








CAUSPref_Causal Preference Learning for Out-of-Distribution Recommendation
Introduction
常见的推荐方法有协同过滤[18]、基于内容的推荐[24]、混合推荐[29]等等。最近,深度神经网络DNN[2]和图卷积神经网络GCN[21]提升了推荐系统的性能。
目前大部分的推荐系统假设原始训练和测试数据是独立同分布(I.I.D)的。然而这个假设常常是与现实中的推荐情景相违背的。现实中的数据不可避免地存在分布的偏移问题。
分布的偏移问题主要来源于两个方面:
- 人类行为中人口环境、地理位置以及时间的异质性
- 推荐系统本身的机制造成的人为偏差
第一种偏差在文献中很少被研究,同时也缺乏一种统一的方法来处理这两种分布的变化。这种问题也被称为OOD问题(out-of-distribution)
implicit feedback,隐式反馈
这种问题下,我们只能获得正信号,而负信号在大部分情况下无法获得。我们无法用负反馈来描述用户-商品对的分布情况。
本文中,将推荐问题归纳为评估 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V),这里的 U U U和 V V V分代表对用户和商品的表示。 Y Y Y表示用户对商品的反馈。本文假设,真正的 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V)是不随环境变化的,虽然从训练集到测试集 P ( U , V ) P(U,V) P(U,V)会发生变化。在合理的假设下,我们从理论上证明了用户偏好的不变性是保证 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V)不变性的充分条件。因此,如何习得用户偏好的不变性成为了我们的目标。大部分的不变性学习[9, 26]都指出,反映数据产生过程的因果结构可以在典型的数据分布偏移的情况下保持不变性。但是如何习这种用户偏好的因果结构,而不是利用一种已知的因果结构来消除听特定的偏差,仍然是一种开放性问题。
受到最近在可微因果发现的启示,我们提出了一种新的有向无环图来学习推荐方法,并且将其有机地迁移到神经网络协同过滤框架中,来形成一种新的基于因果偏好的推荐框架CAUSPref。DAG(有向无环图)学习器的正则化取决于用户偏好的特性,例如,只有用户特征可能会导致项目特征,但反之则不然。我们可以使用这种学习器来学习用户偏好的因果结构。为了处理隐式反馈问题,作者设计了一种反偏好的负采样方法来使得整个框架与理论分析相吻合。作者将用户特征和项目特征纳入到框架中来适应归纳设定。因果论的内在可解释性也使得CAUSPref对于推荐的解释提供了一个附带优势。
论文的主要贡献如下:
- 作者从OOD泛化的视角理论分析了在隐式反馈下的推荐问题
- 提出了一个新颖的基于因果偏好的推荐框架,主要由不变用户偏好学习和反偏好负采样的因果学习组成,来处理隐式反馈问题。
2 问题阐述以及方法
2.1 外分布推荐
在本论文中,作者研究了分布偏移存在下的推荐问题。对于大部分的常见隐式反馈,用户-项目交互可以被表示为 ( u i , v i , y i ) (u_i,v_i,y_i) (ui,vi,yi),这里的 u i ∈ R 1 × q u u_i\in \mathbb{R}^{1\times q^u} ui∈R1×qu,是一个 q u q^u qu维度的向量,通过用户的隐特征来表示用户; v i ∈ R 1 × q v v_i\in \mathbb{R}^{1\times q^v} vi∈R1×qv为 q v q^v qv维度的向量,通过项目的隐特征来表示项目, y i = 1 / 0 y_i=1/0 yi=1/0表示能够表现用户对项目 v i v_i vi偏好的反馈。然后定义外分布隐式问题如下:
PROBLEM 1.
