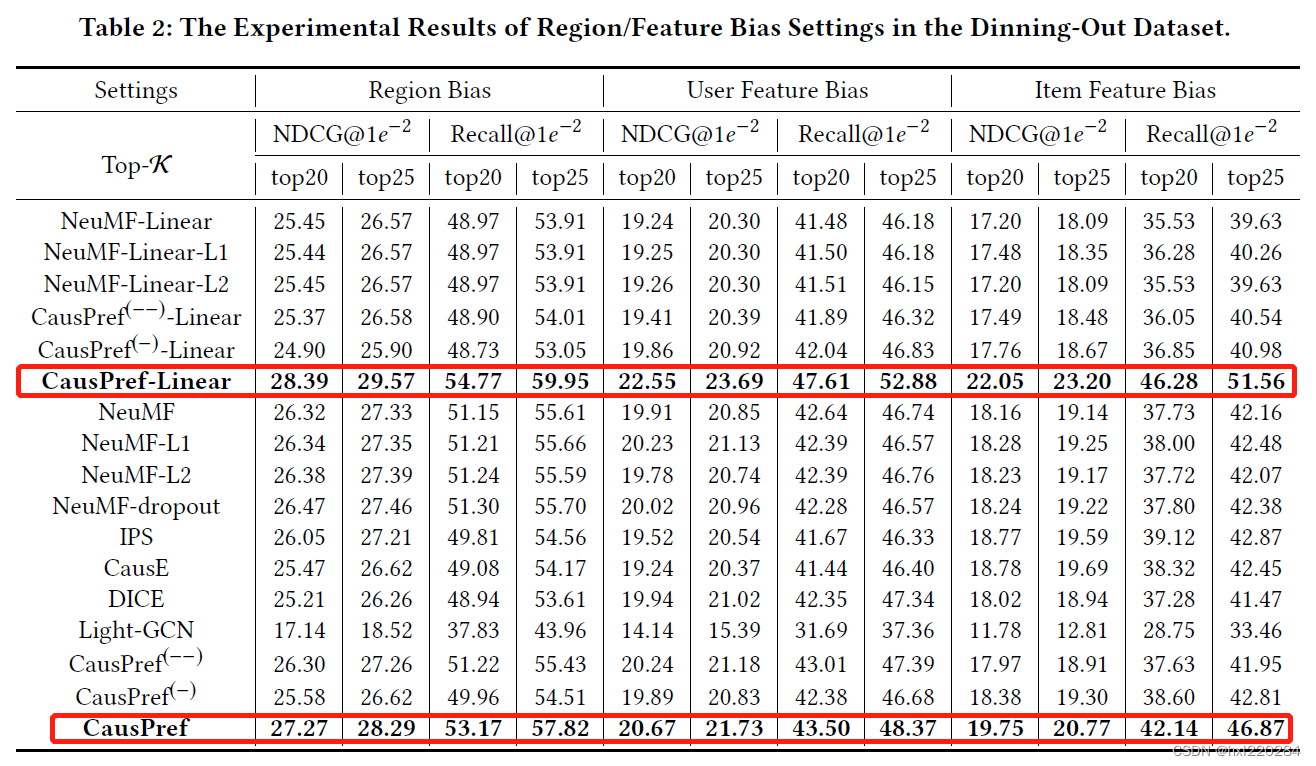
由上图可以看出在电子商务数据集上线性模型比非线性模型的效果更好。
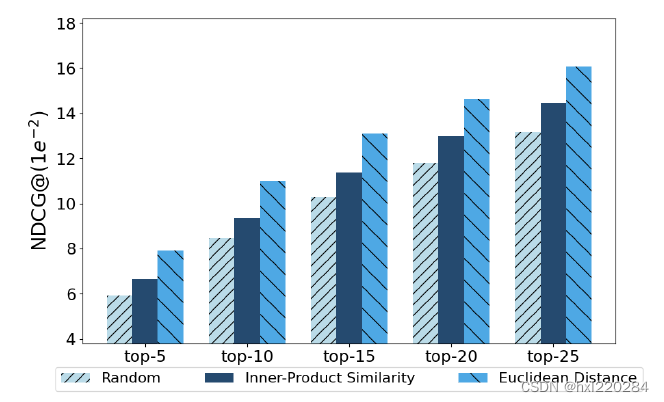
上图是比较了三种不同的负采样方法,第一种是我们常用的负采样方法,直接从未交互过的物品中随机采样,第二、三种都是基于APS算法,将算法中的 τ 1 \tau_1 τ1 替换为内积相似度度量和欧氏距离度量。从图中可以看出用APS算法进行负采样比随机负采样的效果要好,验证了APS算法的有效性。
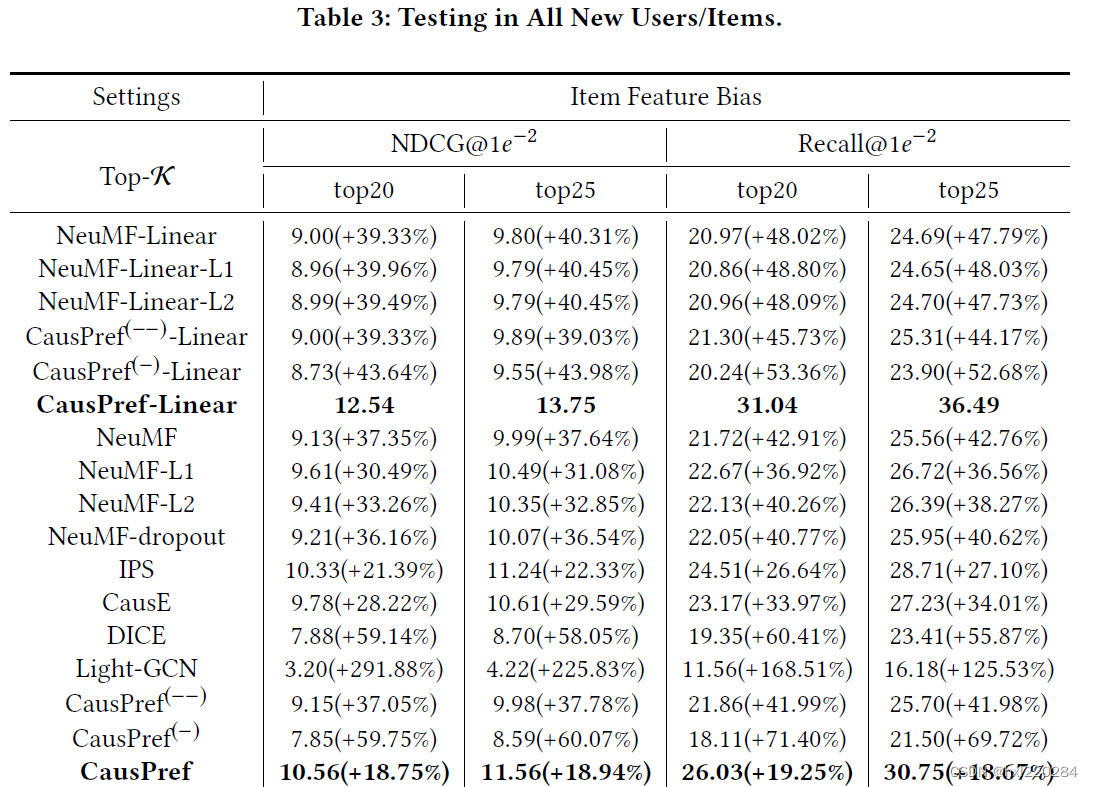