给定观测的训练数据 D t r a i n = { ( u i , v i , 1 ) ∣ ( u i , v i ) ∼ P ( U , V ∣ Y = 1 ) } i = 1 N D_{train}=\{(u_i,v_i,1)|(u_i,v_i)\sim P(U,V|Y=1)\}_{i=1}^{N} Dtrain={(ui,vi,1)∣(ui,vi)∼P(U,V∣Y=1)}i=1N以及测试数据 D t e s t = { ( u i ∗ , v i ∗ , y i ∗ ) ∣ ( u i ∗ , v i ∗ , y i ∗ ) ∼ P ∗ ( U , V , Y ) } i = 1 N ∗ D_{test}=\{(u_i^*,v_i^*,y_i^*)|(u_i^*,v_i^*,y_i^*)\sim P^*(U,V,Y)\}_{i=1}^{N^*} Dtest={(ui∗,vi∗,yi∗)∣(ui∗,vi∗,yi∗)∼P∗(U,V,Y)}i=1N∗,这里的 P ( U , V ) ≠ P ∗ ( U , V ) P(U,V)\neq P^*(U,V) P(U,V)=P∗(U,V), N / N ∗ N/N^* N/N∗是训练/测试数据的样本容量。外分布隐式推荐的目标是从训练分布 P ( U , V ) P(U,V) P(U,V)中习得一种推荐你系统来精确地预测测试集分布 P ∗ ( U , V ) P^*(U,V) P∗(U,V)上用户对项目的反馈。
根据Problem 1,我们仅仅可以获得分布 P ( U , V , Y ) P(U,V,Y) P(U,V,Y)上的部分信息,即正反馈 P ( U , V , Y = 1 ) P(U,V,Y=1) P(U,V,Y=1)。然后获得在 P ∗ ( U , V ) P^*(U,V) P∗(U,V)上的泛化能力。作者提出Assumption 1来支持外分布推荐。
ASSUMPTION 1.
用户-项目交互 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V)机制在不同的环境中是不变的,也就是说 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V)总是等于 P ∗ ( Y ∣ U , V ) P^*(Y|U,V) P∗(Y∣U,V),即使 P ( U , V ) ≠ P ∗ ( U , V ) P(U,V)\neq P^*(U,V) P(U,V)=P∗(U,V)
2.2 对泛化问题的理论描述
推荐方法的目标是准确地估计 P ( Y ∣ U , V ) P(Y|U,V) P(Y∣U,V)。因为Y是二元的,可以根据贝叶斯理论将其重写为:
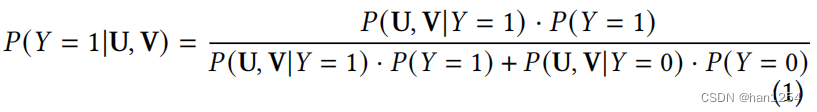
在推荐场景中,因为数据是单向的选择过程,所以上述的等式可以重写为:
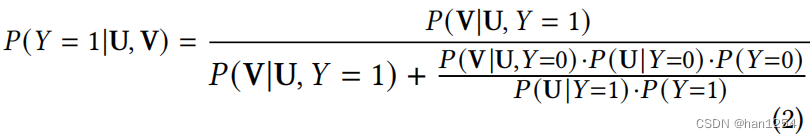
在隐式反馈中,仅仅可以观察到正反馈,因此寻找负采样方法来近似未观察项 P ( V ∣ U , Y = 0 ) ⋅ P ( U ∣ Y = 0 ) ⋅ P ( Y = 0 ) P(V|U,Y=0)\cdot P(U|Y=0)\cdot P(Y=0) P(V∣U,Y=0)⋅P(U∣Y=0)⋅P(Y=0)。通常,首先是固定一个用户 u j ∈ { u i } i = 1 N u_j\in\{u_i\}_{i=1}^N uj∈{ui}i=1N,然后基于 u j u_j uj,根据采样测量选择一个项目 v k ∈ { v i } i = 1 v_k\in \{v_i\}_{i=1} vk∈{vi}i=1。实际上,作者实验性地使用了 P ( U ∣ Y = 1 ) P(U|Y=1) P(U∣Y=1)中的样例来近似 P ( U ∣ Y = 0 ) P(U|Y=0) P(U∣Y=0),并且通过策略来模拟 P ( V ∣ U , Y = 0 ) P(V|U,Y=0) P(V∣U,Y=0)。因为 C = P ( Y = 0 ) P ( Y = 1 ) C=\frac{P(Y=0)}{P(Y=1)} C=P(Y=1)P(Y=0)是一个独立于 P ( U , V ) P(U,V) P(U,V)的常数,因此可以将等式(2)按照如下方式重写:
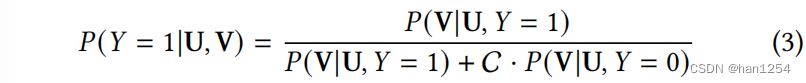
由于 P ( V ∣ U , Y = 0 ) P(V|U,Y=0) P(V∣U,Y=0)是不可知的,所以需要对 U U U、 V V V以及 Y Y Y之间的关系提出假设2:
ASSUMPTION 2.
当 P ( U , V ) P(U,V) P(U,V)发生改变时,观测数据中的 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)不变,并且可以决定在未观测分布 P ( U , V , Y = 0 ) P(U,V,Y=0) P(U,V,Y=0)中的 P ( V ∣ U , Y = 0 ) P(V|U,Y=0) P(V∣U,Y=0),即 P ( V ∣ U , Y = 0 ) = F ( P ( V ∣ U , Y = 1 ) ) P(V|U,Y=0)=\mathcal{F}(P(V|U,Y=1)) P(V∣U,Y=0)=F(P(V∣U,Y=1))。
实际上,假设2在推荐场景中也是被广泛接受的。 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)和 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)描述了用户对于项目的偏好,即用户喜欢或者不喜欢的项目分布,这两种分布的密度常常是与另一方相反。如果推荐中的所有特征都被获得,那么真实的用户偏好被认为是不变的。重写等式(3)如下:
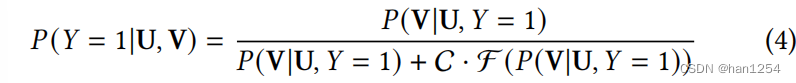
从等式(4)中可以看出,目标 P ( Y = 1 ∣ U , V ) P(Y=1|U,V) P(Y=1∣U,V)仅仅与 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)相关。因此使得我们可以通过两步来实现推荐系统的稳定性:
- 从观测数据 { ( u i , v i , 1 ) } i = 1 N \{(u_i,v_i,1)\}_{i=1}^N {(ui,vi,1)}i=1N中正确地估计用户不变偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)。
- 从正样本中估计最终目标 P ( Y = 1 ∣ U , V ) P(Y=1|U,V) P(Y=1∣U,V),然后使用策略 F ( P ( V ∣ U , Y = 1 ) ) \mathcal{F}(P(V|U,Y=1)) F(P(V∣U,Y=1))来选择负样本。
然而,这种范式被传统推荐模型框架忽视了。它们并没有发现用户偏好不变机制,即 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)的重要性,并且它们的负采样策略与 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)也是独立的,大都是随机采样,这导致了它们在分布偏移的测试环境中的糟糕表现。本文中,作者使用了一个新的基于因果偏好的推荐框架CAUSPref,将两个关键点共同考虑。CAUSPref对 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)基于可获得的特征对 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)进行建模,并且以一种因果正则化的方式学习它。