为了验证本文提出的方法可以有效缓解冷启动问题,实验将测试集的数据全部设置为新用户/新物品,从图中可以看出CausPref方法效果是最优的,进一步验证了CausPref方法的有效性。值得一提的是,SOTA方法——LightGCN对新用户和新物品的推荐性能较差。
3.4 实验:可解释推荐结构
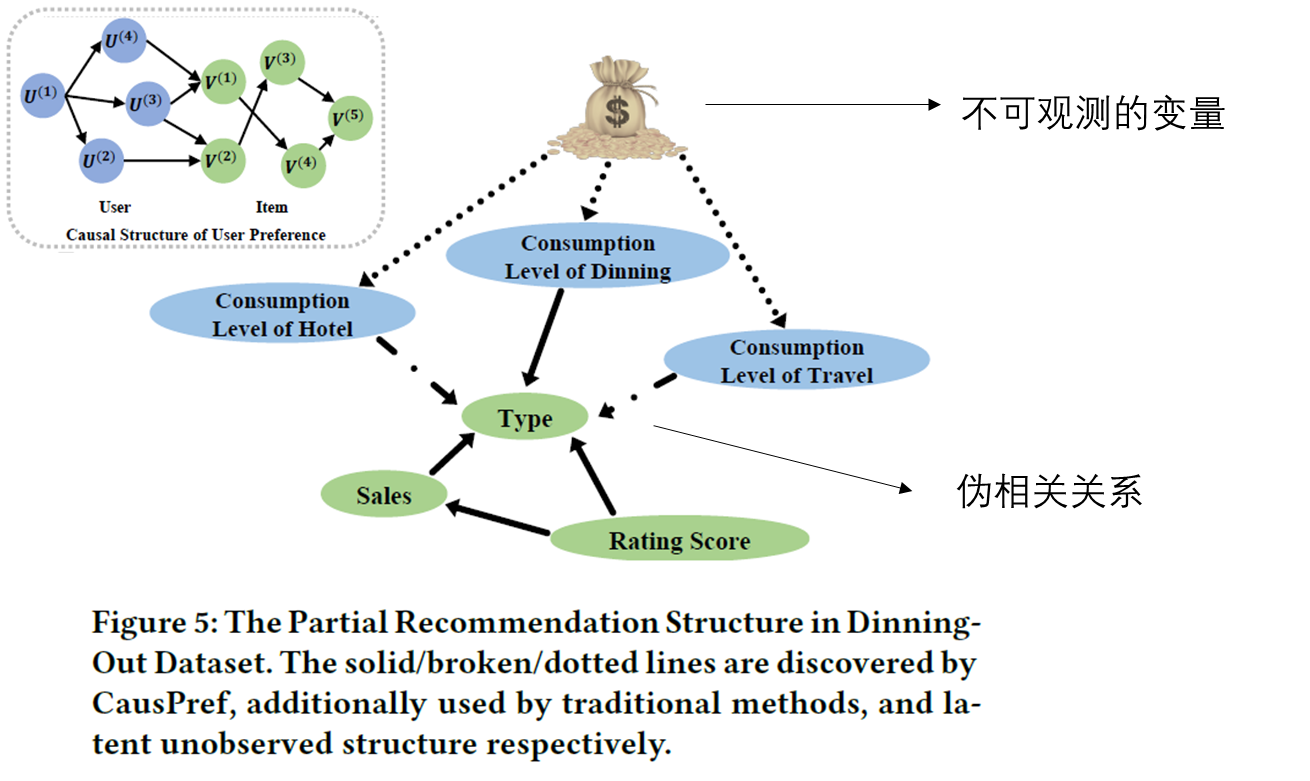
上图中长虚线的关系是传统推荐方法得出来的,这种因果关系认为用户对餐厅类别的选择受用户对旅馆和旅行的消费影响,认为旅行消费越高的用户可能也会选择更高档的餐厅。但实际情况中,可能存在有些人对旅行的质量有较高的要求,但本身经济并不富裕,因此在餐厅的选择上会选择较低廉的餐厅。从图中可以看出CausPref方法学习到了稳定的因果关系,认为用户对餐厅的选择是受用户对餐厅消费水平、餐厅的评分和餐厅的营业额影响的。
4、总结
【鲁棒性】保证了稳定的推荐性能,有效解决冷启动问题;
【负采样】利用学习到的不变的用户偏好进行负采样,能捕捉到未观察到的信号;
【可解释性】利用学习到的因果图,解释各属性之间的因果关系。















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