2.3 因果偏好学习
首先,重温一下不变因果结构学习的细节。使 X = [ X 1 , ⋯ , X D ] X=[X_1,\cdots, X_D] X=[X1,⋯,XD]表示 N × D N\times D N×D维的输入数据矩阵,矩阵是从联合分布 P ( X 1 , ⋯ , X D ) P(X_1,\cdots,X_D) P(X1,⋯,XD)中进行采样的,该分布是从一个含有 D D D个节点 { X 1 , ⋯ , X D } \{X_1,\cdots, X_D\} {X1,⋯,XD}的有向无环图DAG A A A中生成的。然后,可微方法学习矩阵 A ^ \hat{A} A^来近似 A A A,最小化一个泛化的目标函数:
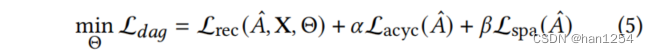
这里的 Θ \Theta Θ表示可学习的模型 g g g的参数集, L r e c \mathcal{L}_{rec} Lrec代表 g g g基于 A ^ \hat{A} A^来覆盖观测数据 X X X的能力, L a c y c \mathcal{L}_{acyc} Lacyc是一个连续可优化的无环性限制,并且最小化 L s p a \mathcal{L}_{spa} Lspa来保证 A ^ \hat{A} A^的稀疏性。
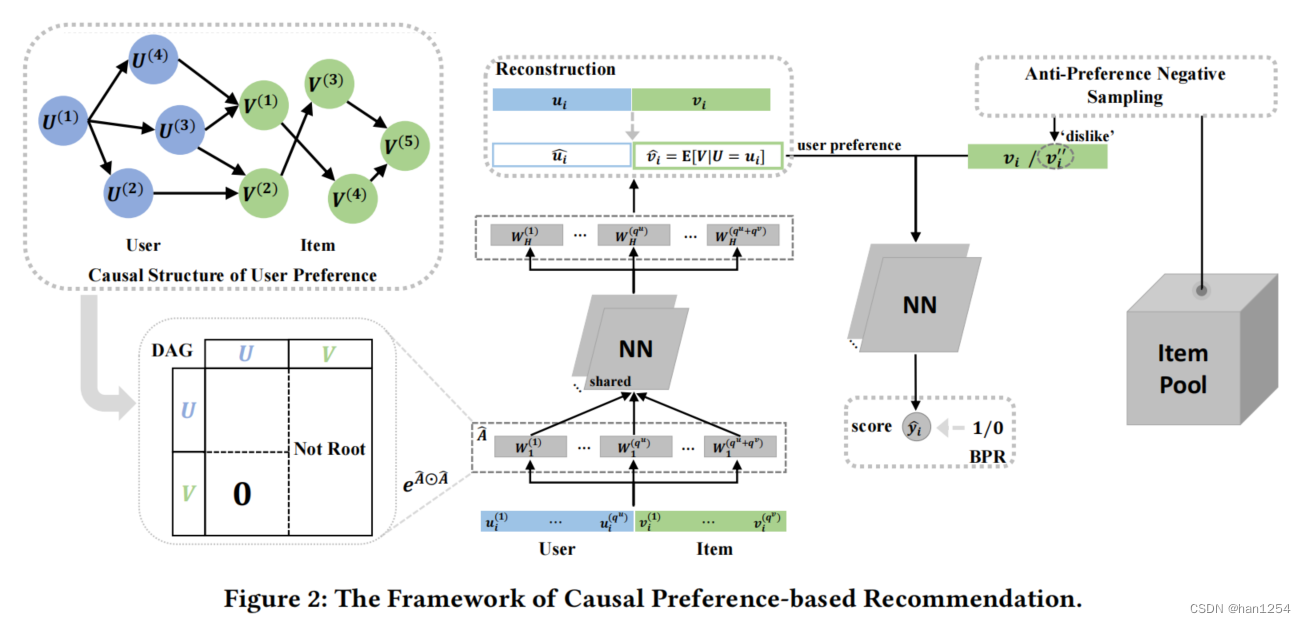
为了实现DAG模型与数据的一致性,作者设计了一个数据重构模块。设置了一系列网络 g Θ = { g ( d ) } d = 1 D g_{\Theta}=\{g^{(d)}\}_{d=1}^D gΘ={g(d)}d=1D,每一个负责重构 X X X中的一个元素。重构的细节在图二中。如图二所示,作者让 W 1 = { W 1 ( d ) ∈ R D × M } d = 1 D W_1=\{W_1^{(d)}\in \mathbb{R}^{D\times M}\}_{d=1}^D W1={W1(d)∈RD×M}d=1D表示输入输入层的权重矩阵集, { W h ∈ R N × M } h = 2 H − 1 \{W_h\in \mathbb{R}^{N\times M}\}_{h=2}^{H-1} {Wh∈RN×M}h=2H−1表示所有子网络的中间隐藏层共享权重矩阵, W H = { W H ( d ) ∈ R M × 1 } d = 1 D W_H=\{W_H^{(d)}\in \mathbb{R}^{M\times 1}\}_{d=1}^D WH={WH(d)∈RM×1}d=1D表示输出层的权重矩阵。每个 g ( d ) g^{(d)} g(d)都被设计用来预测变量 X d X_d Xd(等式6中),我们强制 W 1 ( d ) W_1^{(d)} W1(d)第 d d d维为0,即特征 X d X_d Xd被丢弃(不通过 X d X_d Xd来预测其自己)。
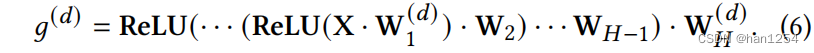
损失构建为 L r e c N = 1 N ∣ ∣ X − g Θ ( X ) ∣ ∣ F 2 \mathcal{L}_{rec}^N=\frac{1}{N}\vert\vert X-g_{\Theta}(X)\vert\vert_{F}^2 LrecN=N1∣∣X−gΘ(X)∣∣F2。
为了保证模型的矩阵 A ^ \hat{A} A^是一个DAG,其中 A ^ k , d \hat{A}_{k,d} A^k,d是 W 1 ( d ) W_1^{(d)} W1(d)的第k行的l2范数,需要限制 t r ( e A ^ ∘ A ^ ) − d = 0 tr(e^{\hat{A}\circ \hat{A}}) - d=0 tr(eA^∘A^)−d=0[45],因此,设置 L a y a = ( t r ( e A ^ ∘ A ^ ) − d ) 2 \mathcal{L}_{aya}=(tr(e^{\hat{A} \circ\hat{A}})-d)^2 Laya=(tr(eA^∘A^)−d)2,并且尝试最小化它。
为了避免 A ^ \hat{A} A^的稀疏性,作者提出最小化矩阵 W 1 W_1 W1的L1范数。
总结,将全部的损失 L d a g \mathcal{L}_{dag} Ldag项推导为:
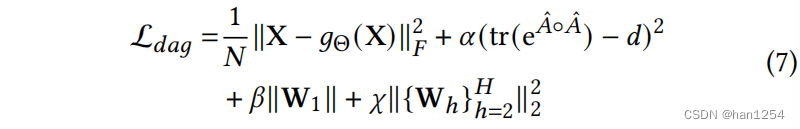
这里的 ∣ ∣ ⋅ ∣ ∣ F \vert\vert \cdot \vert\vert_F ∣∣⋅∣∣F是Febenius范数。
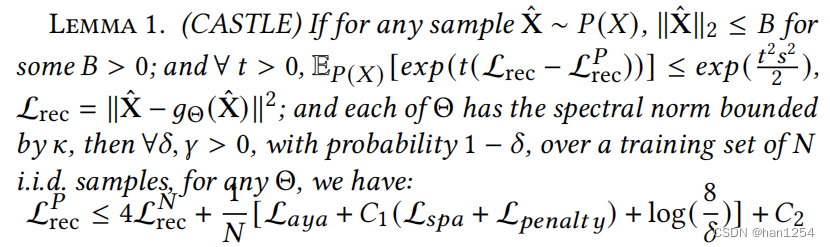
引论一指出,等式七的一个较低的实验损失意味着习得的模型与真实的因果DAG更加相近。换句话说,如果存在一个底层描述数据产生过程的因果DAG,那么该DAG正则化器可以帮助模型基于DAG描述的不变机制[9]来产生预测。
受引理一的启发,我们可以利用DAG正则化器来帮助学习不变用户偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)以及从稀疏观测样例 { ( u i , v i , 1 ) } i = 1 N \{(u_i,v_i,1)\}_{i=1}^N {(ui,vi,1)}i=1N中获得因果结构。
首先在用户和项目特征的层次上定义一个用户偏好的因果结构,描述用户喜欢的项目类别。与通常的因果图不同,特定推荐的因果图拥有以下两个额外特性:
C1: 只存在从用户特征到项目特征之间的路径
C2: 任何项目的特征都不是根节点
这两点也是符合人类直觉以及推荐场景的特性的。此外,由于使用的是每个特征的语义,可以直接使用该图来解释推荐的过程。
为了使用DAG正则化器习得用户不变偏好,集中矩阵 A ^ ( [ 1 : q u ] \hat{A}([1:q_u] A^([1:qu]中所有的特征来指示用户,以及 [ q u + 1 : q u + q v ] [q_{u+1}:q_u+q_v] [qu+1:qu+qv]指示项目 ) ) )里的特征,并对它们进行因果结构的学习。为了适应特定推荐性质,来改善推荐进程,作者在 L d a g \mathcal{L}_{dag} Ldag中增加了两个新的项:
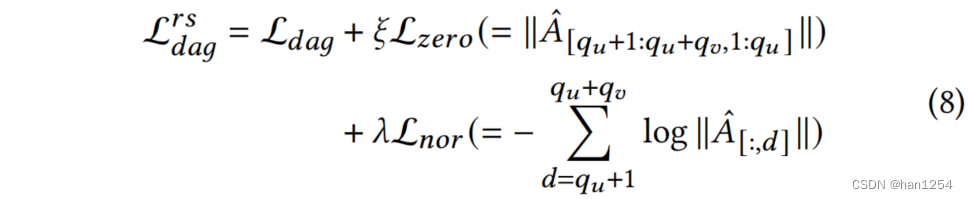
这里的 ξ \xi ξ是一个大常数,保证 L z e r o = 0 \mathcal{L}_{zero}=0 Lzero=0,这意味着没有从项目到用户的路径,以及 L n o r \mathcal{L}_{nor} Lnor,在不损害全局稀疏性的情况下强制执行无根约束,只需要保证所有项目特征具有非零入度即可。
训练之后,沿着DAG中的有向路径,如果输入一个用户特征 u i u_i ui,那么输出 g ^ Θ ( [ u i ] ) = g Θ ( [ u i ∣ 0 ] ) [ : , q u + 1 : q u + q ] \hat{g}_{\Theta}([u_i])=g_{\Theta}([u_i|0])_{[:,q_{u+1}:q_{u+q}]} g^Θ([ui])=gΘ([ui∣0])[:,qu+1:qu+q]表示对于用户 u i u_i ui的真实偏好的期望,即 g ^ Θ ( [ u i ] ) = E ( V ∣ U = u i , Y = 1 ) \hat{g}_{\Theta}([u_i])=\mathbb{E}(V|U=u_i,Y=1) g^Θ([ui])=E(V∣U=ui,Y=1)。
2.4 基于因果偏好的推荐
本文利用了对不变偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)的估计来学习预测评分 P ( Y = 1 ∣ U , V ) P(Y=1|U,V) P(Y=1∣U,V)。根据上述提出的结构,首先的任务是基于 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)设计一个负采样策略。这里,作者提出了一个简单却有效的策略,如算法一所示。

在选择了用户 u i u_i ui之后,首先计算用户的偏好期望 E ( V ∣ U = u i , Y = 1 ) \mathbb{E}(V|U=u_i,Y=1) E(V∣U=ui,Y=1),然后计算偏好向量和其他项目之间的相似度(距离函数 τ 1 \tau_1 τ1,例如欧氏距离),然后选择一个相似度最小的项目 v j v_j vj。考录到计算效率问题,首先从整个项目池子中随机选择 K K K个项目作为候选集合,然后在候选集上进行项目选择。用户 u i u_i ui和 v j v_j vj项目对构成了负样本。
当给定了观测数据中的正样本 ( u i , v i ) (u_i,v_i) (ui,vi)以及APS(算法一)选择的负样本 ( u i , v j ) (u_i,v_j) (ui,vj)之后,就可以使用它们去训练模型 μ \mu μ(参数集合为 Φ \Phi Φ),输出预测得分 P ( Y = 1 ∣ U , V ) P(Y=1|U,V) P(Y=1∣U,V)进行排序。这里选择了神经协同过滤框架作为预测器,并且在等式九中采取了常用的贝叶斯个性化排序(BPR)[28]损失来进行优化。BPR损失使用正负样本对来作为输入,并且鼓励一个观测实体的输出分数比未观测的另一方高。
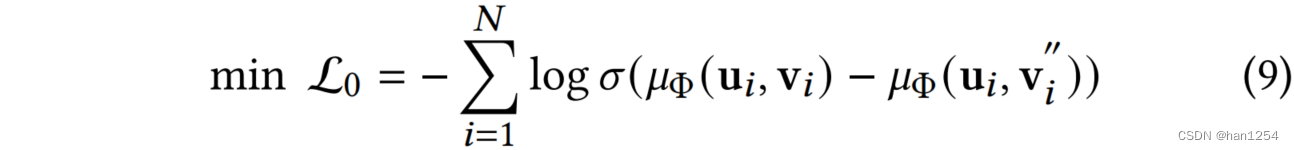
为了在评分预测器中利用习得的不变用户偏好 P ( V ∣ U , Y = 1 ) P(V|U,Y=1) P(V∣U,Y=1)的优点,作者直接将原始的用户特征替换成习得的用户偏好期望 E ( V ∣ U = u i , Y = 1 ) \mathbb{E}(V|U=u_i,Y=1) E(V∣U=ui,Y=1),作为预测器 μ \mu μ的输入。最终,将不变偏好和估计分数结合,来学习一个统一的基于因果偏好的推荐框架。
如图二所示,给定一个正样本 ( u i , v i ) (u_i,v_i) (ui,vi),在通过 g θ g_{\theta} gθ计算 E ( V ∣ U = u i , Y = 1 ) \mathbb{E}(V|U=u_i,Y=1) E(V∣U=ui,Y=1)之后,使用APS选择 v j v_j vj作为负样本。通过堆叠的神经网络层,获得两个样本的预测分数。对于正样本 ( u i , v i ) (u_i,v_i) (ui,vi),同时最小化DAG学习损失 L d a g r s \mathcal{L}^{rs}_{dag} Ldagrs以及BPR损失。负样本 ( u i , v j ) (u_i,v_j) (ui,vj),仅仅最小化BPR损失。注意到BPR损失的反向传播梯度也会优化DAG学习器的参数 Θ \Theta Θ,因为其可以提供更多的监督信号来在推荐场景中找到真实的因果结构,并且帮助改进训练。最终,联合优化 Θ \Theta Θ和 Φ \Phi Φ来最小化等式十中的目标函数:
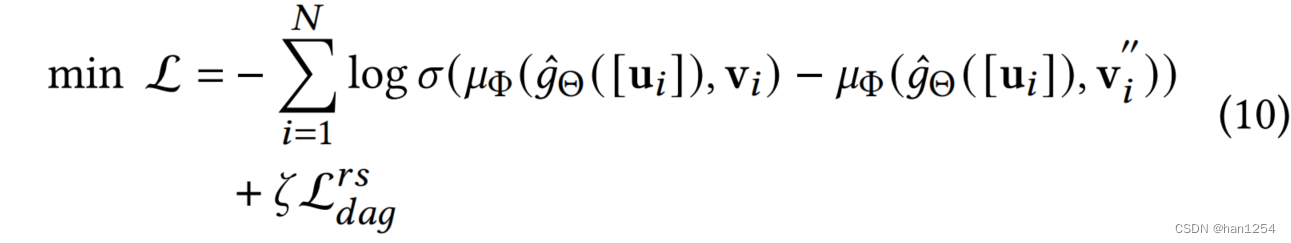















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









